 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Annotation Saved is an Annotation Earned: Using Fully Synthetic Training for Object Instance Detection
Feb 26, 2019


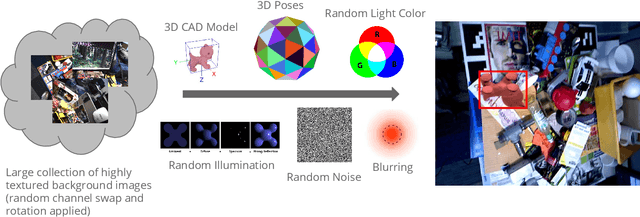
Deep learning methods typically require vast amounts of training data to reach their full potential. While some publicly available datasets exists, domain specific data always needs to be collected and manually labeled, an expensive, time consuming and error prone process. Training with synthetic data is therefore very lucrative, as dataset creation and labeling comes for free. We propose a novel method for creating purely synthetic training data for object detection. We leverage a large dataset of 3D background models and densely render them using full domain randomization. This yields background images with realistic shapes and texture on top of which we render the objects of interest. During training, the data generation process follows a curriculum strategy guaranteeing that all foreground models are presented to the network equally under all possible poses and conditions with increasing complexity. As a result, we entirely control the underlying statistics and we create optimal training samples at every stage of training. Using a set of 64 retail objects, we demonstrate that our simple approach enables the training of detectors that outperform models trained with real data on a challenging evaluation dataset.
Multi-Task Domain Adaptation for Deep Learning of Instance Grasping from Simulation
Mar 04, 2018

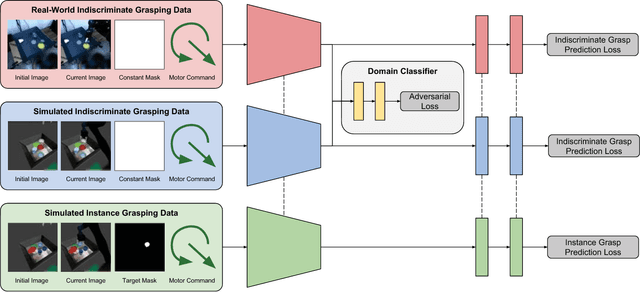
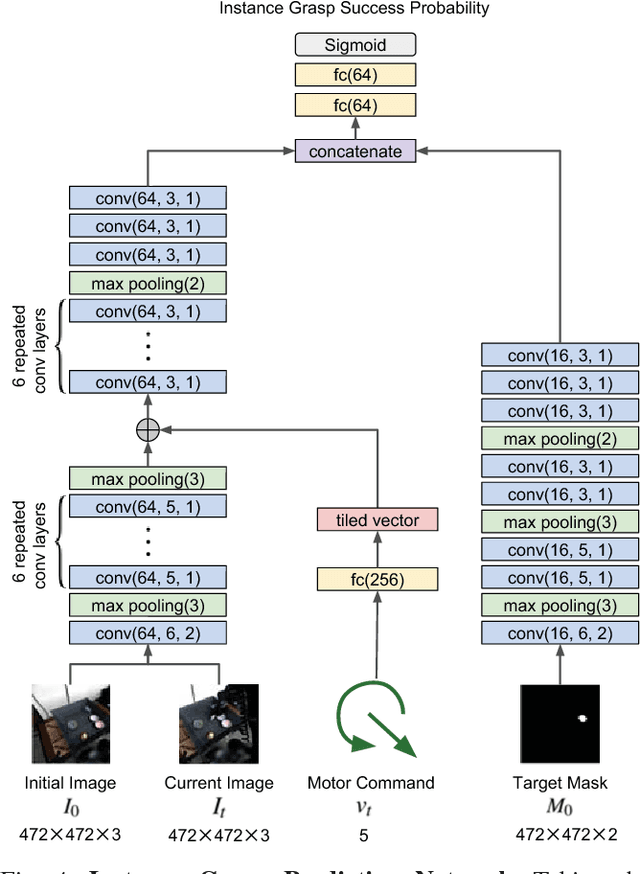
Learning-based approaches to robotic manipulation are limited by the scalability of data collection and accessibility of labels. In this paper, we present a multi-task domain adaptation framework for instance grasping in cluttered scenes by utilizing simulated robot experiments. Our neural network takes monocular RGB images and the instance segmentation mask of a specified target object as inputs, and predicts the probability of successfully grasping the specified object for each candidate motor command. The proposed transfer learning framework trains a model for instance grasping in simulation and uses a domain-adversarial loss to transfer the trained model to real robots using indiscriminate grasping data, which is available both in simulation and the real world. We evaluate our model in real-world robot experiments, comparing it with alternative model architectures as well as an indiscriminate grasping baseline.
