 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Mar 08, 2024In this report, we present the latest model of the Gemini family, Gemini 1.5 Pro, a highly compute-efficient multimodal mixture-of-experts model capable of recalling and reasoning over fine-grained information from millions of tokens of context, including multiple long documents and hours of video and audio. Gemini 1.5 Pro achieves near-perfect recall on long-context retrieval tasks across modalities, improves the state-of-the-art in long-document QA, long-video QA and long-context ASR, and matches or surpasses Gemini 1.0 Ultra's state-of-the-art performance across a broad set of benchmarks. Studying the limits of Gemini 1.5 Pro's long-context ability, we find continued improvement in next-token prediction and near-perfect retrieval (>99%) up to at least 10M tokens, a generational leap over existing models such as Claude 2.1 (200k) and GPT-4 Turbo (128k). Finally, we highlight surprising new capabilities of large language models at the frontier; when given a grammar manual for Kalamang, a language with fewer than 200 speakers worldwide, the model learns to translate English to Kalamang at a similar level to a person who learned from the same content.
GIVT: Generative Infinite-Vocabulary Transformers
Dec 04, 2023



We introduce generative infinite-vocabulary transformers (GIVT) which generate vector sequences with real-valued entries, instead of discrete tokens from a finite vocabulary. To this end, we propose two surprisingly simple modifications to decoder-only transformers: 1) at the input, we replace the finite-vocabulary lookup table with a linear projection of the input vectors; and 2) at the output, we replace the logits prediction (usually mapped to a categorical distribution) with the parameters of a multivariate Gaussian mixture model. Inspired by the image-generation paradigm of VQ-GAN and MaskGIT, where transformers are used to model the discrete latent sequences of a VQ-VAE, we use GIVT to model the unquantized real-valued latent sequences of a VAE. When applying GIVT to class-conditional image generation with iterative masked modeling, we show competitive results with MaskGIT, while our approach outperforms both VQ-GAN and MaskGIT when using it for causal modeling. Finally, we obtain competitive results outside of image generation when applying our approach to panoptic segmentation and depth estimation with a VAE-based variant of the UViM framework.
Finite Scalar Quantization: VQ-VAE Made Simple
Oct 12, 2023



We propose to replace vector quantization (VQ) in the latent representation of VQ-VAEs with a simple scheme termed finite scalar quantization (FSQ), where we project the VAE representation down to a few dimensions (typically less than 10). Each dimension is quantized to a small set of fixed values, leading to an (implicit) codebook given by the product of these sets. By appropriately choosing the number of dimensions and values each dimension can take, we obtain the same codebook size as in VQ. On top of such discrete representations, we can train the same models that have been trained on VQ-VAE representations. For example, autoregressive and masked transformer models for image generation, multimodal generation, and dense prediction computer vision tasks. Concretely, we employ FSQ with MaskGIT for image generation, and with UViM for depth estimation, colorization, and panoptic segmentation. Despite the much simpler design of FSQ, we obtain competitive performance in all these tasks. We emphasize that FSQ does not suffer from codebook collapse and does not need the complex machinery employed in VQ (commitment losses, codebook reseeding, code splitting, entropy penalties, etc.) to learn expressive discrete representations.
High-Fidelity Image Compression with Score-based Generative Models
May 26, 2023



