 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructured State-Space Regularization for Compact and Generation-Friendly Image Tokenization
Apr 13, 2026Image tokenizers are central to modern vision models as they often operate in latent spaces. An ideal latent space must be simultaneously compact and generation-friendly: it should capture image's essential content compactly while remaining easy to model with generative approaches. In this work, we introduce a novel regularizer to align latent spaces with these two objectives. The key idea is to guide tokenizers to mimic the hidden state dynamics of state-space models (SSMs), thereby transferring their critical property, frequency awareness, to latent features. Grounded in a theoretical analysis of SSMs, our regularizer enforces encoding of fine spatial structures and frequency-domain cues into compact latent features; leading to more effective use of representation capacity and improved generative modelability. Experiments demonstrate that our method improves generation quality in diffusion models while incurring only minimal loss in reconstruction fidelity.
Planning in 8 Tokens: A Compact Discrete Tokenizer for Latent World Model
Mar 05, 2026World models provide a powerful framework for simulating environment dynamics conditioned on actions or instructions, enabling downstream tasks such as action planning or policy learning. Recent approaches leverage world models as learned simulators, but its application to decision-time planning remains computationally prohibitive for real-time control. A key bottleneck lies in latent representations: conventional tokenizers encode each observation into hundreds of tokens, making planning both slow and resource-intensive. To address this, we propose CompACT, a discrete tokenizer that compresses each observation into as few as 8 tokens, drastically reducing computational cost while preserving essential information for planning. An action-conditioned world model that occupies CompACT tokenizer achieves competitive planning performance with orders-of-magnitude faster planning, offering a practical step toward real-world deployment of world models.
Classification Matters: Improving Video Action Detection with Class-Specific Attention
Jul 29, 2024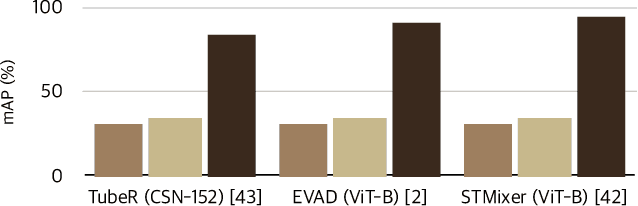
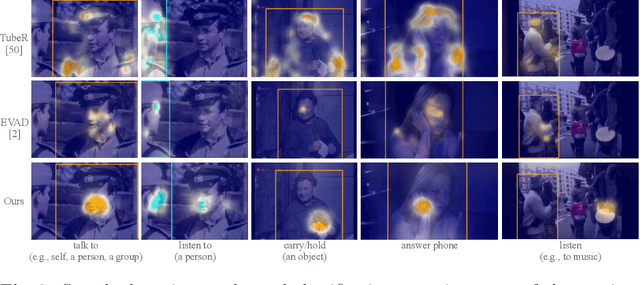
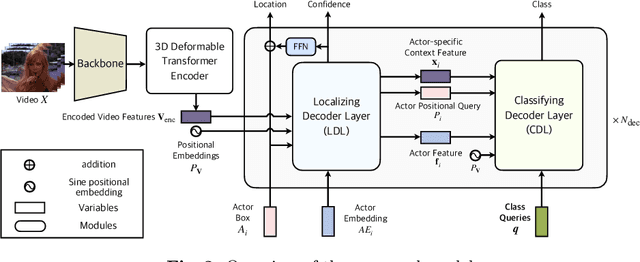
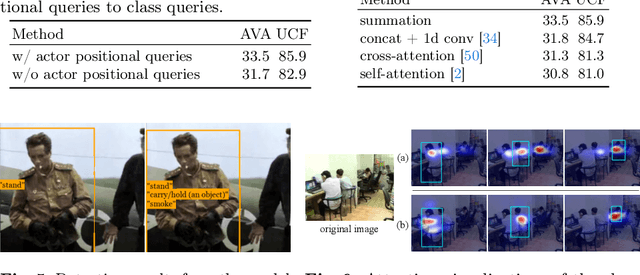
Video action detection (VAD) aims to detect actors and classify their actions in a video. We figure that VAD suffers more from classification rather than localization of actors. Hence, we analyze how prevailing methods form features for classification and find that they prioritize actor regions, yet often overlooking the essential contextual information necessary for accurate classification. Accordingly, we propose to reduce the bias toward actor and encourage paying attention to the context that is relevant to each action class. By assigning a class-dedicated query to each action class, our model can dynamically determine where to focus for effective classification. The proposed model demonstrates superior performance on three challenging benchmarks with significantly fewer parameters and less computation.