On Pre-Trained Image Features and Synthetic Images for Deep Learning
Nov 16, 2017
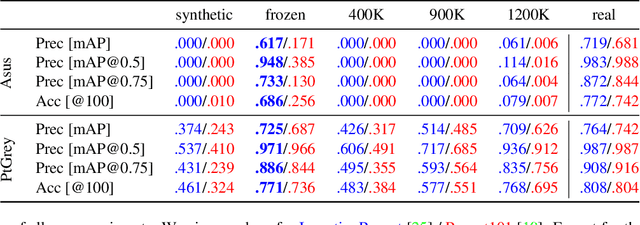
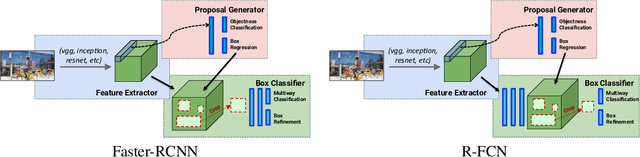
Deep Learning methods usually require huge amounts of training data to perform at their full potential, and often require expensive manual labeling. Using synthetic images is therefore very attractive to train object detectors, as the labeling comes for free, and several approaches have been proposed to combine synthetic and real images for training. In this paper, we show that a simple trick is sufficient to train very effectively modern object detectors with synthetic images only: We freeze the layers responsible for feature extraction to generic layers pre-trained on real images, and train only the remaining layers with plain OpenGL rendering. Our experiments with very recent deep architectures for object recognition (Faster-RCNN, R-FCN, Mask-RCNN) and image feature extractors (InceptionResnet and Resnet) show this simple approach performs surprisingly well.
Going Further with Point Pair Features
Nov 11, 2017
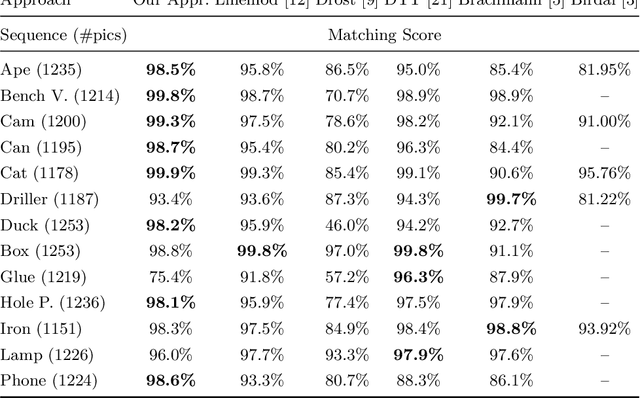
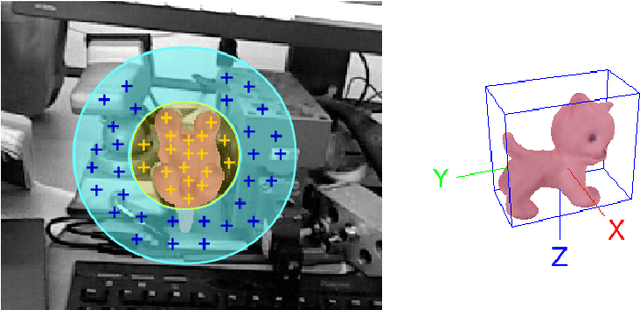
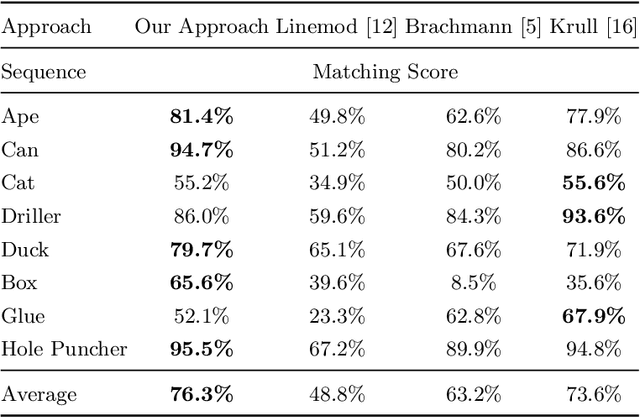
Point Pair Features is a widely used method to detect 3D objects in point clouds, however they are prone to fail in presence of sensor noise and background clutter. We introduce novel sampling and voting schemes that significantly reduces the influence of clutter and sensor noise. Our experiments show that with our improvements, PPFs become competitive against state-of-the-art methods as it outperforms them on several objects from challenging benchmarks, at a low computational cost.