Despite the tremendous success of diffusion generative models in text-to-image generation, replicating this success in the domain of image compression has proven difficult. In this paper, we demonstrate that diffusion can significantly improve perceptual quality at a given bit-rate, outperforming state-of-the-art approaches PO-ELIC and HiFiC as measured by FID score. This is achieved using a simple but theoretically motivated two-stage approach combining an autoencoder targeting MSE followed by a further score-based decoder. However, as we will show, implementation details matter and the optimal design decisions can differ greatly from typical text-to-image models.
M2T: Masking Transformers Twice for Faster Decoding
Apr 14, 2023We show how bidirectional transformers trained for masked token prediction can be applied to neural image compression to achieve state-of-the-art results. Such models were previously used for image generation by progressivly sampling groups of masked tokens according to uncertainty-adaptive schedules. Unlike these works, we demonstrate that predefined, deterministic schedules perform as well or better for image compression. This insight allows us to use masked attention during training in addition to masked inputs, and activation caching during inference, to significantly speed up our models (~4 higher inference speed) at a small increase in bitrate.
Multi-Realism Image Compression with a Conditional Generator
Dec 28, 2022By optimizing the rate-distortion-realism trade-off, generative compression approaches produce detailed, realistic images, even at low bit rates, instead of the blurry reconstructions produced by rate-distortion optimized models. However, previous methods do not explicitly control how much detail is synthesized, which results in a common criticism of these methods: users might be worried that a misleading reconstruction far from the input image is generated. In this work, we alleviate these concerns by training a decoder that can bridge the two regimes and navigate the distortion-realism trade-off. From a single compressed representation, the receiver can decide to either reconstruct a low mean squared error reconstruction that is close to the input, a realistic reconstruction with high perceptual quality, or anything in between. With our method, we set a new state-of-the-art in distortion-realism, pushing the frontier of achievable distortion-realism pairs, i.e., our method achieves better distortions at high realism and better realism at low distortion than ever before.
Lossy Compression with Gaussian Diffusion
Jun 17, 2022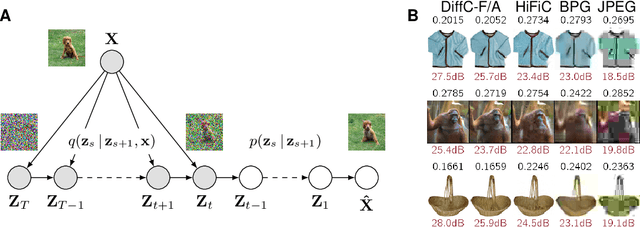
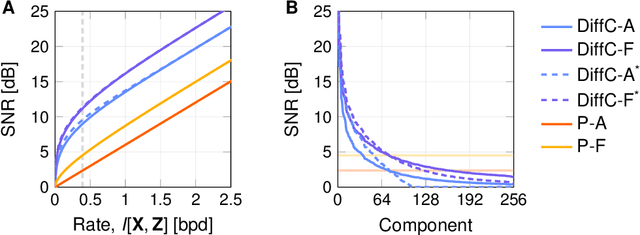
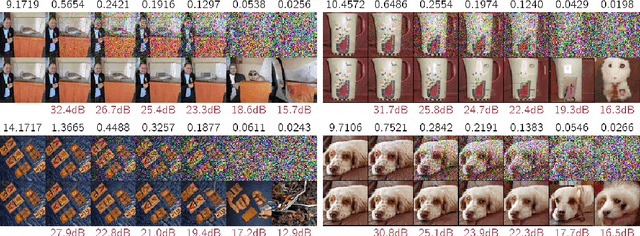
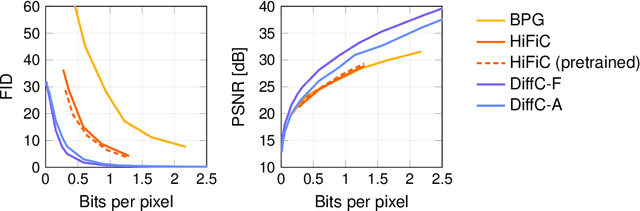
We describe a novel lossy compression approach called DiffC which is based on unconditional diffusion generative models. Unlike modern compression schemes which rely on transform coding and quantization to restrict the transmitted information, DiffC relies on the efficient communication of pixels corrupted by Gaussian noise. We implement a proof of concept and find that it works surprisingly well despite the lack of an encoder transform, outperforming the state-of-the-art generative compression method HiFiC on ImageNet 64x64. DiffC only uses a single model to encode and denoise corrupted pixels at arbitrary bitrates. The approach further provides support for progressive coding, that is, decoding from partial bit streams. We perform a rate-distortion analysis to gain a deeper understanding of its performance, providing analytical results for multivariate Gaussian data as well as initial results for general distributions. Furthermore, we show that a flow-based reconstruction achieves a 3 dB gain over ancestral sampling at high bitrates.
VCT: A Video Compression Transformer
Jun 15, 2022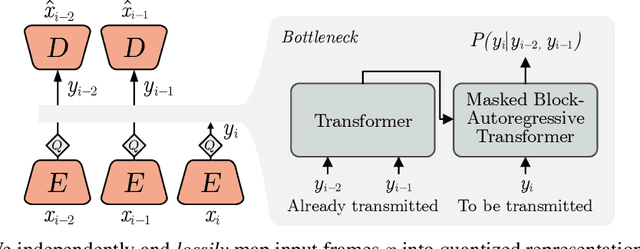

