 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePart-Aware Bottom-Up Group Reasoning for Fine-Grained Social Interaction Detection
Nov 05, 2025


Social interactions often emerge from subtle, fine-grained cues such as facial expressions, gaze, and gestures. However, existing methods for social interaction detection overlook such nuanced cues and primarily rely on holistic representations of individuals. Moreover, they directly detect social groups without explicitly modeling the underlying interactions between individuals. These drawbacks limit their ability to capture localized social signals and introduce ambiguity when group configurations should be inferred from social interactions grounded in nuanced cues. In this work, we propose a part-aware bottom-up group reasoning framework for fine-grained social interaction detection. The proposed method infers social groups and their interactions using body part features and their interpersonal relations. Our model first detects individuals and enhances their features using part-aware cues, and then infers group configuration by associating individuals via similarity-based reasoning, which considers not only spatial relations but also subtle social cues that signal interactions, leading to more accurate group inference. Experiments on the NVI dataset demonstrate that our method outperforms prior methods, achieving the new state of the art.
Online Temporal Action Localization with Memory-Augmented Transformer
Aug 06, 2024



Online temporal action localization (On-TAL) is the task of identifying multiple action instances given a streaming video. Since existing methods take as input only a video segment of fixed size per iteration, they are limited in considering long-term context and require tuning the segment size carefully. To overcome these limitations, we propose memory-augmented transformer (MATR). MATR utilizes the memory queue that selectively preserves the past segment features, allowing to leverage long-term context for inference. We also propose a novel action localization method that observes the current input segment to predict the end time of the ongoing action and accesses the memory queue to estimate the start time of the action. Our method outperformed existing methods on two datasets, THUMOS14 and MUSES, surpassing not only TAL methods in the online setting but also some offline TAL methods.
Towards More Practical Group Activity Detection: A New Benchmark and Model
Dec 05, 2023
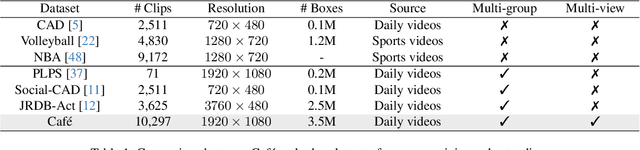
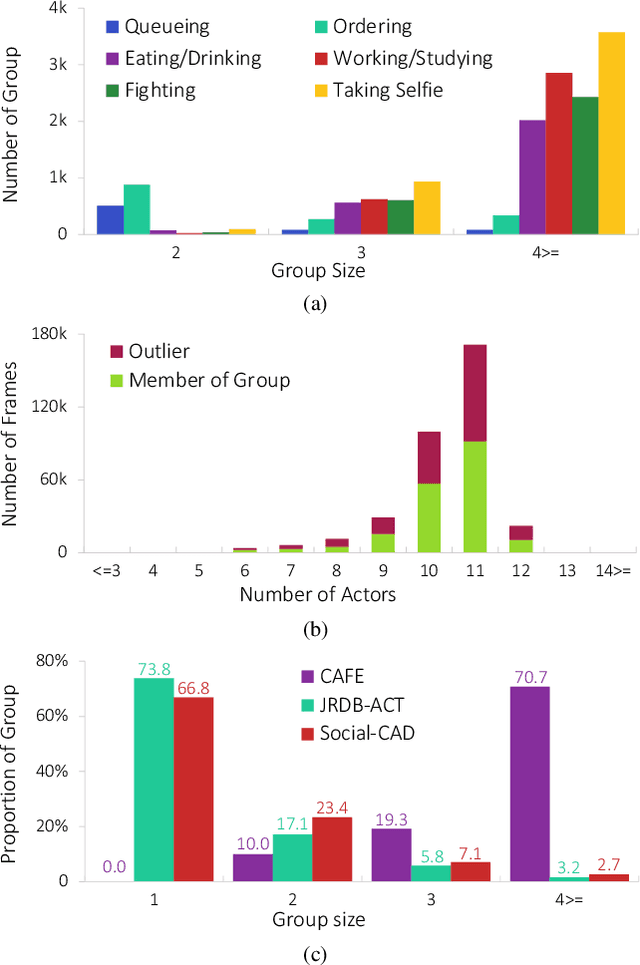
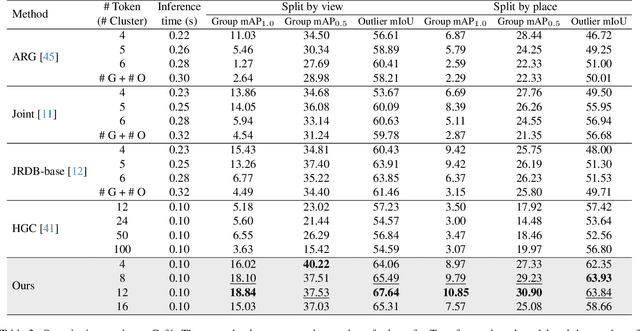
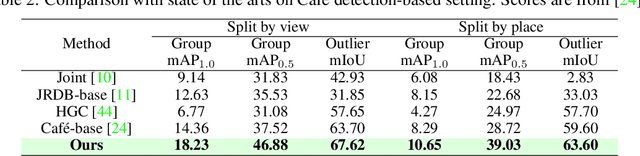
Group activity detection (GAD) is the task of identifying members of each group and classifying the activity of the group at the same time in a video. While GAD has been studied recently, there is still much room for improvement in both dataset and methodology due to their limited capability to address practical GAD scenarios. To resolve these issues, we first present a new dataset, dubbed Caf\'e. Unlike existing datasets, Caf\'e is constructed primarily for GAD and presents more practical evaluation scenarios and metrics, as well as being large-scale and providing rich annotations. Along with the dataset, we propose a new GAD model that deals with an unknown number of groups and latent group members efficiently and effectively. We evaluated our model on three datasets including Caf\'e, where it outperformed previous work in terms of both accuracy and inference speed. Both our dataset and code base will be open to the public to promote future research on GAD.
