 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeESG Classification by Implicit Rule Learning via GPT-4
Mar 22, 2024Environmental, social, and governance (ESG) factors are widely adopted as higher investment return indicators. Accordingly, ongoing efforts are being made to automate ESG evaluation with language models to extract signals from massive web text easily. However, recent approaches suffer from a lack of training data, as rating agencies keep their evaluation metrics confidential. This paper investigates whether state-of-the-art language models like GPT-4 can be guided to align with unknown ESG evaluation criteria through strategies such as prompting, chain-of-thought reasoning, and dynamic in-context learning. We demonstrate the efficacy of these approaches by ranking 2nd in the Shared-Task ML-ESG-3 Impact Type track for Korean without updating the model on the provided training data. We also explore how adjusting prompts impacts the ability of language models to address financial tasks leveraging smaller models with openly available weights. We observe longer general pre-training to correlate with enhanced performance in financial downstream tasks. Our findings showcase the potential of language models to navigate complex, subjective evaluation guidelines despite lacking explicit training examples, revealing opportunities for training-free solutions for financial downstream tasks.
Beyond Classification: Financial Reasoning in State-of-the-Art Language Models
Apr 30, 2023
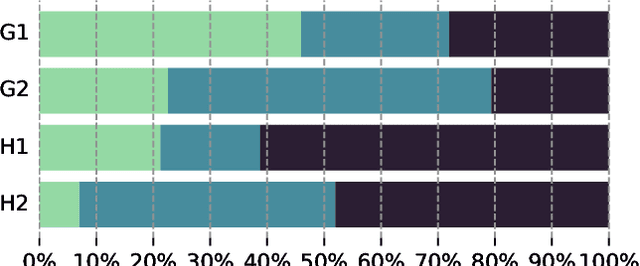
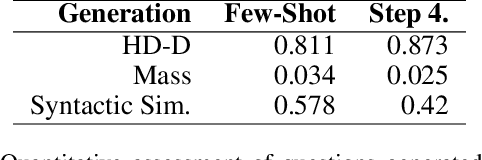
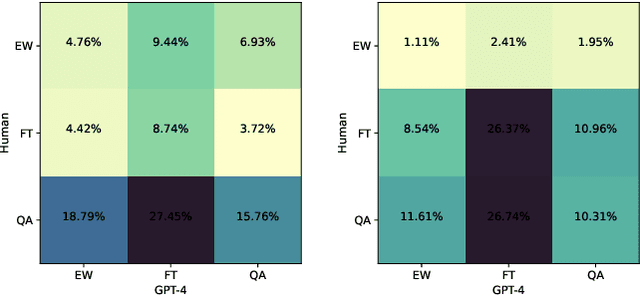
Large Language Models (LLMs), consisting of 100 billion or more parameters, have demonstrated remarkable ability in complex multi-step reasoning tasks. However, the application of such generic advancements has been limited to a few fields, such as clinical or legal, with the field of financial reasoning remaining largely unexplored. To the best of our knowledge, the ability of LLMs to solve financial reasoning problems has never been dealt with, and whether it can be performed at any scale remains unknown. To address this knowledge gap, this research presents a comprehensive investigation into the potential application of LLMs in the financial domain. The investigation includes a detailed exploration of a range of subjects, including task formulation, synthetic data generation, prompting methods, and evaluation capability. Furthermore, the study benchmarks various GPT variants with parameter scales ranging from 2.8B to 13B, with and without instruction tuning, on diverse dataset sizes. By analyzing the results, we reveal that the ability to generate coherent financial reasoning first emerges at 6B parameters, and continues to improve with better instruction-tuning or larger datasets. Additionally, the study provides a publicly accessible dataset named sFIOG (Synthetic-Financial Investment Opinion Generation), consisting of 11,802 synthetic investment thesis samples, to support further research in the field of financial reasoning. Overall, this research seeks to contribute to the understanding of the efficacy of language models in the field of finance, with a particular emphasis on their ability to engage in sophisticated reasoning and analysis within the context of investment decision-making.
