 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePaLI-X: On Scaling up a Multilingual Vision and Language Model
May 29, 2023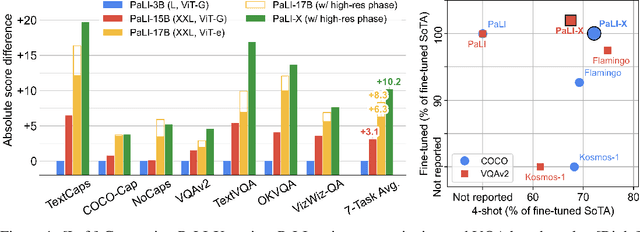
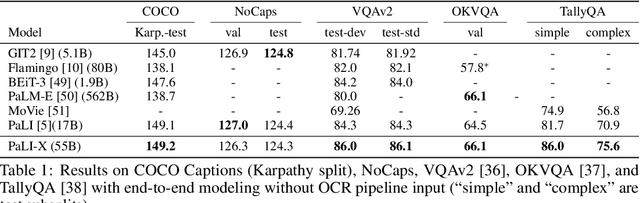
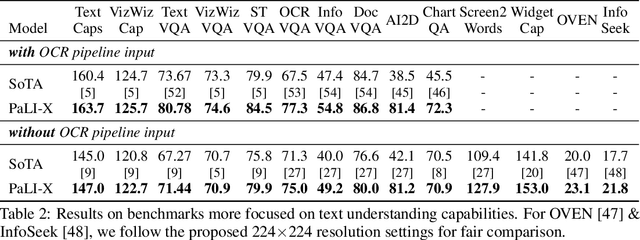

We present the training recipe and results of scaling up PaLI-X, a multilingual vision and language model, both in terms of size of the components and the breadth of its training task mixture. Our model achieves new levels of performance on a wide-range of varied and complex tasks, including multiple image-based captioning and question-answering tasks, image-based document understanding and few-shot (in-context) learning, as well as object detection, video question answering, and video captioning. PaLI-X advances the state-of-the-art on most vision-and-language benchmarks considered (25+ of them). Finally, we observe emerging capabilities, such as complex counting and multilingual object detection, tasks that are not explicitly in the training mix.
Towards Multi-Lingual Visual Question Answering
Sep 12, 2022

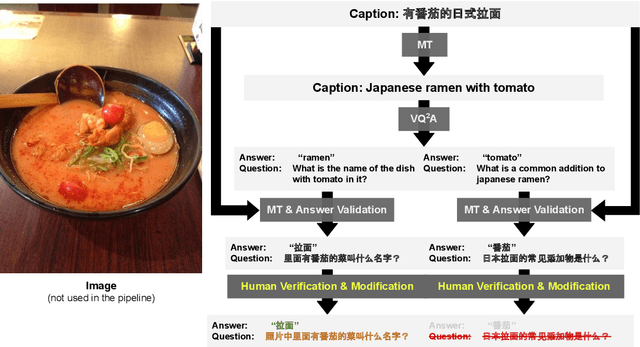

Visual Question Answering (VQA) has been primarily studied through the lens of the English language. Yet, tackling VQA in other languages in the same manner would require considerable amount of resources. In this paper, we propose scalable solutions to multi-lingual visual question answering (mVQA), on both data and modeling fronts. We first propose a translation-based framework to mVQA data generation that requires much less human annotation efforts than the conventional approach of directly collection questions and answers. Then, we apply our framework to the multi-lingual captions in the Crossmodal-3600 dataset and develop an efficient annotation protocol to create MAVERICS-XM3600 (MaXM), a test-only VQA benchmark in 7 diverse languages. Finally, we propose an approach to unified, extensible, open-ended, and end-to-end mVQA modeling and demonstrate strong performance in 13 languages.
Auto Completion of User Interface Layout Design Using Transformer-Based Tree Decoders
Jan 14, 2020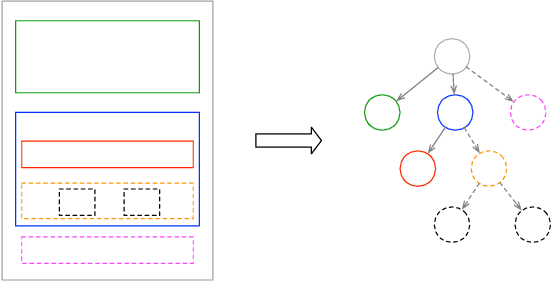

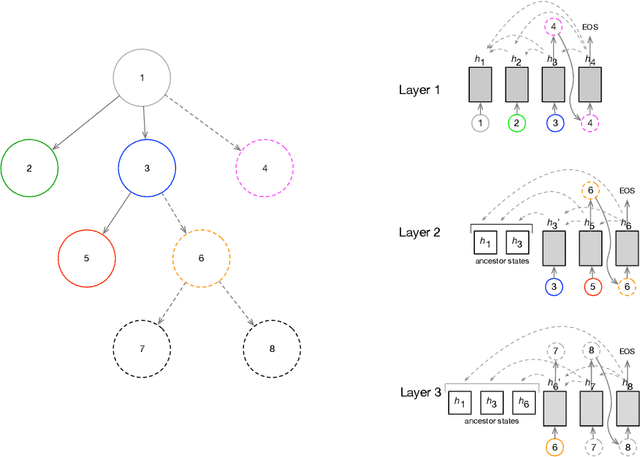
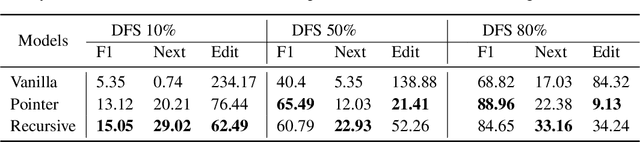
It has been of increasing interest in the field to develop automatic machineries to facilitate the design process. In this paper, we focus on assisting graphical user interface (UI) layout design, a crucial task in app development. Given a partial layout, which a designer has entered, our model learns to complete the layout by predicting the remaining UI elements with a correct position and dimension as well as the hierarchical structures. Such automation will significantly ease the effort of UI designers and developers. While we focus on interface layout prediction, our model can be generally applicable for other layout prediction problems that involve tree structures and 2-dimensional placements. Particularly, we design two versions of Transformer-based tree decoders: Pointer and Recursive Transformer, and experiment with these models on a public dataset. We also propose several metrics for measuring the accuracy of tree prediction and ground these metrics in the domain of user experience. These contribute a new task and methods to deep learning research.