 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLaplacian Smoothing Gradient Descent
Paper and Code

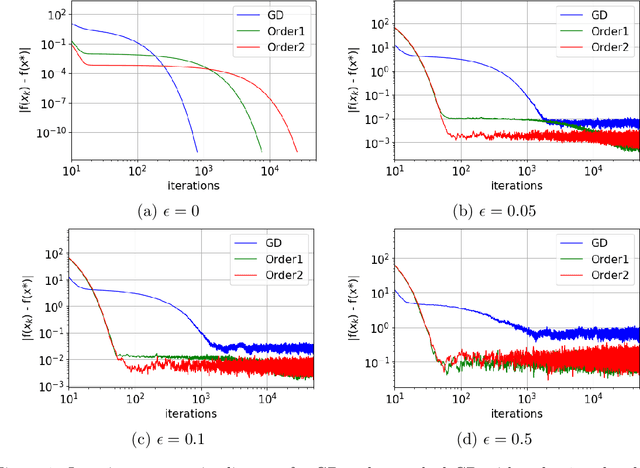

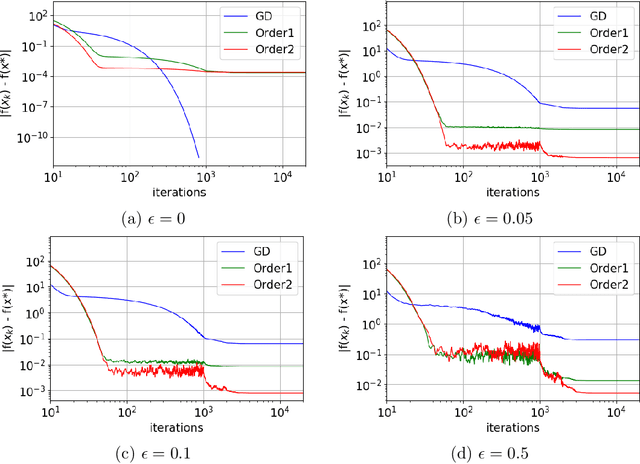
We propose a very simple modification of gradient descent and stochastic gradient descent. We show that when applied to a variety of machine learning models including softmax regression, convolutional neural nets, generative adversarial nets, and deep reinforcement learning, this very simple surrogate can dramatically reduce the variance and improve the accuracy of the generalization. The new algorithm, (which depends on one nonnegative parameter) when applied to non-convex minimization, tends to avoid sharp local minima. Instead it seeks somewhat flatter local (and often global) minima. The method only involves preconditioning the gradient by the inverse of a tri-diagonal matrix that is positive definite. The motivation comes from the theory of Hamilton-Jacobi partial differential equations. This theory demonstrates that the new algorithm is almost the same as doing gradient descent on a new function which (a) has the same global minima as the original function and (b) is "more convex". Again, the programming effort in doing this is minimal, in cost, complexity and effort. We implement our algorithm into both PyTorch and Tensorflow platforms, which will be made publicly available.