 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePodEval: A Multimodal Evaluation Framework for Podcast Audio Generation
Oct 01, 2025Recently, an increasing number of multimodal (text and audio) benchmarks have emerged, primarily focusing on evaluating models' understanding capability. However, exploration into assessing generative capabilities remains limited, especially for open-ended long-form content generation. Significant challenges lie in no reference standard answer, no unified evaluation metrics and uncontrollable human judgments. In this work, we take podcast-like audio generation as a starting point and propose PodEval, a comprehensive and well-designed open-source evaluation framework. In this framework: 1) We construct a real-world podcast dataset spanning diverse topics, serving as a reference for human-level creative quality. 2) We introduce a multimodal evaluation strategy and decompose the complex task into three dimensions: text, speech and audio, with different evaluation emphasis on "Content" and "Format". 3) For each modality, we design corresponding evaluation methods, involving both objective metrics and subjective listening test. We leverage representative podcast generation systems (including open-source, close-source, and human-made) in our experiments. The results offer in-depth analysis and insights into podcast generation, demonstrating the effectiveness of PodEval in evaluating open-ended long-form audio. This project is open-source to facilitate public use: https://github.com/yujxx/PodEval.
StyleSpeech: Self-supervised Style Enhancing with VQ-VAE-based Pre-training for Expressive Audiobook Speech Synthesis
Dec 19, 2023



The expressive quality of synthesized speech for audiobooks is limited by generalized model architecture and unbalanced style distribution in the training data. To address these issues, in this paper, we propose a self-supervised style enhancing method with VQ-VAE-based pre-training for expressive audiobook speech synthesis. Firstly, a text style encoder is pre-trained with a large amount of unlabeled text-only data. Secondly, a spectrogram style extractor based on VQ-VAE is pre-trained in a self-supervised manner, with plenty of audio data that covers complex style variations. Then a novel architecture with two encoder-decoder paths is specially designed to model the pronunciation and high-level style expressiveness respectively, with the guidance of the style extractor. Both objective and subjective evaluations demonstrate that our proposed method can effectively improve the naturalness and expressiveness of the synthesized speech in audiobook synthesis especially for the role and out-of-domain scenarios.
