 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Pre-Trained Image Features and Synthetic Images for Deep Learning
Paper and Code
Nov 16, 2017
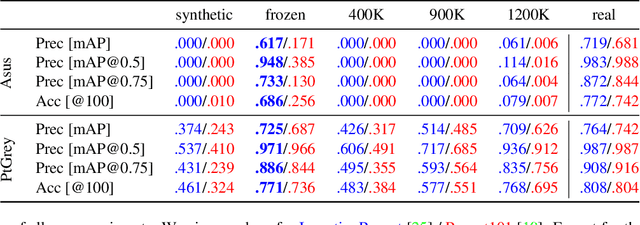
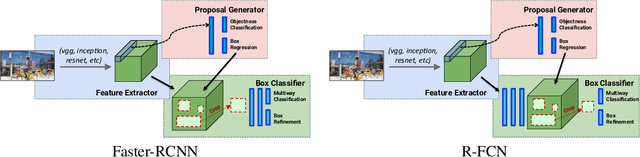
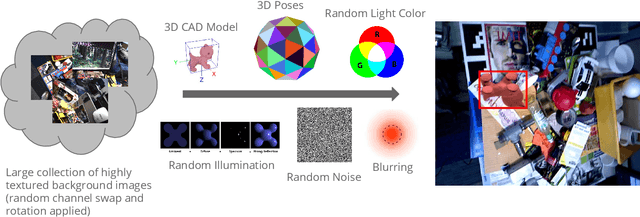
Deep Learning methods usually require huge amounts of training data to perform at their full potential, and often require expensive manual labeling. Using synthetic images is therefore very attractive to train object detectors, as the labeling comes for free, and several approaches have been proposed to combine synthetic and real images for training. In this paper, we show that a simple trick is sufficient to train very effectively modern object detectors with synthetic images only: We freeze the layers responsible for feature extraction to generic layers pre-trained on real images, and train only the remaining layers with plain OpenGL rendering. Our experiments with very recent deep architectures for object recognition (Faster-RCNN, R-FCN, Mask-RCNN) and image feature extractors (InceptionResnet and Resnet) show this simple approach performs surprisingly well.