 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Sound Source Localization with Joint Slot Attention on Image and Audio
Apr 21, 2025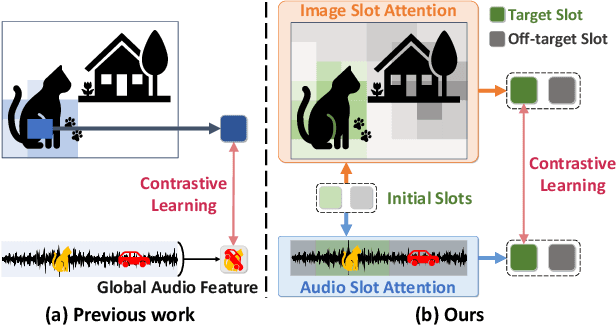
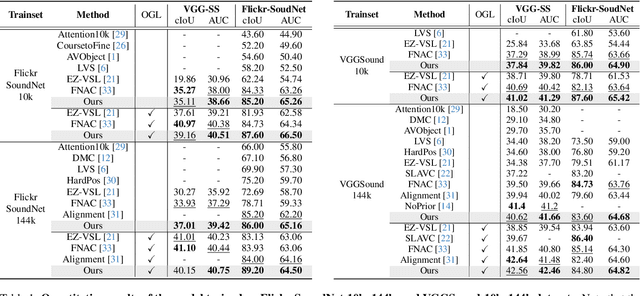
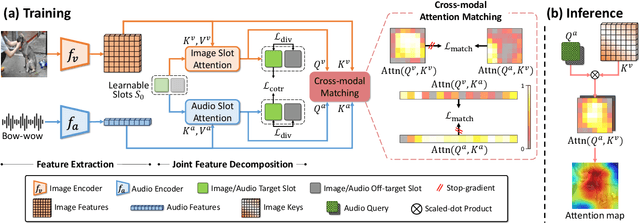
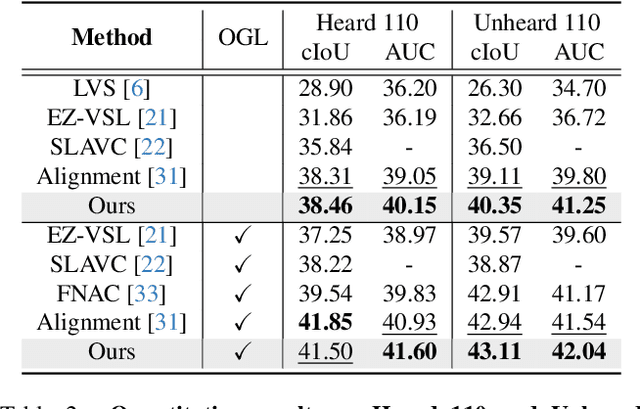
Sound source localization (SSL) is the task of locating the source of sound within an image. Due to the lack of localization labels, the de facto standard in SSL has been to represent an image and audio as a single embedding vector each, and use them to learn SSL via contrastive learning. To this end, previous work samples one of local image features as the image embedding and aggregates all local audio features to obtain the audio embedding, which is far from optimal due to the presence of noise and background irrelevant to the actual target in the input. We present a novel SSL method that addresses this chronic issue by joint slot attention on image and audio. To be specific, two slots competitively attend image and audio features to decompose them into target and off-target representations, and only target representations of image and audio are used for contrastive learning. Also, we introduce cross-modal attention matching to further align local features of image and audio. Our method achieved the best in almost all settings on three public benchmarks for SSL, and substantially outperformed all the prior work in cross-modal retrieval.
Online Temporal Action Localization with Memory-Augmented Transformer
Aug 06, 2024



Online temporal action localization (On-TAL) is the task of identifying multiple action instances given a streaming video. Since existing methods take as input only a video segment of fixed size per iteration, they are limited in considering long-term context and require tuning the segment size carefully. To overcome these limitations, we propose memory-augmented transformer (MATR). MATR utilizes the memory queue that selectively preserves the past segment features, allowing to leverage long-term context for inference. We also propose a novel action localization method that observes the current input segment to predict the end time of the ongoing action and accesses the memory queue to estimate the start time of the action. Our method outperformed existing methods on two datasets, THUMOS14 and MUSES, surpassing not only TAL methods in the online setting but also some offline TAL methods.
