 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePseudo-RIS: Distinctive Pseudo-supervision Generation for Referring Image Segmentation
Paper and Code
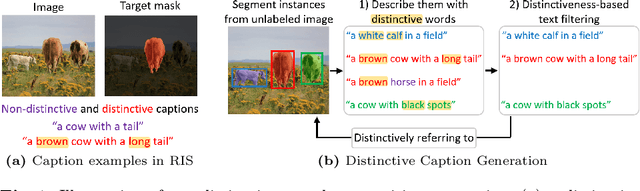
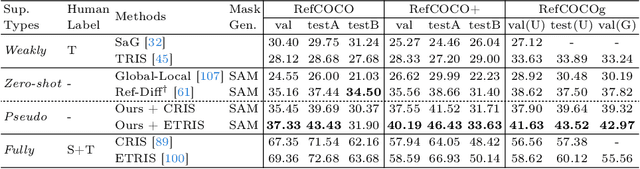
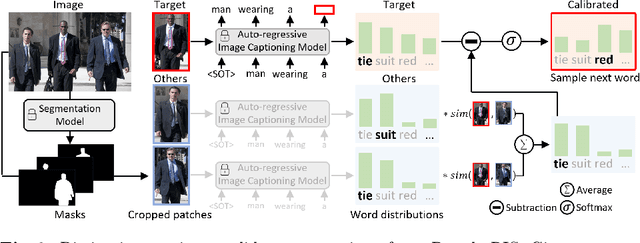
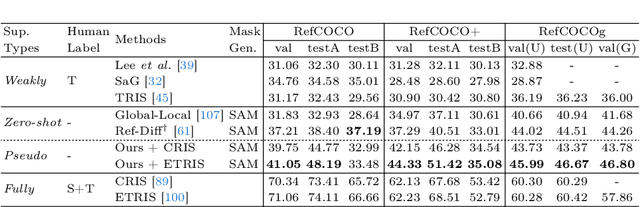
We propose a new framework that automatically generates high-quality segmentation masks with their referring expressions as pseudo supervisions for referring image segmentation (RIS). These pseudo supervisions allow the training of any supervised RIS methods without the cost of manual labeling. To achieve this, we incorporate existing segmentation and image captioning foundation models, leveraging their broad generalization capabilities. However, the naive incorporation of these models may generate non-distinctive expressions that do not distinctively refer to the target masks. To address this challenge, we propose two-fold strategies that generate distinctive captions: 1) 'distinctive caption sampling', a new decoding method for the captioning model, to generate multiple expression candidates with detailed words focusing on the target. 2) 'distinctiveness-based text filtering' to further validate the candidates and filter out those with a low level of distinctiveness. These two strategies ensure that the generated text supervisions can distinguish the target from other objects, making them appropriate for the RIS annotations. Our method significantly outperforms both weakly and zero-shot SoTA methods on the RIS benchmark datasets. It also surpasses fully supervised methods in unseen domains, proving its capability to tackle the open-world challenge within RIS. Furthermore, integrating our method with human annotations yields further improvements, highlighting its potential in semi-supervised learning applications.