Removing Non-Stationary Knowledge From Pre-Trained Language Models for Entity-Level Sentiment Classification in Finance
Jan 25, 2023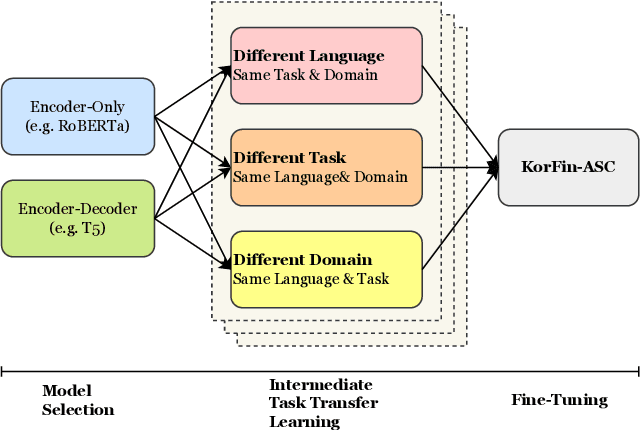

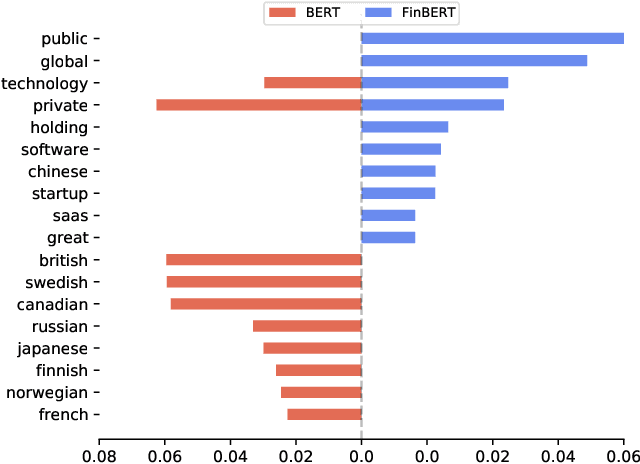
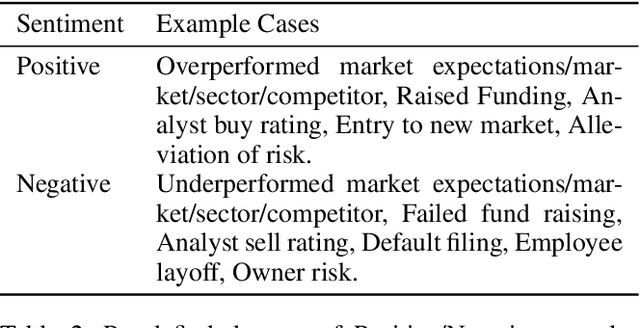
Extraction of sentiment signals from news text, stock message boards, and business reports, for stock movement prediction, has been a rising field of interest in finance. Building upon past literature, the most recent works attempt to better capture sentiment from sentences with complex syntactic structures by introducing aspect-level sentiment classification (ASC). Despite the growing interest, however, fine-grained sentiment analysis has not been fully explored in non-English literature due to the shortage of annotated finance-specific data. Accordingly, it is necessary for non-English languages to leverage datasets and pre-trained language models (PLM) of different domains, languages, and tasks to best their performance. To facilitate finance-specific ASC research in the Korean language, we build KorFinASC, a Korean aspect-level sentiment classification dataset for finance consisting of 12,613 human-annotated samples, and explore methods of intermediate transfer learning. Our experiments indicate that past research has been ignorant towards the potentially wrong knowledge of financial entities encoded during the training phase, which has overestimated the predictive power of PLMs. In our work, we use the term "non-stationary knowledge'' to refer to information that was previously correct but is likely to change, and present "TGT-Masking'', a novel masking pattern to restrict PLMs from speculating knowledge of the kind. Finally, through a series of transfer learning with TGT-Masking applied we improve 22.63% of classification accuracy compared to standalone models on KorFinASC.