 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Distracting Control Suite -- A Challenging Benchmark for Reinforcement Learning from Pixels
Jan 07, 2021
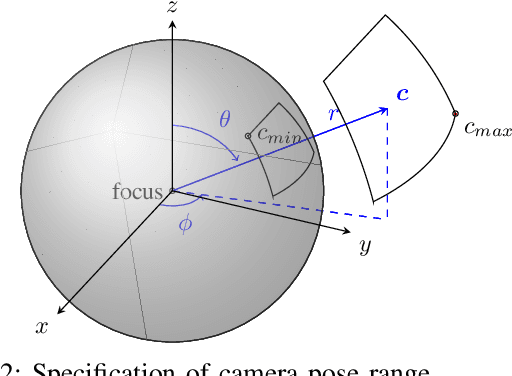
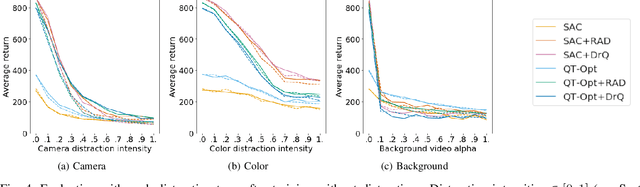
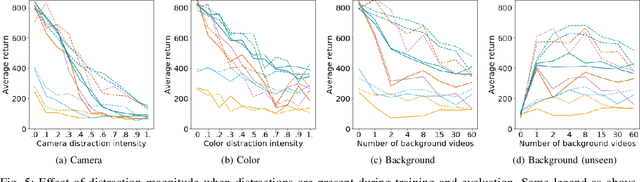
Robots have to face challenging perceptual settings, including changes in viewpoint, lighting, and background. Current simulated reinforcement learning (RL) benchmarks such as DM Control provide visual input without such complexity, which limits the transfer of well-performing methods to the real world. In this paper, we extend DM Control with three kinds of visual distractions (variations in background, color, and camera pose) to produce a new challenging benchmark for vision-based control, and we analyze state of the art RL algorithms in these settings. Our experiments show that current RL methods for vision-based control perform poorly under distractions, and that their performance decreases with increasing distraction complexity, showing that new methods are needed to cope with the visual complexities of the real world. We also find that combinations of multiple distraction types are more difficult than a mere combination of their individual effects.
What Matters in Unsupervised Optical Flow
Jun 08, 2020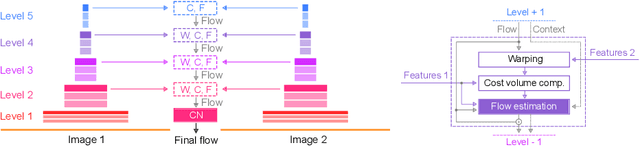
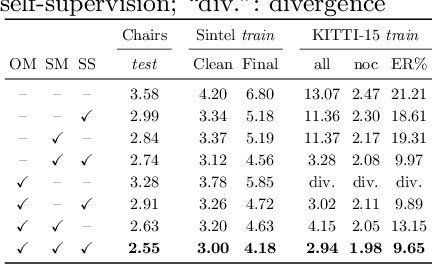


We systematically compare and analyze a set of key components in unsupervised optical flow to identify which photometric loss, occlusion handling, and smoothness regularization is most effective. Alongside this investigation we construct a number of novel improvements to unsupervised flow models, such as cost volume normalization, stopping the gradient at the occlusion mask, encouraging smoothness before upsampling the flow field, and continual self-supervision with image resizing. By combining the results of our investigation with our improved model components, we are able to present a new unsupervised flow technique that significantly outperforms the previous unsupervised state-of-the-art and performs on par with supervised FlowNet2 on the KITTI 2015 dataset, while also being significantly simpler than related approaches.
