 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Annotation Saved is an Annotation Earned: Using Fully Synthetic Training for Object Instance Detection
Feb 26, 2019

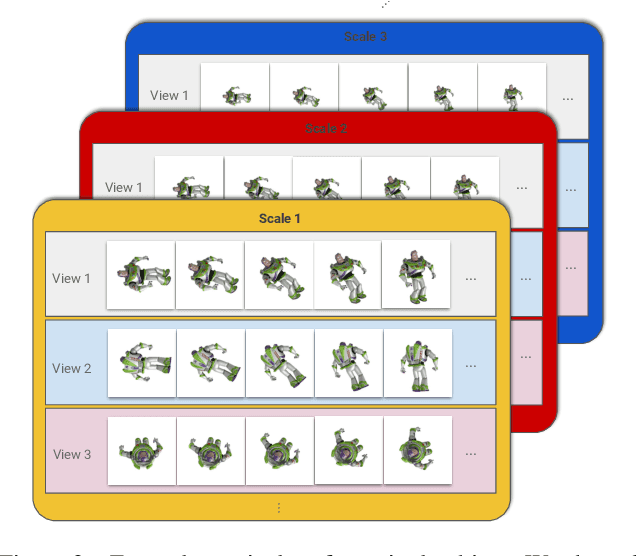

Deep learning methods typically require vast amounts of training data to reach their full potential. While some publicly available datasets exists, domain specific data always needs to be collected and manually labeled, an expensive, time consuming and error prone process. Training with synthetic data is therefore very lucrative, as dataset creation and labeling comes for free. We propose a novel method for creating purely synthetic training data for object detection. We leverage a large dataset of 3D background models and densely render them using full domain randomization. This yields background images with realistic shapes and texture on top of which we render the objects of interest. During training, the data generation process follows a curriculum strategy guaranteeing that all foreground models are presented to the network equally under all possible poses and conditions with increasing complexity. As a result, we entirely control the underlying statistics and we create optimal training samples at every stage of training. Using a set of 64 retail objects, we demonstrate that our simple approach enables the training of detectors that outperform models trained with real data on a challenging evaluation dataset.
3D Anisotropic Hybrid Network: Transferring Convolutional Features from 2D Images to 3D Anisotropic Volumes
Dec 04, 2017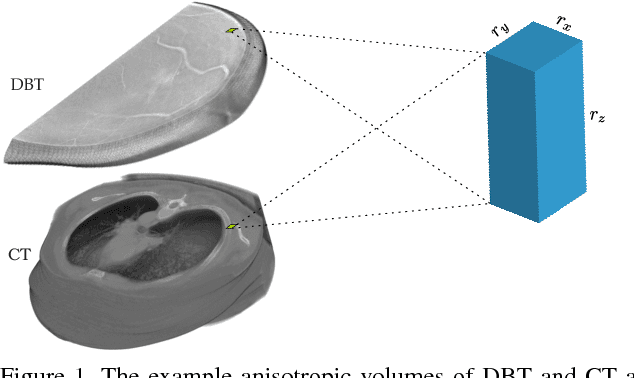
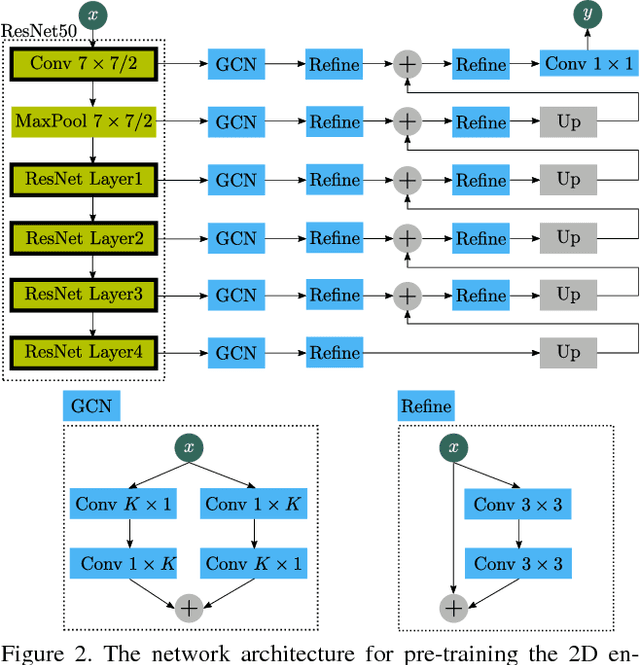
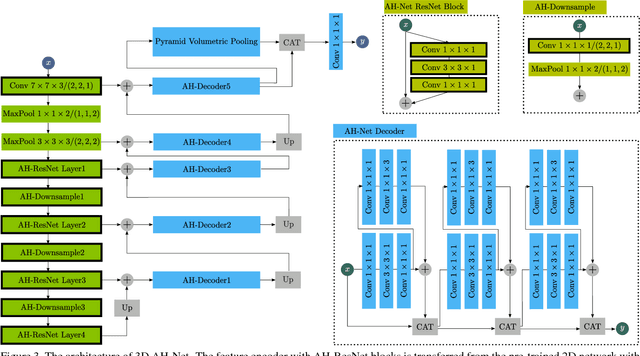
While deep convolutional neural networks (CNN) have been successfully applied for 2D image analysis, it is still challenging to apply them to 3D anisotropic volumes, especially when the within-slice resolution is much higher than the between-slice resolution and when the amount of 3D volumes is relatively small. On one hand, direct learning of CNN with 3D convolution kernels suffers from the lack of data and likely ends up with poor generalization; insufficient GPU memory limits the model size or representational power. On the other hand, applying 2D CNN with generalizable features to 2D slices ignores between-slice information. Coupling 2D network with LSTM to further handle the between-slice information is not optimal due to the difficulty in LSTM learning. To overcome the above challenges, we propose a 3D Anisotropic Hybrid Network (AH-Net) that transfers convolutional features learned from 2D images to 3D anisotropic volumes. Such a transfer inherits the desired strong generalization capability for within-slice information while naturally exploiting between-slice information for more effective modelling. The focal loss is further utilized for more effective end-to-end learning. We experiment with the proposed 3D AH-Net on two different medical image analysis tasks, namely lesion detection from a Digital Breast Tomosynthesis volume, and liver and liver tumor segmentation from a Computed Tomography volume and obtain the state-of-the-art results.