 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM-Driven Medical Document Analysis: Enhancing Trustworthy Pathology and Differential Diagnosis
Jun 24, 2025Medical document analysis plays a crucial role in extracting essential clinical insights from unstructured healthcare records, supporting critical tasks such as differential diagnosis. Determining the most probable condition among overlapping symptoms requires precise evaluation and deep medical expertise. While recent advancements in large language models (LLMs) have significantly enhanced performance in medical document analysis, privacy concerns related to sensitive patient data limit the use of online LLMs services in clinical settings. To address these challenges, we propose a trustworthy medical document analysis platform that fine-tunes a LLaMA-v3 using low-rank adaptation, specifically optimized for differential diagnosis tasks. Our approach utilizes DDXPlus, the largest benchmark dataset for differential diagnosis, and demonstrates superior performance in pathology prediction and variable-length differential diagnosis compared to existing methods. The developed web-based platform allows users to submit their own unstructured medical documents and receive accurate, explainable diagnostic results. By incorporating advanced explainability techniques, the system ensures transparent and reliable predictions, fostering user trust and confidence. Extensive evaluations confirm that the proposed method surpasses current state-of-the-art models in predictive accuracy while offering practical utility in clinical settings. This work addresses the urgent need for reliable, explainable, and privacy-preserving artificial intelligence solutions, representing a significant advancement in intelligent medical document analysis for real-world healthcare applications. The code can be found at \href{https://github.com/leitro/Differential-Diagnosis-LoRA}{https://github.com/leitro/Differential-Diagnosis-LoRA}.
xLSTM-ECG: Multi-label ECG Classification via Feature Fusion with xLSTM
Apr 14, 2025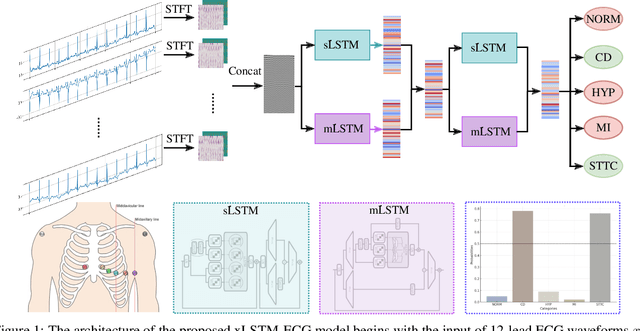
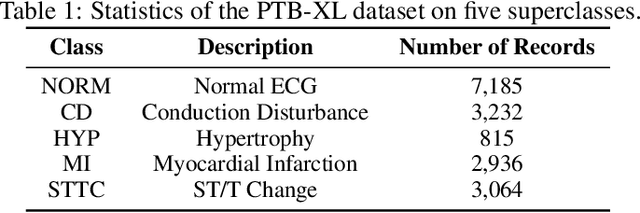
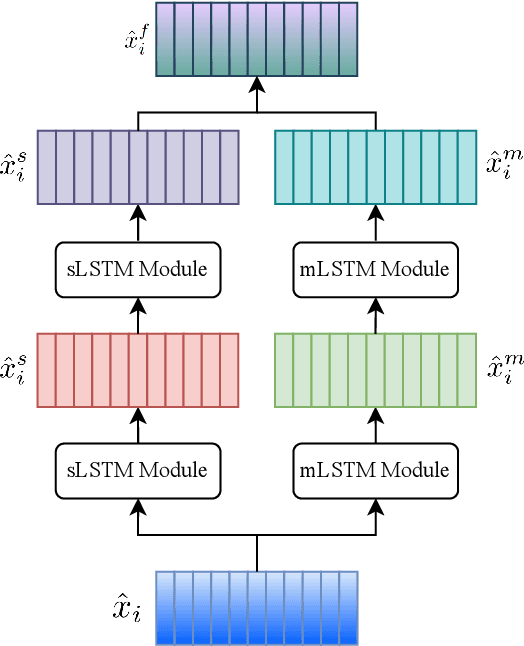