KeyPose: Multi-view 3D Labeling and Keypoint Estimation for Transparent Objects
Dec 05, 2019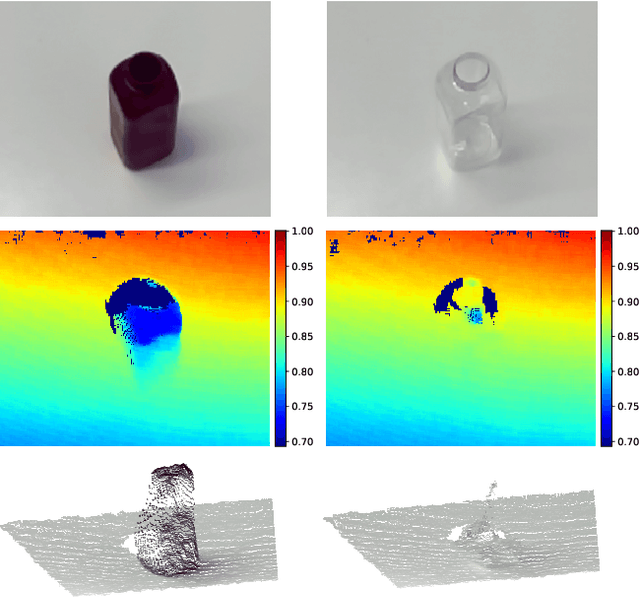

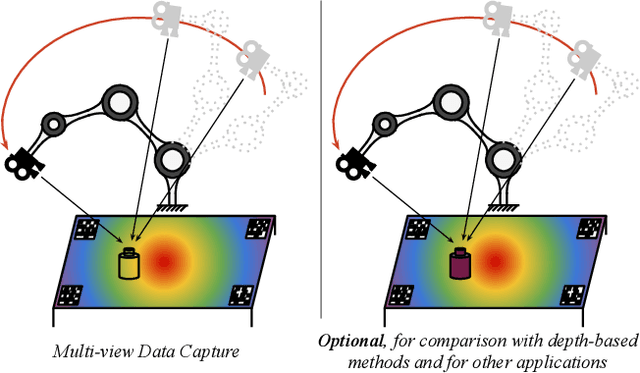
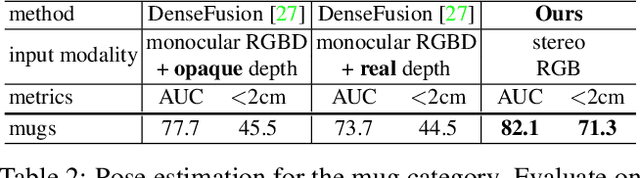
Estimating the 3D pose of desktop objects is crucial for applications such as robotic manipulation. Finding the depth of the object is an important part of this task, both for training and prediction, and is usually accomplished with a depth sensor or markers in a motion-capture system. For transparent or highly reflective objects, such methods are not feasible without impinging on the resultant image of the object. Hence, many existing methods restrict themselves to opaque, lambertian objects that give good returns from RGBD sensors. In this paper we address two problems: first, establish an easy method for capturing and labeling 3D keypoints on desktop objects with a stereo sensor (no special depth sensor required); and second, develop a deep method, called $KeyPose$, that learns to accurately predict 3D keypoints on objects, including challenging ones such as transparent objects. To showcase the performance of the method, we create and employ a dataset of 15 clear objects in 5 classes, with 48k 3D-keypoint labeled images. We train both instance and category models, and show generalization to new textures, poses, and objects. KeyPose surpasses state-of-the-art performance in 3D pose estimation on this dataset, sometimes by a wide margin, and even in cases where the competing method is provided with registered depth. We will release a public version of the data capture and labeling pipeline, the transparent object database, and the KeyPose training and evaluation code.
On Pre-Trained Image Features and Synthetic Images for Deep Learning
Nov 16, 2017
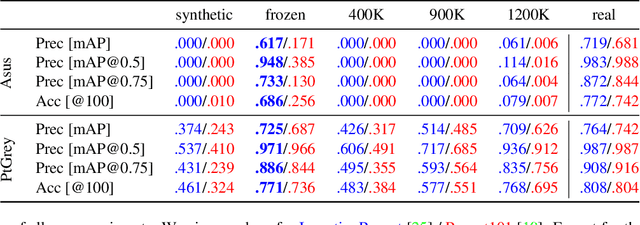
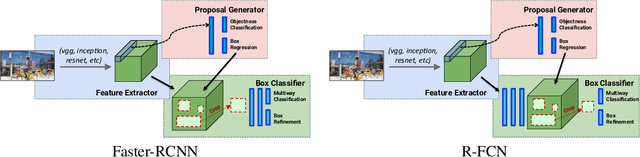
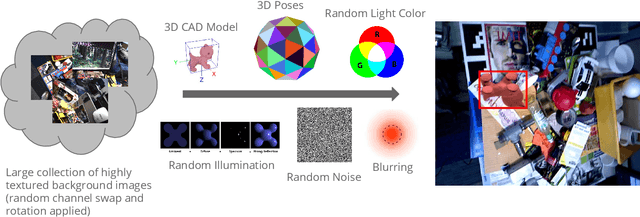
Deep Learning methods usually require huge amounts of training data to perform at their full potential, and often require expensive manual labeling. Using synthetic images is therefore very attractive to train object detectors, as the labeling comes for free, and several approaches have been proposed to combine synthetic and real images for training. In this paper, we show that a simple trick is sufficient to train very effectively modern object detectors with synthetic images only: We freeze the layers responsible for feature extraction to generic layers pre-trained on real images, and train only the remaining layers with plain OpenGL rendering. Our experiments with very recent deep architectures for object recognition (Faster-RCNN, R-FCN, Mask-RCNN) and image feature extractors (InceptionResnet and Resnet) show this simple approach performs surprisingly well.
