 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompound Tokens: Channel Fusion for Vision-Language Representation Learning
Dec 02, 2022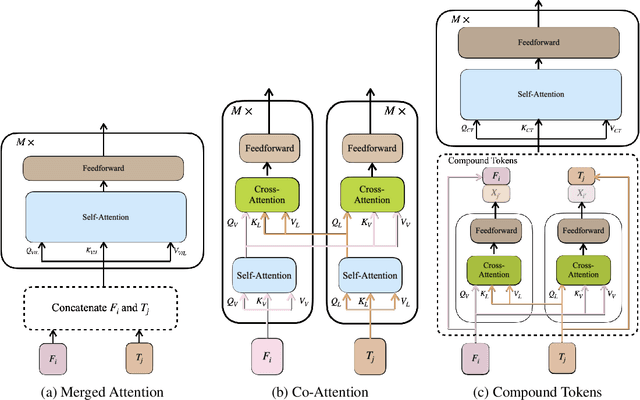



We present an effective method for fusing visual-and-language representations for several question answering tasks including visual question answering and visual entailment. In contrast to prior works that concatenate unimodal representations or use only cross-attention, we compose multimodal representations via channel fusion. By fusing on the channels, the model is able to more effectively align the tokens compared to standard methods. These multimodal representations, which we call compound tokens are generated with cross-attention transformer layers. First, vision tokens are used as queries to retrieve compatible text tokens through cross-attention. We then chain the vision tokens and the queried text tokens along the channel dimension. We call the resulting representations compound tokens. A second group of compound tokens are generated using an analogous process where the text tokens serve as queries to the cross-attention layer. We concatenate all the compound tokens for further processing with multimodal encoder. We demonstrate the effectiveness of compound tokens using an encoder-decoder vision-language model trained end-to-end in the open-vocabulary setting. Compound Tokens achieve highly competitive performance across a range of question answering tasks including GQA, VQA2.0, and SNLI-VE.
Slot Machines: Discovering Winning Combinations of Random Weights in Neural Networks
Jan 16, 2021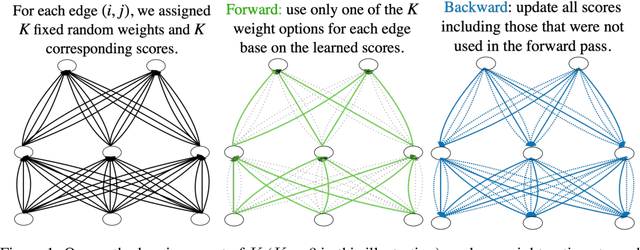


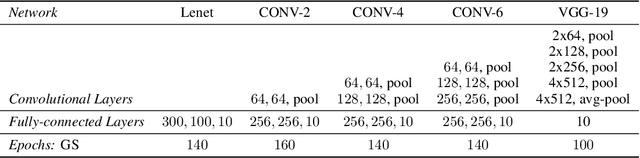
In contrast to traditional weight optimization in a continuous space, we demonstrate the existence of effective random networks whose weights are never updated. By selecting a weight among a fixed set of random values for each individual connection, our method uncovers combinations of random weights that match the performance of traditionally-trained networks of the same capacity. We refer to our networks as "slot machines" where each reel (connection) contains a fixed set of symbols (random values). Our backpropagation algorithm "spins" the reels to seek "winning" combinations, i.e., selections of random weight values that minimize the given loss. Quite surprisingly, we find that allocating just a few random values to each connection (e.g., 8 values per connection) yields highly competitive combinations despite being dramatically more constrained compared to traditionally learned weights. Moreover, finetuning these combinations often improves performance over the trained baselines. A randomly initialized VGG-19 with 8 values per connection contains a combination that achieves 90% test accuracy on CIFAR-10. Our method also achieves an impressive performance of 98.1% on MNIST for neural networks containing only random weights.