Detector-Free Weakly Supervised Group Activity Recognition
Apr 05, 2022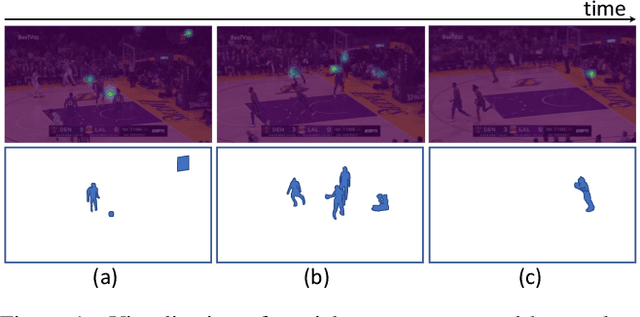
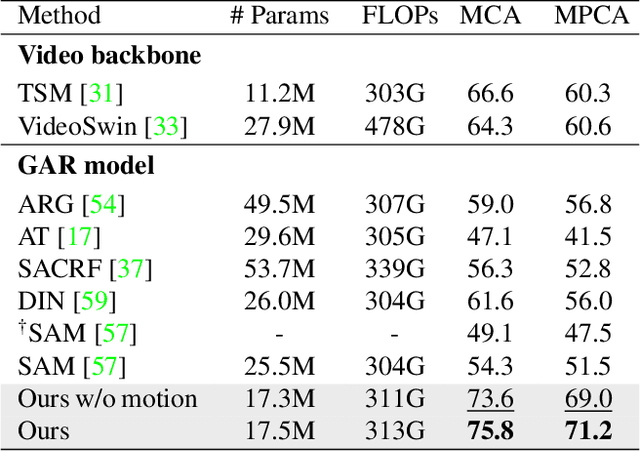
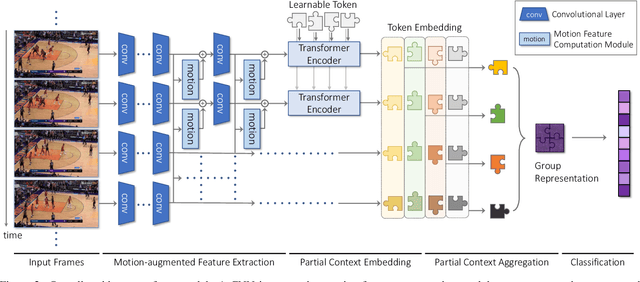
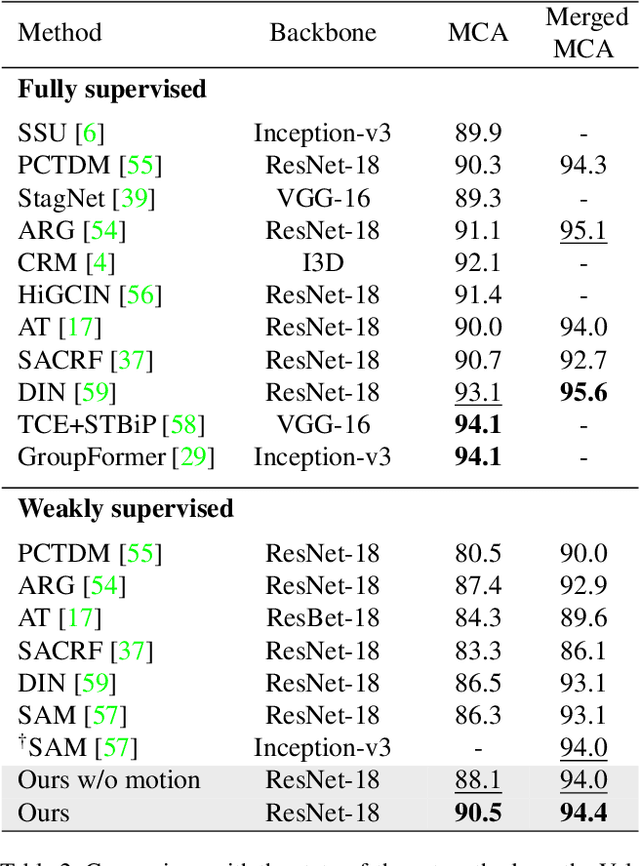
Group activity recognition is the task of understanding the activity conducted by a group of people as a whole in a multi-person video. Existing models for this task are often impractical in that they demand ground-truth bounding box labels of actors even in testing or rely on off-the-shelf object detectors. Motivated by this, we propose a novel model for group activity recognition that depends neither on bounding box labels nor on object detector. Our model based on Transformer localizes and encodes partial contexts of a group activity by leveraging the attention mechanism, and represents a video clip as a set of partial context embeddings. The embedding vectors are then aggregated to form a single group representation that reflects the entire context of an activity while capturing temporal evolution of each partial context. Our method achieves outstanding performance on two benchmarks, Volleyball and NBA datasets, surpassing not only the state of the art trained with the same level of supervision, but also some of existing models relying on stronger supervision.