 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D-MPA: Multi Proposal Aggregation for 3D Semantic Instance Segmentation
Mar 30, 2020
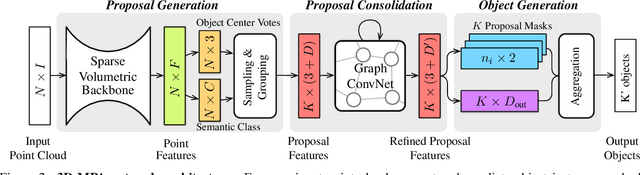


We present 3D-MPA, a method for instance segmentation on 3D point clouds. Given an input point cloud, we propose an object-centric approach where each point votes for its object center. We sample object proposals from the predicted object centers. Then, we learn proposal features from grouped point features that voted for the same object center. A graph convolutional network introduces inter-proposal relations, providing higher-level feature learning in addition to the lower-level point features. Each proposal comprises a semantic label, a set of associated points over which we define a foreground-background mask, an objectness score and aggregation features. Previous works usually perform non-maximum-suppression (NMS) over proposals to obtain the final object detections or semantic instances. However, NMS can discard potentially correct predictions. Instead, our approach keeps all proposals and groups them together based on the learned aggregation features. We show that grouping proposals improves over NMS and outperforms previous state-of-the-art methods on the tasks of 3D object detection and semantic instance segmentation on the ScanNetV2 benchmark and the S3DIS dataset.
An Annotation Saved is an Annotation Earned: Using Fully Synthetic Training for Object Instance Detection
Feb 26, 2019

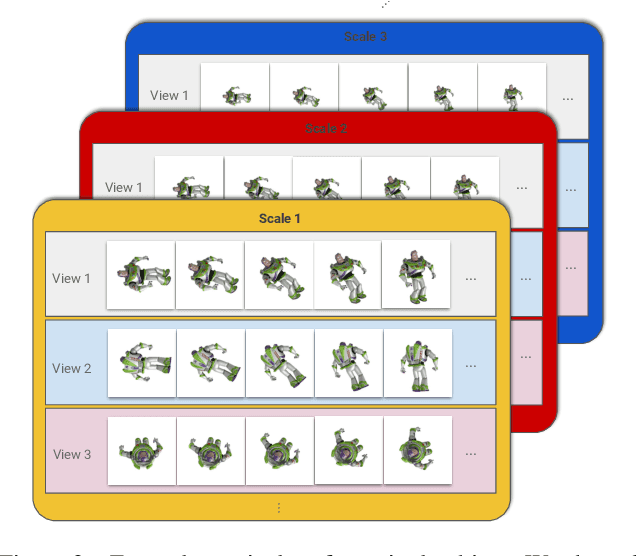

Deep learning methods typically require vast amounts of training data to reach their full potential. While some publicly available datasets exists, domain specific data always needs to be collected and manually labeled, an expensive, time consuming and error prone process. Training with synthetic data is therefore very lucrative, as dataset creation and labeling comes for free. We propose a novel method for creating purely synthetic training data for object detection. We leverage a large dataset of 3D background models and densely render them using full domain randomization. This yields background images with realistic shapes and texture on top of which we render the objects of interest. During training, the data generation process follows a curriculum strategy guaranteeing that all foreground models are presented to the network equally under all possible poses and conditions with increasing complexity. As a result, we entirely control the underlying statistics and we create optimal training samples at every stage of training. Using a set of 64 retail objects, we demonstrate that our simple approach enables the training of detectors that outperform models trained with real data on a challenging evaluation dataset.
ScanComplete: Large-Scale Scene Completion and Semantic Segmentation for 3D Scans
Mar 28, 2018
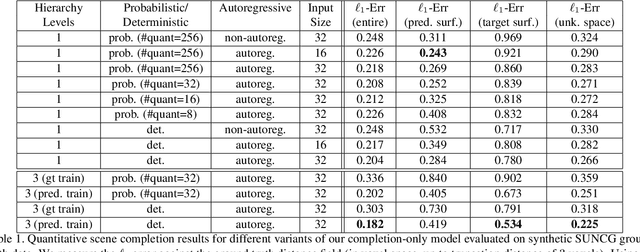
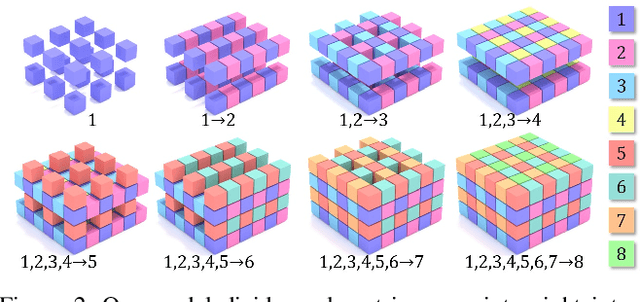

We introduce ScanComplete, a novel data-driven approach for taking an incomplete 3D scan of a scene as input and predicting a complete 3D model along with per-voxel semantic labels. The key contribution of our method is its ability to handle large scenes with varying spatial extent, managing the cubic growth in data size as scene size increases. To this end, we devise a fully-convolutional generative 3D CNN model whose filter kernels are invariant to the overall scene size. The model can be trained on scene subvolumes but deployed on arbitrarily large scenes at test time. In addition, we propose a coarse-to-fine inference strategy in order to produce high-resolution output while also leveraging large input context sizes. In an extensive series of experiments, we carefully evaluate different model design choices, considering both deterministic and probabilistic models for completion and semantic inference. Our results show that we outperform other methods not only in the size of the environments handled and processing efficiency, but also with regard to completion quality and semantic segmentation performance by a significant margin.