Detector-Free Weakly Supervised Group Activity Recognition
Apr 05, 2022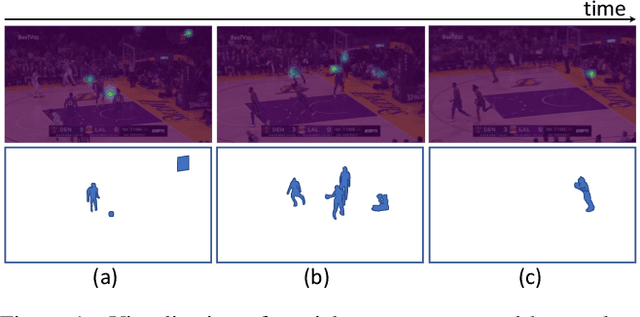
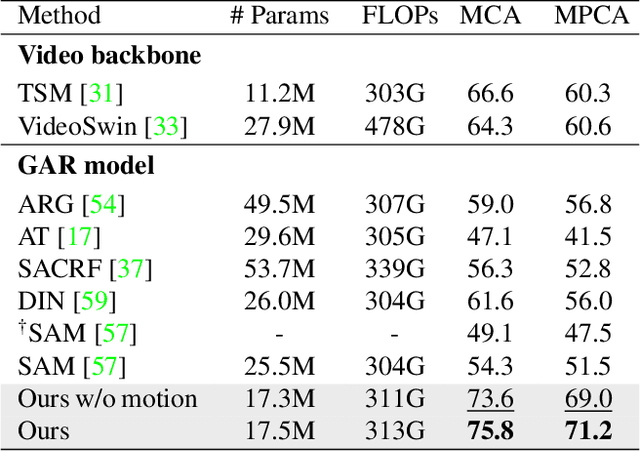
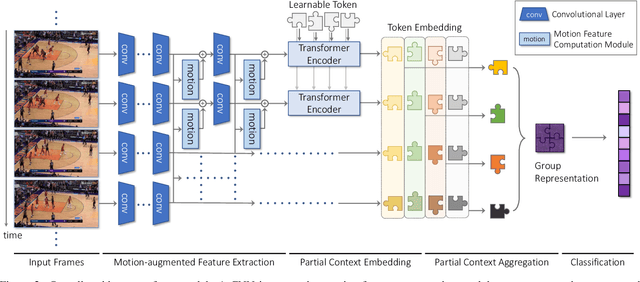
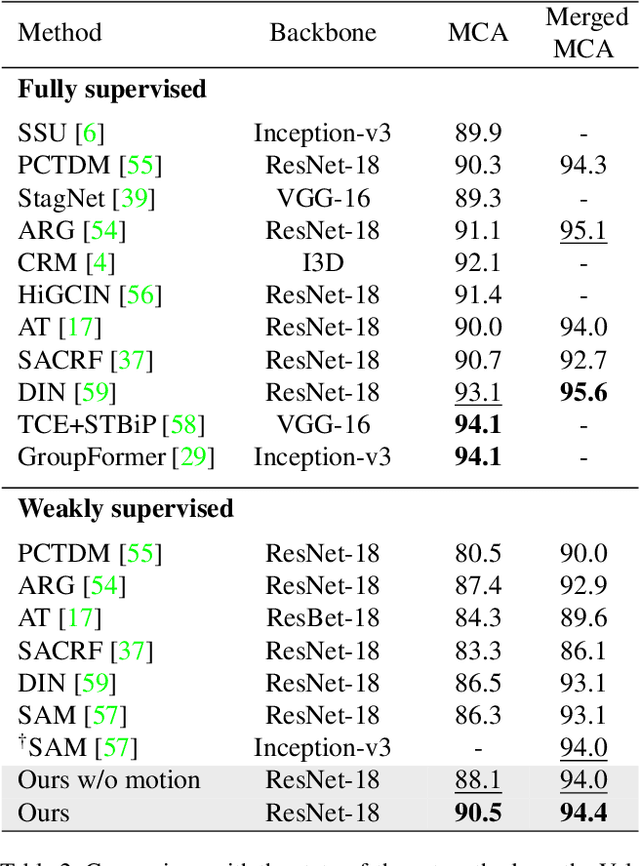
Group activity recognition is the task of understanding the activity conducted by a group of people as a whole in a multi-person video. Existing models for this task are often impractical in that they demand ground-truth bounding box labels of actors even in testing or rely on off-the-shelf object detectors. Motivated by this, we propose a novel model for group activity recognition that depends neither on bounding box labels nor on object detector. Our model based on Transformer localizes and encodes partial contexts of a group activity by leveraging the attention mechanism, and represents a video clip as a set of partial context embeddings. The embedding vectors are then aggregated to form a single group representation that reflects the