Cardiovascular diseases (CVDs) remain the leading cause of mortality worldwide, highlighting the critical need for efficient and accurate diagnostic tools. Electrocardiograms (ECGs) are indispensable in diagnosing various heart conditions; however, their manual interpretation is time-consuming and error-prone. In this paper, we propose xLSTM-ECG, a novel approach that leverages an extended Long Short-Term Memory (xLSTM) network for multi-label classification of ECG signals, using the PTB-XL dataset. To the best of our knowledge, this work represents the first design and application of xLSTM modules specifically adapted for multi-label ECG classification. Our method employs a Short-Time Fourier Transform (STFT) to convert time-series ECG waveforms into the frequency domain, thereby enhancing feature extraction. The xLSTM architecture is specifically tailored to address the complexities of 12-lead ECG recordings by capturing both local and global signal features. Comprehensive experiments on the PTB-XL dataset reveal that our model achieves strong multi-label classification performance, while additional tests on the Georgia 12-Lead dataset underscore its robustness and efficiency. This approach significantly improves ECG classification accuracy, thereby advancing clinical diagnostics and patient care. The code will be publicly available upon acceptance.
Preserving Privacy Without Compromising Accuracy: Machine Unlearning for Handwritten Text Recognition
Apr 11, 2025



Handwritten Text Recognition (HTR) is essential for document analysis and digitization. However, handwritten data often contains user-identifiable information, such as unique handwriting styles and personal lexicon choices, which can compromise privacy and erode trust in AI services. Legislation like the ``right to be forgotten'' underscores the necessity for methods that can expunge sensitive information from trained models. Machine unlearning addresses this by selectively removing specific data from models without necessitating complete retraining. Yet, it frequently encounters a privacy-accuracy tradeoff, where safeguarding privacy leads to diminished model performance. In this paper, we introduce a novel two-stage unlearning strategy for a multi-head transformer-based HTR model, integrating pruning and random labeling. Our proposed method utilizes a writer classification head both as an indicator and a trigger for unlearning, while maintaining the efficacy of the recognition head. To our knowledge, this represents the first comprehensive exploration of machine unlearning within HTR tasks. We further employ Membership Inference Attacks (MIA) to evaluate the effectiveness of unlearning user-identifiable information. Extensive experiments demonstrate that our approach effectively preserves privacy while maintaining model accuracy, paving the way for new research directions in the document analysis community. Our code will be publicly available upon acceptance.
Bit-depth color recovery via off-the-shelf super-resolution models
Jan 09, 2025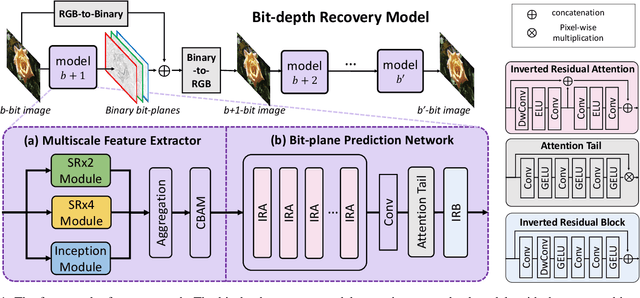

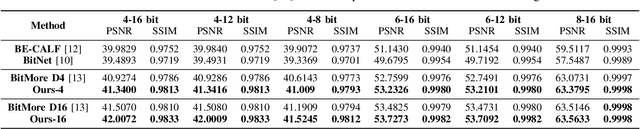
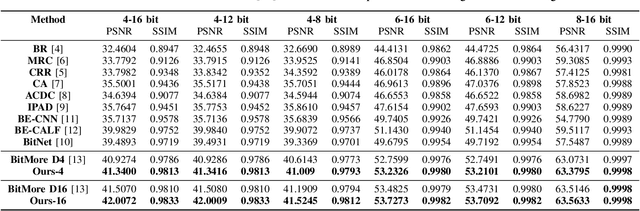
Advancements in imaging technology have enabled hardware to support 10 to 16 bits per channel, facilitating precise manipulation in applications like image editing and video processing. While deep neural networks promise to recover high bit-depth representations, existing methods often rely on scale-invariant image information, limiting performance in certain scenarios. In this paper, we introduce a novel approach that integrates a super-resolution architecture to extract detailed a priori information from images. By leveraging interpolated data generated during the super-resolution process, our method achieves pixel-level recovery of fine-grained color details. Additionally, we demonstrate that spatial features learned through the super-resolution process significantly contribute to the recovery of detailed color depth information. Experiments on benchmark datasets demonstrate that our approach outperforms state-of-the-art methods, highlighting the potential of super-resolution for high-fidelity color restoration.