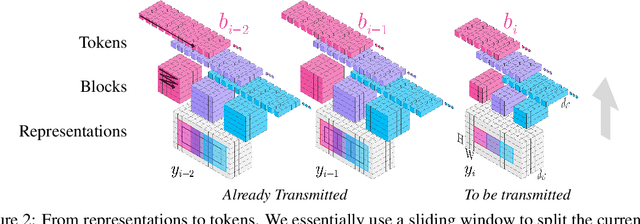
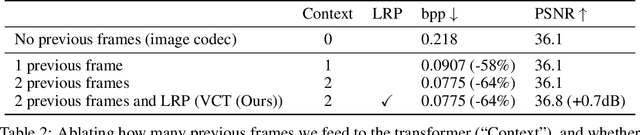
We show how transformers can be used to vastly simplify neural video compression. Previous methods have been relying on an increasing number of architectural biases and priors, including motion prediction and warping operations, resulting in complex models. Instead, we independently map input frames to representations and use a transformer to model their dependencies, letting it predict the distribution of future representations given the past. The resulting video compression transformer outperforms previous methods on standard video compression data sets. Experiments on synthetic data show that our model learns to handle complex motion patterns such as panning, blurring and fading purely from data. Our approach is easy to implement, and we release code to facilitate future research.
Towards Generative Video Compression
Jul 26, 2021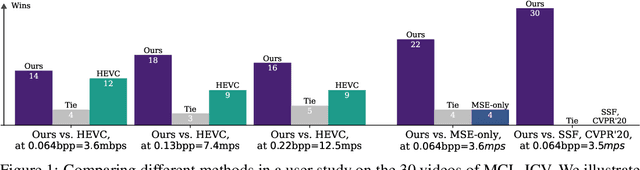
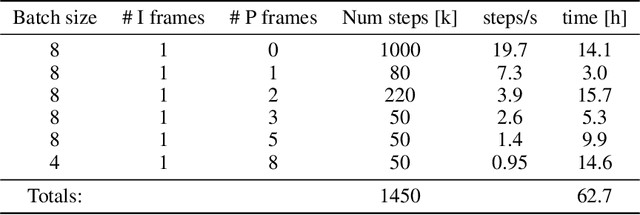
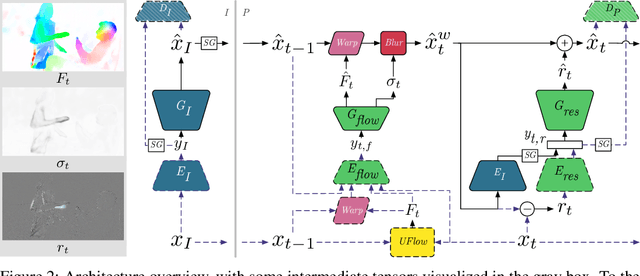
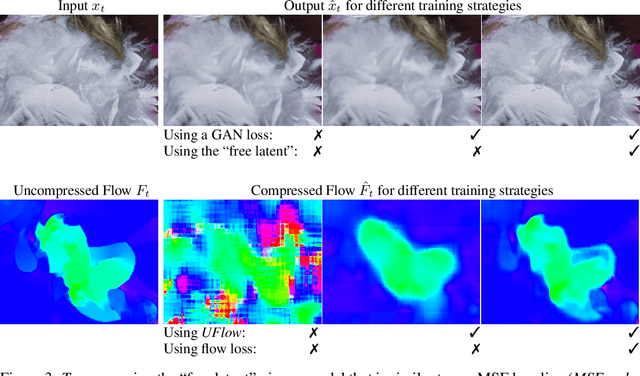
We present a neural video compression method based on generative adversarial networks (GANs) that outperforms previous neural video compression methods and is comparable to HEVC in a user study. We propose a technique to mitigate temporal error accumulation caused by recursive frame compression that uses randomized shifting and un-shifting, motivated by a spectral analysis. We present in detail the network design choices, their relative importance, and elaborate on the challenges of evaluating video compression methods in user studies.
High-Fidelity Generative Image Compression
Jul 10, 2020

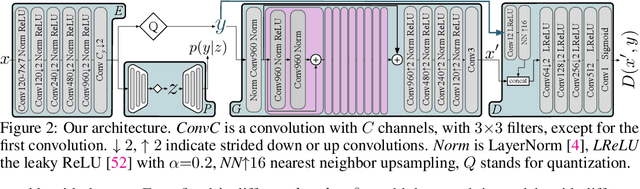
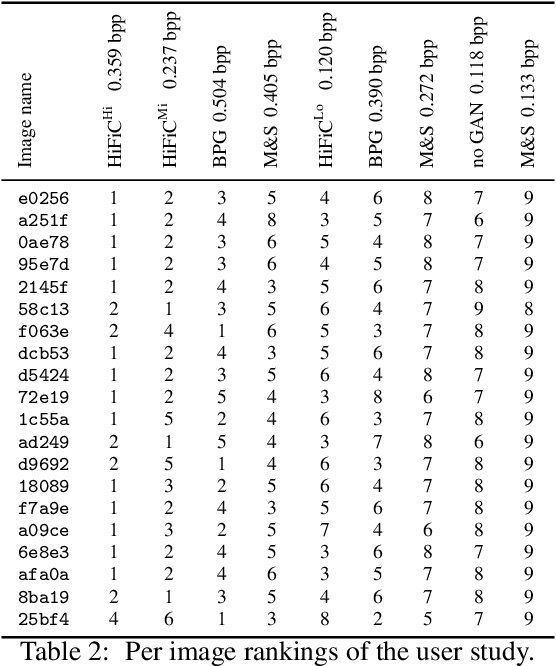
We extensively study how to combine Generative Adversarial Networks and learned compression to obtain a state-of-the-art generative lossy compression system. In particular, we investigate normalization layers, generator and discriminator architectures, training strategies, as well as perceptual losses. In contrast to previous work, i) we obtain visually pleasing reconstructions that are perceptually similar to the input, ii) we operate in a broad range of bitrates, and iii) our approach can be applied to high-resolution images. We bridge the gap between rate-distortion-perception theory and practice by evaluating our approach both quantitatively with various perceptual metrics and a user study. The study shows that our method is preferred to previous approaches even if they use more than 2x the bitrate.