Going Further with Point Pair Features
Nov 11, 2017
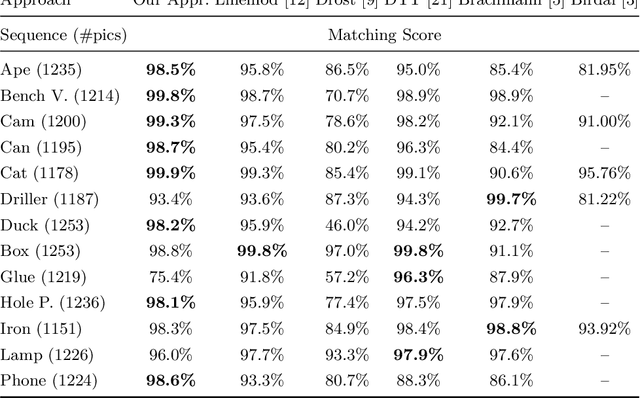
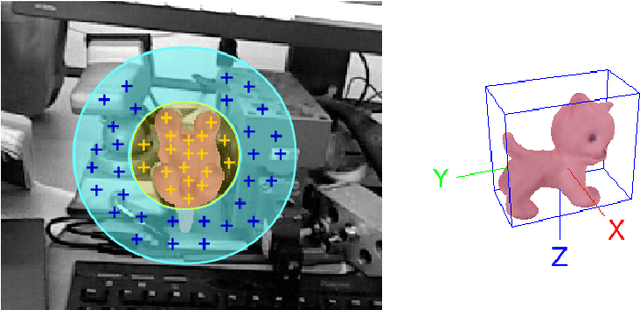
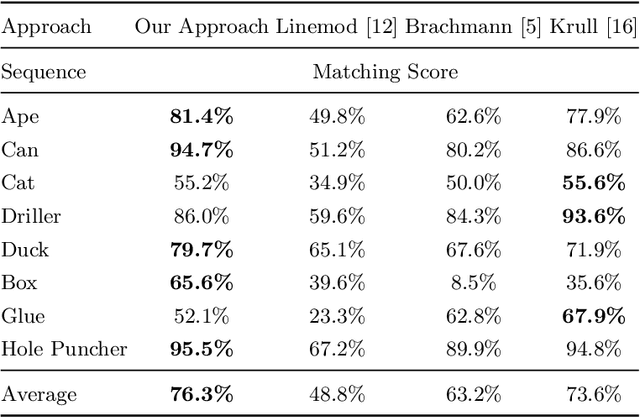
Point Pair Features is a widely used method to detect 3D objects in point clouds, however they are prone to fail in presence of sensor noise and background clutter. We introduce novel sampling and voting schemes that significantly reduces the influence of clutter and sensor noise. Our experiments show that with our improvements, PPFs become competitive against state-of-the-art methods as it outperforms them on several objects from challenging benchmarks, at a low computational cost.
Using Simulation and Domain Adaptation to Improve Efficiency of Deep Robotic Grasping
Sep 25, 2017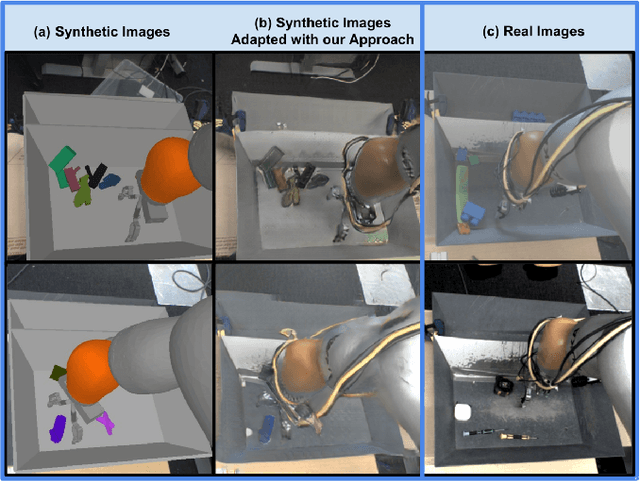


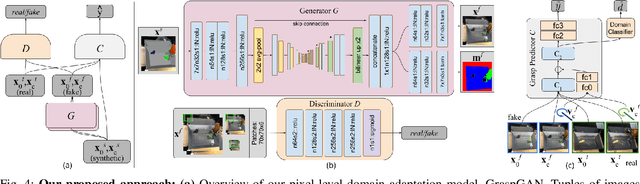
Instrumenting and collecting annotated visual grasping datasets to train modern machine learning algorithms can be extremely time-consuming and expensive. An appealing alternative is to use off-the-shelf simulators to render synthetic data for which ground-truth annotations are generated automatically. Unfortunately, models trained purely on simulated data often fail to generalize to the real world. We study how randomized simulated environments and domain adaptation methods can be extended to train a grasping system to grasp novel objects from raw monocular RGB images. We extensively evaluate our approaches with a total of more than 25,000 physical test grasps, studying a range of simulation conditions and domain adaptation methods, including a novel extension of pixel-level domain adaptation that we term the GraspGAN. We show that, by using synthetic data and domain adaptation, we are able to reduce the number of real-world samples needed to achieve a given level of performance by up to 50 times, using only randomly generated simulated objects. We also show that by using only unlabeled real-world data and our GraspGAN methodology, we obtain real-world grasping performance without any real-world labels that is similar to that achieved with 939,777 labeled real-world samples.
