 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoCoGaussian: Leveraging Circle of Confusion for Gaussian Splatting from Defocused Images
Dec 20, 2024



3D Gaussian Splatting (3DGS) has attracted significant attention for its high-quality novel view rendering, inspiring research to address real-world challenges. While conventional methods depend on sharp images for accurate scene reconstruction, real-world scenarios are often affected by defocus blur due to finite depth of field, making it essential to account for realistic 3D scene representation. In this study, we propose CoCoGaussian, a Circle of Confusion-aware Gaussian Splatting that enables precise 3D scene representation using only defocused images. CoCoGaussian addresses the challenge of defocus blur by modeling the Circle of Confusion (CoC) through a physically grounded approach based on the principles of photographic defocus. Exploiting 3D Gaussians, we compute the CoC diameter from depth and learnable aperture information, generating multiple Gaussians to precisely capture the CoC shape. Furthermore, we introduce a learnable scaling factor to enhance robustness and provide more flexibility in handling unreliable depth in scenes with reflective or refractive surfaces. Experiments on both synthetic and real-world datasets demonstrate that CoCoGaussian achieves state-of-the-art performance across multiple benchmarks.
Self-Supervised Depth Estimation with Isometric-Self-Sample-Based Learning
May 20, 2022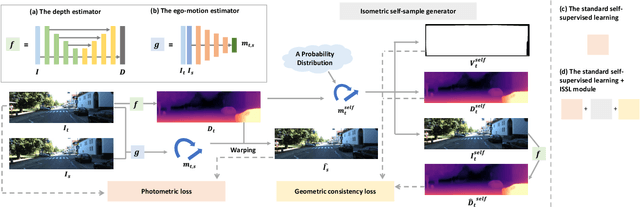
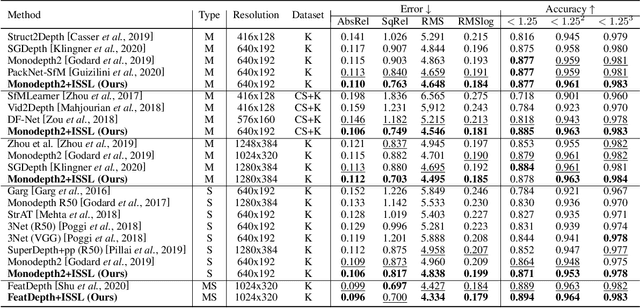
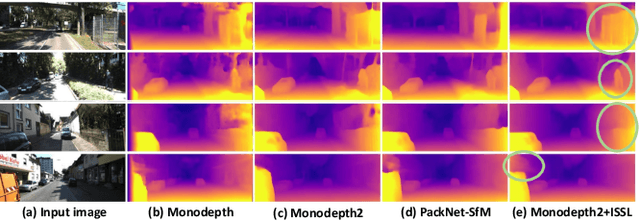
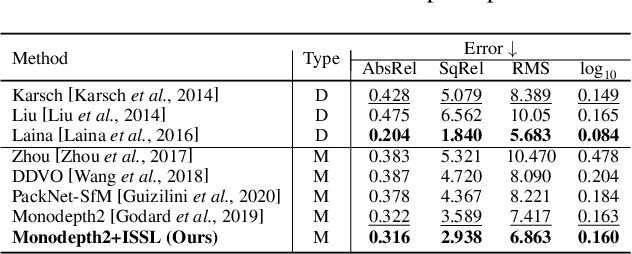
Managing the dynamic regions in the photometric loss formulation has been a main issue for handling the self-supervised depth estimation problem. Most previous methods have alleviated this issue by removing the dynamic regions in the photometric loss formulation based on the masks estimated from another module, making it difficult to fully utilize the training images. In this paper, to handle this problem, we propose an isometric self-sample-based learning (ISSL) method to fully utilize the training images in a simple yet effective way. The proposed method provides additional supervision during training using self-generated images that comply with pure static scene assumption. Specifically, the isometric self-sample generator synthesizes self-samples for each training image by applying random rigid transformations on the estimated depth. Thus both the generated self-samples and the corresponding training image always follow the static scene assumption. We show that plugging our ISSL module into several existing models consistently improves the performance by a large margin. In addition, it also boosts the depth accuracy over different types of scene, i.e., outdoor scenes (KITTI and Make3D) and indoor scene (NYUv2), validating its high effectiveness.
Propose-and-Attend Single Shot Detector
Jul 30, 2019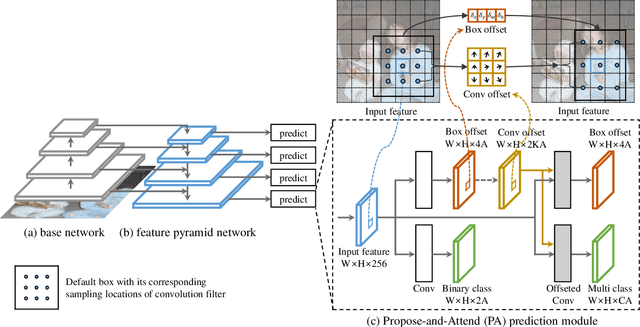

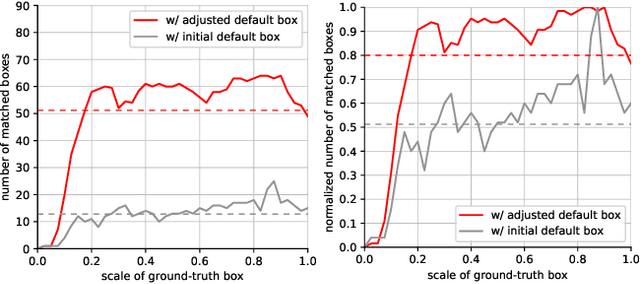
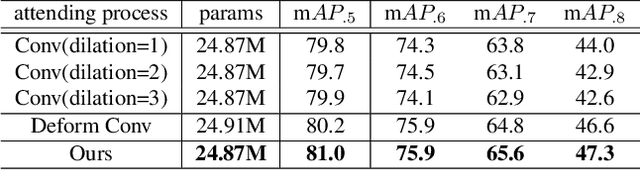
We present a simple yet effective prediction module for a one-stage detector. The main process is conducted in a coarse-to-fine manner. First, the module roughly adjusts the default boxes to well capture the extent of target objects in an image. Second, given the adjusted boxes, the module aligns the receptive field of the convolution filters accordingly, not requiring any embedding layers. Both steps build a propose-and-attend mechanism, mimicking two-stage detectors in a highly efficient manner. To verify its effectiveness, we apply the proposed module to a basic one-stage detector SSD. Our final model achieves an accuracy comparable to that of state-of-the-art detectors while using a fraction of their model parameters and computational overheads. Moreover, we found that the proposed module has two strong applications. 1) The module can be successfully integrated into a lightweight backbone, further pushing the efficiency of the one-stage detector. 2) The module also allows train-from-scratch without relying on any sophisticated base networks as previous methods do.