 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Third Monocular Depth Estimation Challenge
Apr 27, 2024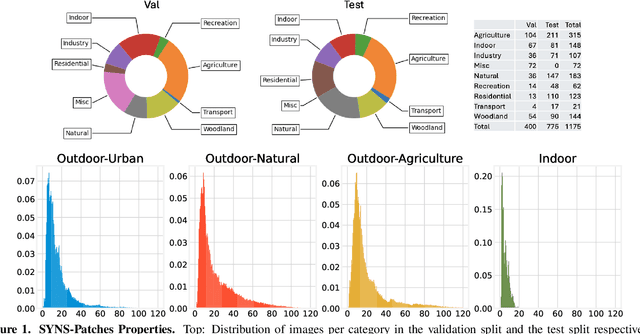

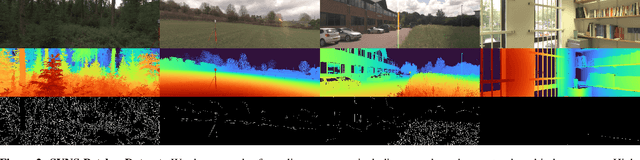
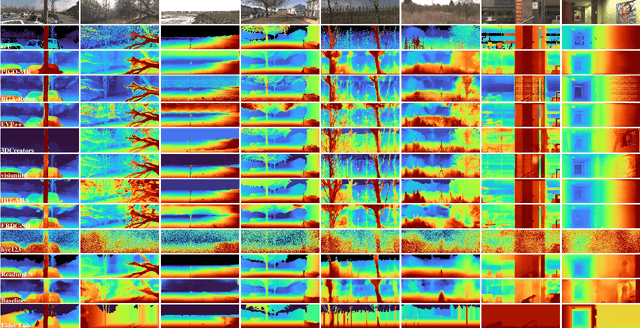
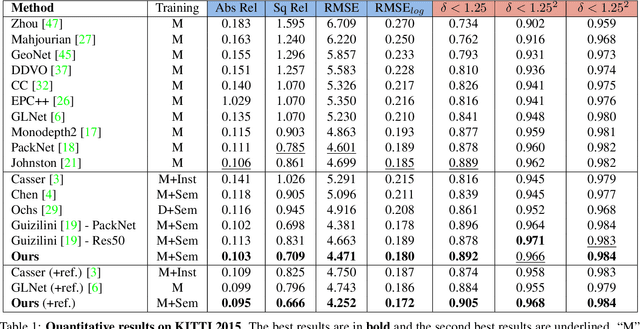
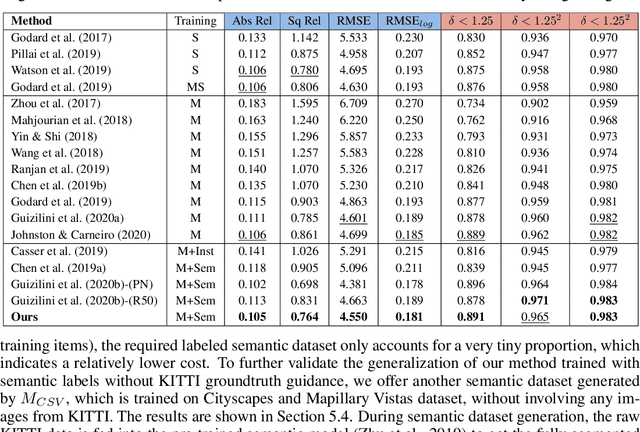
This paper discusses the results of the third edition of the Monocular Depth Estimation Challenge (MDEC). The challenge focuses on zero-shot generalization to the challenging SYNS-Patches dataset, featuring complex scenes in natural and indoor settings. As with the previous edition, methods can use any form of supervision, i.e. supervised or self-supervised. The challenge received a total of 19 submissions outperforming the baseline on the test set: 10 among them submitted a report describing their approach, highlighting a diffused use of foundational models such as Depth Anything at the core of their method. The challenge winners drastically improved 3D F-Score performance, from 17.51% to 23.72%.
Learning Depth via Leveraging Semantics: Self-supervised Monocular Depth Estimation with Both Implicit and Explicit Semantic Guidance
Feb 11, 2021
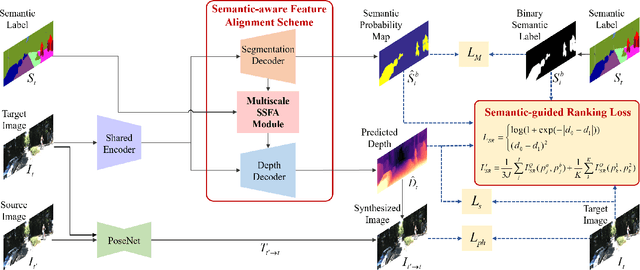

Self-supervised depth estimation has made a great success in learning depth from unlabeled image sequences. While the mappings between image and pixel-wise depth are well-studied in current methods, the correlation between image, depth and scene semantics, however, is less considered. This hinders the network to better understand the real geometry of the scene, since the contextual clues, contribute not only the latent representations of scene depth, but also the straight constraints for depth map. In this paper, we leverage the two benefits by proposing the implicit and explicit semantic guidance for accurate self-supervised depth estimation. We propose a Semantic-aware Spatial Feature Alignment (SSFA) scheme to effectively align implicit semantic features with depth features for scene-aware depth estimation. We also propose a semantic-guided ranking loss to explicitly constrain the estimated depth maps to be consistent with real scene contextual properties. Both semantic label noise and prediction uncertainty is considered to yield reliable depth supervisions. Extensive experimental results show that our method produces high quality depth maps which are consistently superior either on complex scenes or diverse semantic categories, and outperforms the state-of-the-art methods by a significant margin.
Semantic-Guided Representation Enhancement for Self-supervised Monocular Trained Depth Estimation
Dec 15, 2020
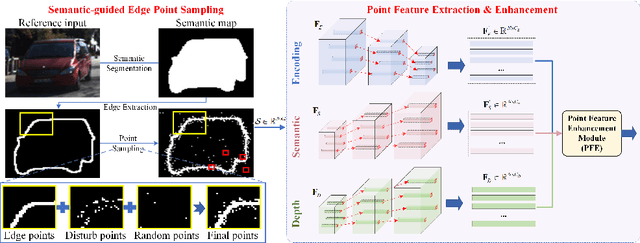

Self-supervised depth estimation has shown its great effectiveness in producing high quality depth maps given only image sequences as input. However, its performance usually drops when estimating on border areas or objects with thin structures due to the limited depth representation ability. In this paper, we address this problem by proposing a semantic-guided depth representation enhancement method, which promotes both local and global depth feature representations by leveraging rich contextual information. In stead of a single depth network as used in conventional paradigms, we propose an extra semantic segmentation branch to offer extra contextual features for depth estimation. Based on this framework, we enhance the local feature representation by sampling and feeding the point-based features that locate on the semantic edges to an individual Semantic-guided Edge Enhancement module (SEEM), which is specifically designed for promoting depth estimation on the challenging semantic borders. Then, we improve the global feature representation by proposing a semantic-guided multi-level attention mechanism, which enhances the semantic and depth features by exploring pixel-wise correlations in the multi-level depth decoding scheme. Extensive experiments validate the distinct superiority of our method in capturing highly accurate depth on the challenging image areas such as semantic category borders and thin objects. Both quantitative and qualitative experiments on KITTI show that our method outperforms the state-of-the-art methods.