MuLanTTS: The Microsoft Speech Synthesis System for Blizzard Challenge 2023
Sep 12, 2023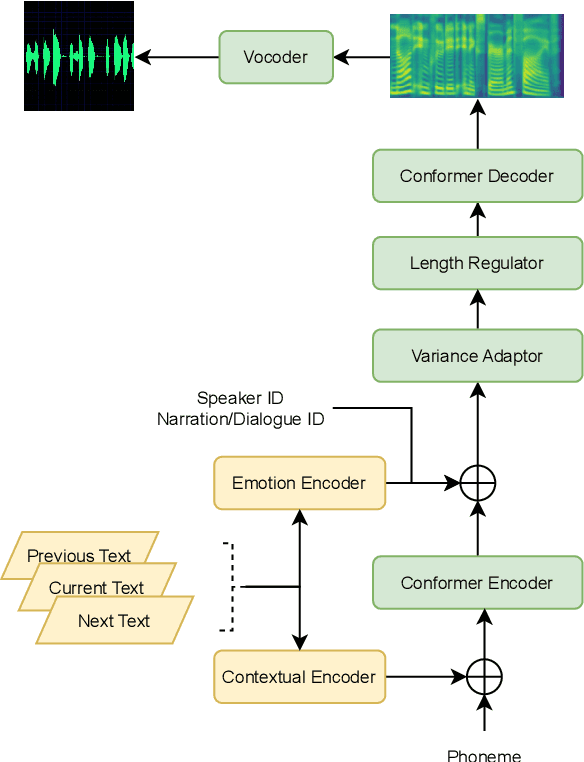
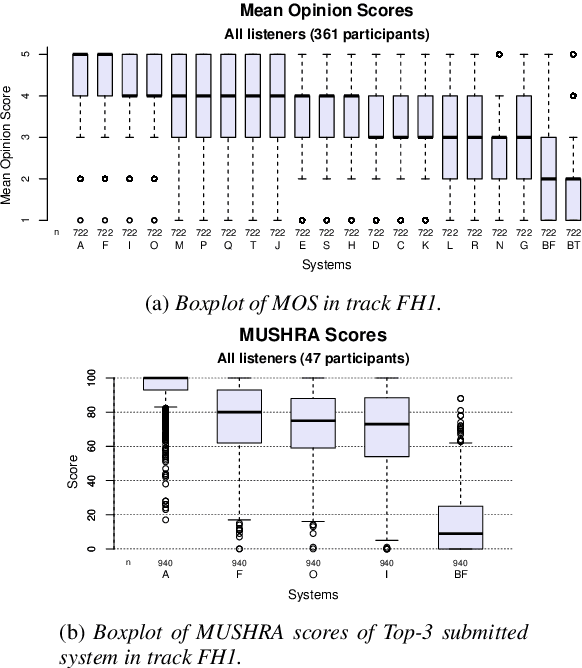
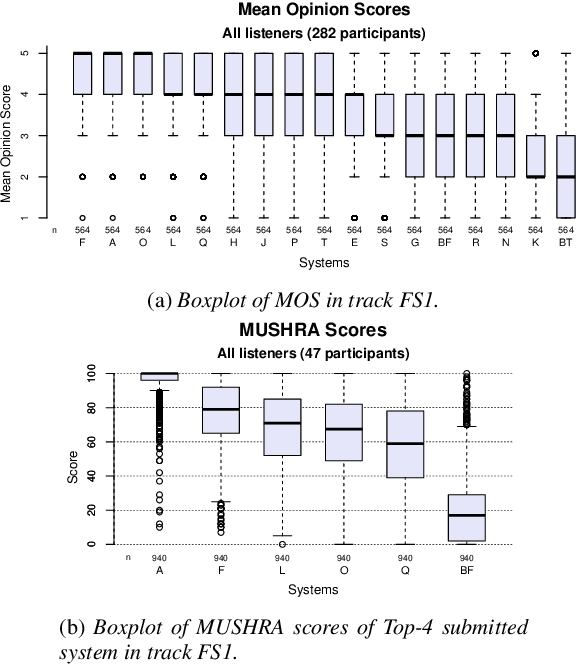
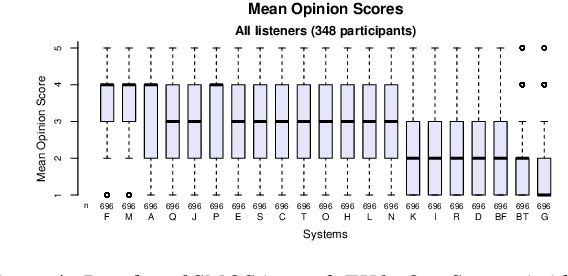
In this paper, we present MuLanTTS, the Microsoft end-to-end neural text-to-speech (TTS) system designed for the Blizzard Challenge 2023. About 50 hours of audiobook corpus for French TTS as hub task and another 2 hours of speaker adaptation as spoke task are released to build synthesized voices for different test purposes including sentences, paragraphs, homographs, lists, etc. Building upon DelightfulTTS, we adopt contextual and emotion encoders to adapt the audiobook data to enrich beyond sentences for long-form prosody and dialogue expressiveness. Regarding the recording quality, we also apply denoise algorithms and long audio processing for both corpora. For the hub task, only the 50-hour single speaker data is used for building the TTS system, while for the spoke task, a multi-speaker source model is used for target speaker fine tuning. MuLanTTS achieves mean scores of quality assessment 4.3 and 4.5 in the respective tasks, statistically comparable with natural speech while keeping good similarity according to similarity assessment. The excellent and similarity in this year's new and dense statistical evaluation show the effectiveness of our proposed system in both tasks.
Large-Scale Automatic Audiobook Creation
Sep 07, 2023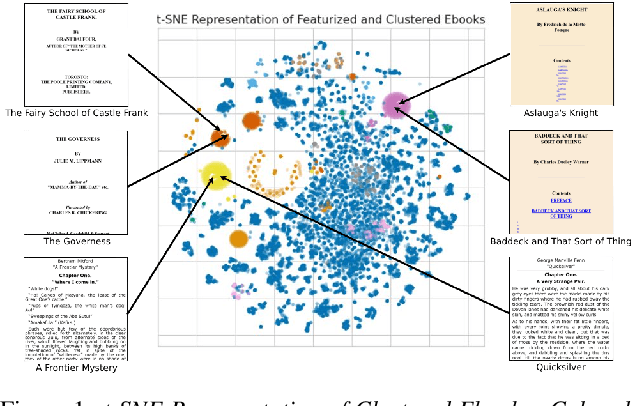
An audiobook can dramatically improve a work of literature's accessibility and improve reader engagement. However, audiobooks can take hundreds of hours of human effort to create, edit, and publish. In this work, we present a system that can automatically generate high-quality audiobooks from online e-books. In particular, we leverage recent advances in neural text-to-speech to create and release thousands of human-quality, open-license audiobooks from the Project Gutenberg e-book collection. Our method can identify the proper subset of e-book content to read for a wide collection of diversely structured books and can operate on hundreds of books in parallel. Our system allows users to customize an audiobook's speaking speed and style, emotional intonation, and can even match a desired voice using a small amount of sample audio. This work contributed over five thousand open-license audiobooks and an interactive demo that allows users to quickly create their own customized audiobooks. To listen to the audiobook collection visit \url{https://aka.ms/audiobook}.
