 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTwo-stream Spatiotemporal Feature for Video QA Task
Jul 11, 2019
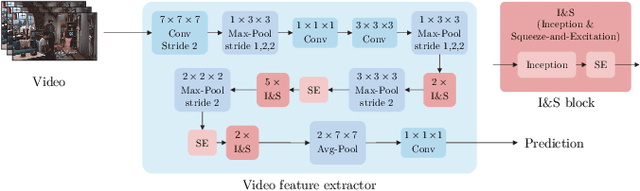
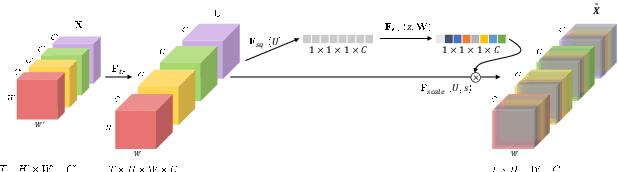

Understanding the content of videos is one of the core techniques for developing various helpful applications in the real world, such as recognizing various human actions for surveillance systems or customer behavior analysis in an autonomous shop. However, understanding the content or story of the video still remains a challenging problem due to its sheer amount of data and temporal structure. In this paper, we propose a multi-channel neural network structure that adopts a two-stream network structure, which has been shown high performance in human action recognition field, and use it as a spatiotemporal video feature extractor for solving video question and answering task. We also adopt a squeeze-and-excitation structure to two-stream network structure for achieving a channel-wise attended spatiotemporal feature. For jointly modeling the spatiotemporal features from video and the textual features from the question, we design a context matching module with a level adjusting layer to remove the gap of information between visual and textual features by applying attention mechanism on joint modeling. Finally, we adopt a scoring mechanism and smoothed ranking loss objective function for selecting the correct answer from answer candidates. We evaluate our model with TVQA dataset, and our approach shows the improved result in textual only setting, but the result with visual feature shows the limitation and possibility of our approach.