Towards More Practical Group Activity Detection: A New Benchmark and Model
Dec 05, 2023
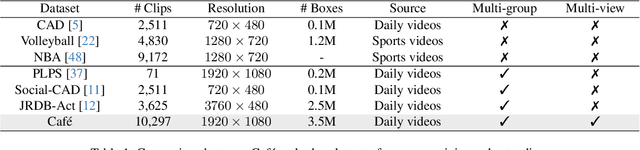
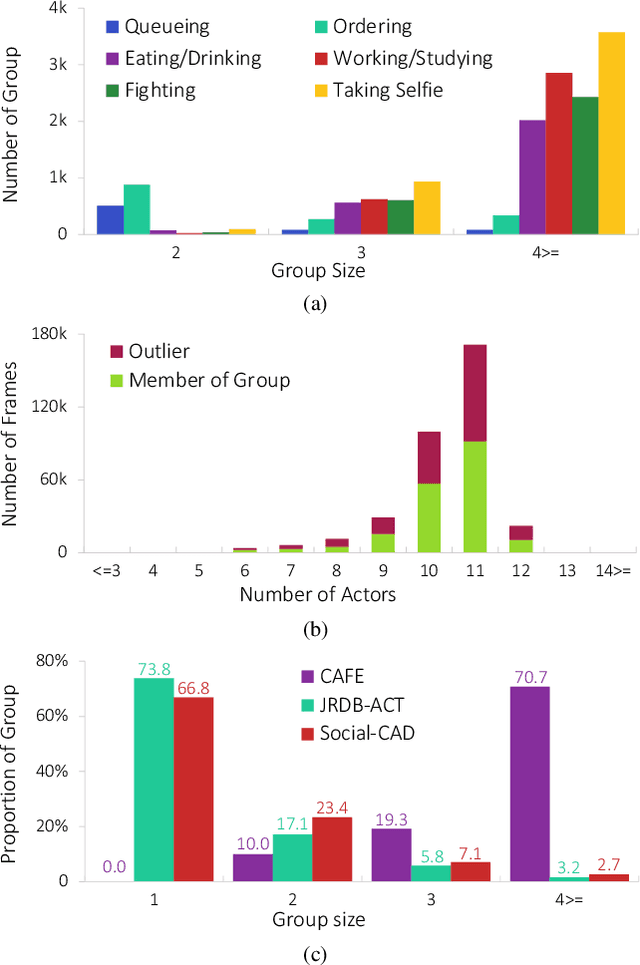
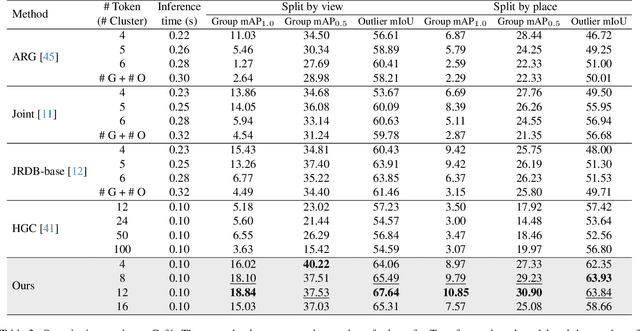
Group activity detection (GAD) is the task of identifying members of each group and classifying the activity of the group at the same time in a video. While GAD has been studied recently, there is still much room for improvement in both dataset and methodology due to their limited capability to address practical GAD scenarios. To resolve these issues, we first present a new dataset, dubbed Caf\'e. Unlike existing datasets, Caf\'e is constructed primarily for GAD and presents more practical evaluation scenarios and metrics, as well as being large-scale and providing rich annotations. Along with the dataset, we propose a new GAD model that deals with an unknown number of groups and latent group members efficiently and effectively. We evaluated our model on three datasets including Caf\'e, where it outperformed previous work in terms of both accuracy and inference speed. Both our dataset and code base will be open to the public to promote future research on GAD.