ContextSpeech: Expressive and Efficient Text-to-Speech for Paragraph Reading
Jul 03, 2023While state-of-the-art Text-to-Speech systems can generate natural speech of very high quality at sentence level, they still meet great challenges in speech generation for paragraph / long-form reading. Such deficiencies are due to i) ignorance of cross-sentence contextual information, and ii) high computation and memory cost for long-form synthesis. To address these issues, this work develops a lightweight yet effective TTS system, ContextSpeech. Specifically, we first design a memory-cached recurrence mechanism to incorporate global text and speech context into sentence encoding. Then we construct hierarchically-structured textual semantics to broaden the scope for global context enhancement. Additionally, we integrate linearized self-attention to improve model efficiency. Experiments show that ContextSpeech significantly improves the voice quality and prosody expressiveness in paragraph reading with competitive model efficiency. Audio samples are available at: https://contextspeech.github.io/demo/
ParaTTS: Learning Linguistic and Prosodic Cross-sentence Information in Paragraph-based TTS
Sep 14, 2022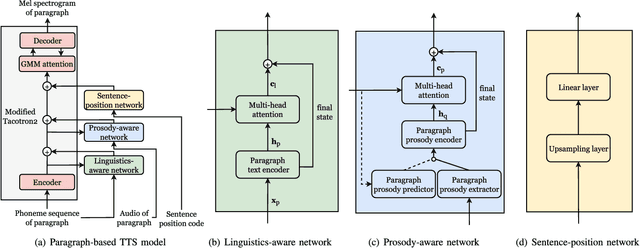

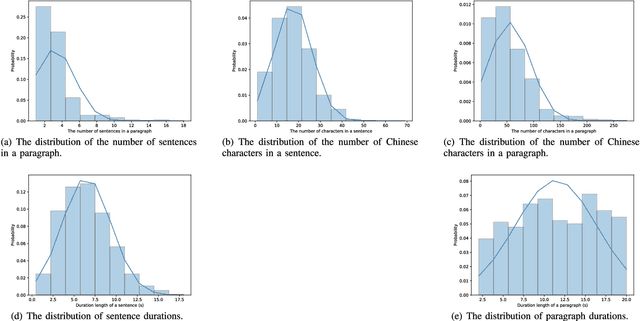

Recent advancements in neural end-to-end TTS models have shown high-quality, natural synthesized speech in a conventional sentence-based TTS. However, it is still challenging to reproduce similar high quality when a whole paragraph is considered in TTS, where a large amount of contextual information needs to be considered in building a paragraph-based TTS model. To alleviate the difficulty in training, we propose to model linguistic and prosodic information by considering cross-sentence, embedded structure in training. Three sub-modules, including linguistics-aware, prosody-aware and sentence-position networks, are trained together with a modified Tacotron2. Specifically, to learn the information embedded in a paragraph and the relations among the corresponding component sentences, we utilize linguistics-aware and prosody-aware networks. The information in a paragraph is captured by encoders and the inter-sentence information in a paragraph is learned with multi-head attention mechanisms. The relative sentence position in a paragraph is explicitly exploited by a sentence-position network. Trained on a storytelling audio-book corpus (4.08 hours), recorded by a female Mandarin Chinese speaker, the proposed TTS model demonstrates that it can produce rather natural and good-quality speech paragraph-wise. The cross-sentence contextual information, such as break and prosodic variations between consecutive sentences, can be better predicted and rendered than the sentence-based model. Tested on paragraph texts, of which the lengths are similar to, longer than, or much longer than the typical paragraph length of the training data, the TTS speech produced by the new model is consistently preferred over the sentence-based model in subjective tests and confirmed in objective measures.
Self-supervised Context-aware Style Representation for Expressive Speech Synthesis
Jun 25, 2022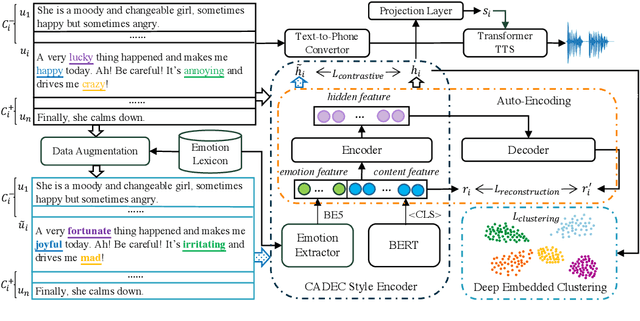



Expressive speech synthesis, like audiobook synthesis, is still challenging for style representation learning and prediction. Deriving from reference audio or predicting style tags from text requires a huge amount of labeled data, which is costly to acquire and difficult to define and annotate accurately. In this paper, we propose a novel framework for learning style representation from abundant plain text in a self-supervised manner. It leverages an emotion lexicon and uses contrastive learning and deep clustering. We further integrate the style representation as a conditioned embedding in a multi-style Transformer TTS. Comparing with multi-style TTS by predicting style tags trained on the same dataset but with human annotations, our method achieves improved results according to subjective evaluations on both in-domain and out-of-domain test sets in audiobook speech. Moreover, with implicit context-aware style representation, the emotion transition of synthesized audio in a long paragraph appears more natural. The audio samples are available on the demo web.