 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraphDOP: Towards skilful data-driven medium-range weather forecasts learnt and initialised directly from observations
Dec 20, 2024We introduce GraphDOP, a new data-driven, end-to-end forecast system developed at the European Centre for Medium-Range Weather Forecasts (ECMWF) that is trained and initialised exclusively from Earth System observations, with no physics-based (re)analysis inputs or feedbacks. GraphDOP learns the correlations between observed quantities - such as brightness temperatures from polar orbiters and geostationary satellites - and geophysical quantities of interest (that are measured by conventional observations), to form a coherent latent representation of Earth System state dynamics and physical processes, and is capable of producing skilful predictions of relevant weather parameters up to five days into the future.
Hydra-LSTM: A semi-shared Machine Learning architecture for prediction across Watersheds
Oct 21, 2024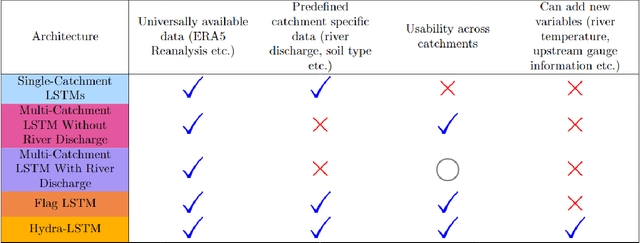
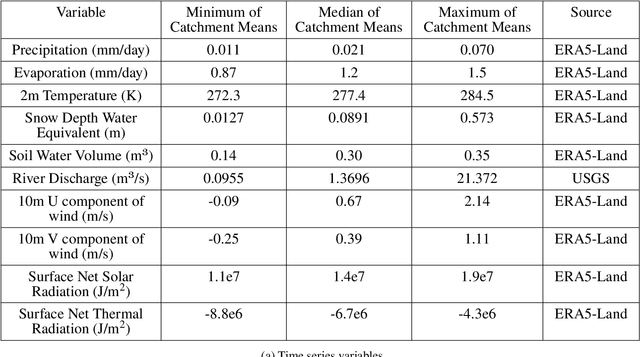
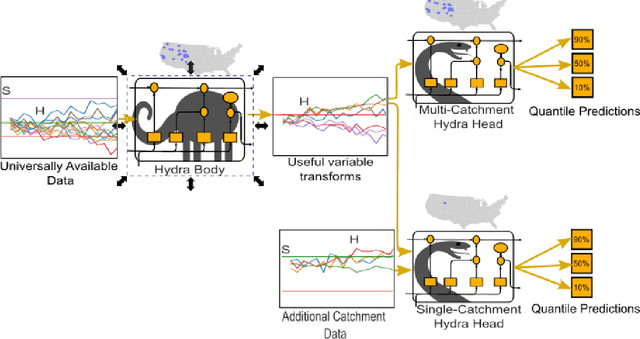
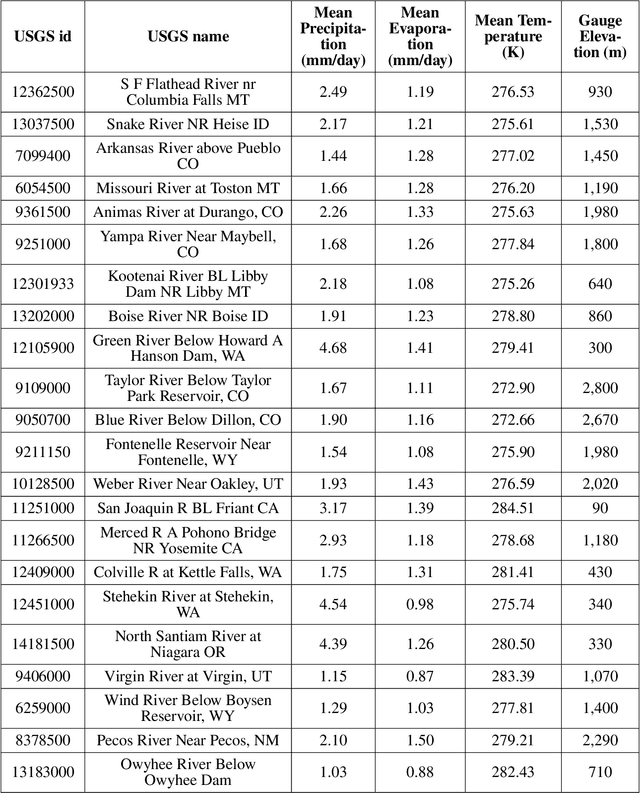
Long Short Term Memory networks (LSTMs) are used to build single models that predict river discharge across many catchments. These models offer greater accuracy than models trained on each catchment independently if using the same data. However, the same data is rarely available for all catchments. This prevents the use of variables available only in some catchments, such as historic river discharge or upstream discharge. The only existing method that allows for optional variables requires all variables to be considered in the initial training of the model, limiting its transferability to new catchments. To address this limitation, we develop the Hydra-LSTM. The Hydra-LSTM processes variables used across all catchments and variables used in only some catchments separately to allow general training and use of catchment-specific data in individual catchments. The bulk of the model can be shared across catchments, maintaining the benefits of multi-catchment models to generalise, while also benefitting from the advantages of using bespoke data. We apply this methodology to 1 day-ahead river discharge prediction in the Western US, as next-day river discharge prediction is the first step towards prediction across longer time scales. We obtain state-of-the-art performance, generating more accurate median and quantile predictions than Multi-Catchment and Single-Catchment LSTMs while allowing local forecasters to easily introduce and remove variables from their prediction set. We test the ability of the Hydra-LSTM to incorporate catchment-specific data by introducing historical river discharge as a catchment-specific input, outperforming state-of-the-art models without needing to train an entirely new model.