entire context of an activity while capturing temporal evolution of each partial context. Our method achieves outstanding performance on two benchmarks, Volleyball and NBA datasets, surpassing not only the state of the art trained with the same level of supervision, but also some of existing models relying on stronger supervision.
Controllable Garment Transfer
Apr 05, 2022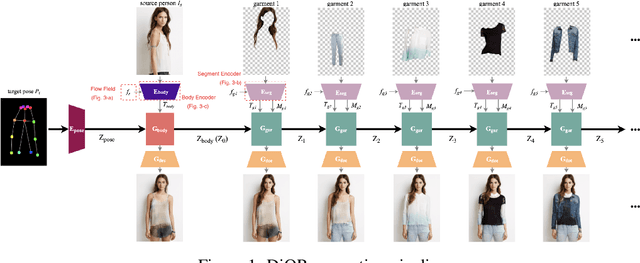
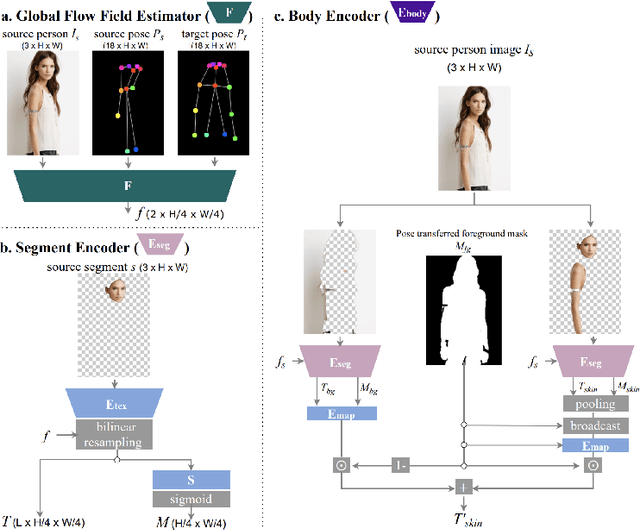


Image-based garment transfer replaces the garment on the target human with the desired garment; this enables users to virtually view themselves in the desired garment. To this end, many approaches have been proposed using the generative model and have shown promising results. However, most fail to provide the user with on the fly garment modification functionality. We aim to add this customizable option of "garment tweaking" to our model to control garment attributes, such as sleeve length, waist width, and garment texture.