The Revisiting Problem in Mobile Robot Map Building: A Hierarchical Bayesian Approach
Oct 19, 2012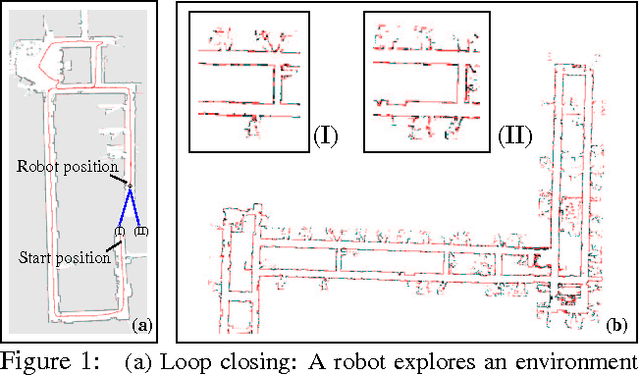
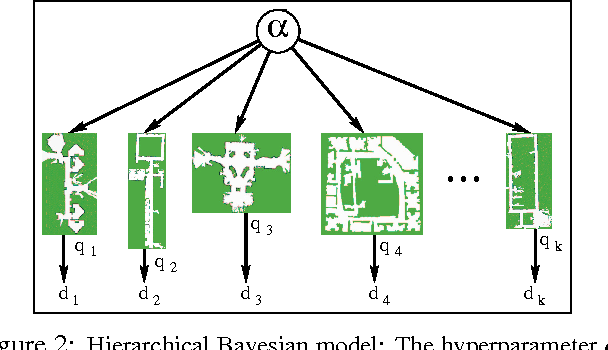
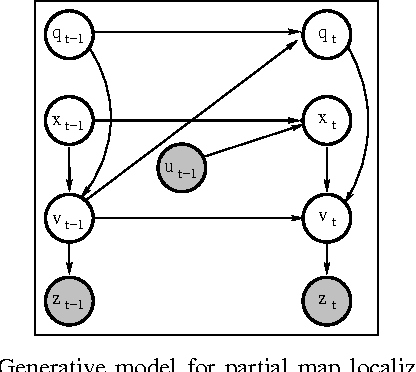
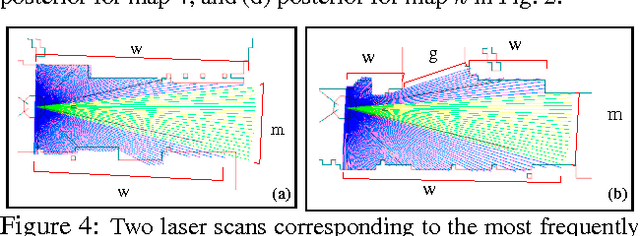
We present an application of hierarchical Bayesian estimation to robot map building. The revisiting problem occurs when a robot has to decide whether it is seeing a previously-built portion of a map, or is exploring new territory. This is a difficult decision problem, requiring the probability of being outside of the current known map. To estimate this probability, we model the structure of a "typical" environment as a hidden Markov model that generates sequences of views observed by a robot navigating through the environment. A Dirichlet prior over structural models is learned from previously explored environments. Whenever a robot explores a new environment, the posterior over the model is estimated by Dirichlet hyperparameters. Our approach is implemented and tested in the context of multi-robot map merging, a particularly difficult instance of the revisiting problem. Experiments with robot data show that the technique yields strong improvements over alternative methods.