Robustness of AI-based weather forecasts in a changing climate
Sep 27, 2024


Data-driven machine learning models for weather forecasting have made transformational progress in the last 1-2 years, with state-of-the-art ones now outperforming the best physics-based models for a wide range of skill scores. Given the strong links between weather and climate modelling, this raises the question whether machine learning models could also revolutionize climate science, for example by informing mitigation and adaptation to climate change or to generate larger ensembles for more robust uncertainty estimates. Here, we show that current state-of-the-art machine learning models trained for weather forecasting in present-day climate produce skillful forecasts across different climate states corresponding to pre-industrial, present-day, and future 2.9K warmer climates. This indicates that the dynamics shaping the weather on short timescales may not differ fundamentally in a changing climate. It also demonstrates out-of-distribution generalization capabilities of the machine learning models that are a critical prerequisite for climate applications. Nonetheless, two of the models show a global-mean cold bias in the forecasts for the future warmer climate state, i.e. they drift towards the colder present-day climate they have been trained for. A similar result is obtained for the pre-industrial case where two out of three models show a warming. We discuss possible remedies for these biases and analyze their spatial distribution, revealing complex warming and cooling patterns that are partly related to missing ocean-sea ice and land surface information in the training data. Despite these current limitations, our results suggest that data-driven machine learning models will provide powerful tools for climate science and transform established approaches by complementing conventional physics-based models.
Regional data-driven weather modeling with a global stretched-grid
Sep 04, 2024A data-driven model (DDM) suitable for regional weather forecasting applications is presented. The model extends the Artificial Intelligence Forecasting System by introducing a stretched-grid architecture that dedicates higher resolution over a regional area of interest and maintains a lower resolution elsewhere on the globe. The model is based on graph neural networks, which naturally affords arbitrary multi-resolution grid configurations. The model is applied to short-range weather prediction for the Nordics, producing forecasts at 2.5 km spatial and 6 h temporal resolution. The model is pre-trained on 43 years of global ERA5 data at 31 km resolution and is further refined using 3.3 years of 2.5 km resolution operational analyses from the MetCoOp Ensemble Prediction System (MEPS). The performance of the model is evaluated using surface observations from measurement stations across Norway and is compared to short-range weather forecasts from MEPS. The DDM outperforms both the control run and the ensemble mean of MEPS for 2 m temperature. The model also produces competitive precipitation and wind speed forecasts, but is shown to underestimate extreme events.
Distilling Machine Learning's Added Value: Pareto Fronts in Atmospheric Applications
Aug 04, 2024While the added value of machine learning (ML) for weather and climate applications is measurable, explaining it remains challenging, especially for large deep learning models. Inspired by climate model hierarchies, we propose that a full hierarchy of Pareto-optimal models, defined within an appropriately determined error-complexity plane, can guide model development and help understand the models' added value. We demonstrate the use of Pareto fronts in atmospheric physics through three sample applications, with hierarchies ranging from semi-empirical models with minimal tunable parameters (simplest) to deep learning algorithms (most complex). First, in cloud cover parameterization, we find that neural networks identify nonlinear relationships between cloud cover and its thermodynamic environment, and assimilate previously neglected features such as vertical gradients in relative humidity that improve the representation of low cloud cover. This added value is condensed into a ten-parameter equation that rivals the performance of deep learning models. Second, we establish a ML model hierarchy for emulating shortwave radiative transfer, distilling the importance of bidirectional vertical connectivity for accurately representing absorption and scattering, especially for multiple cloud layers. Third, we emphasize the importance of convective organization information when modeling the relationship between tropical precipitation and its surrounding environment. We discuss the added value of temporal memory when high-resolution spatial information is unavailable, with implications for precipitation parameterization. Therefore, by comparing data-driven models directly with existing schemes using Pareto optimality, we promote process understanding by hierarchically unveiling system complexity, with the hope of improving the trustworthiness of ML models in atmospheric applications.
Advances in Land Surface Model-based Forecasting: A comparative study of LSTM, Gradient Boosting, and Feedforward Neural Network Models as prognostic state emulators
Jul 23, 2024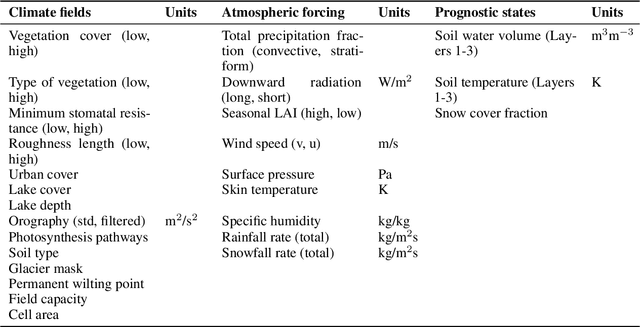
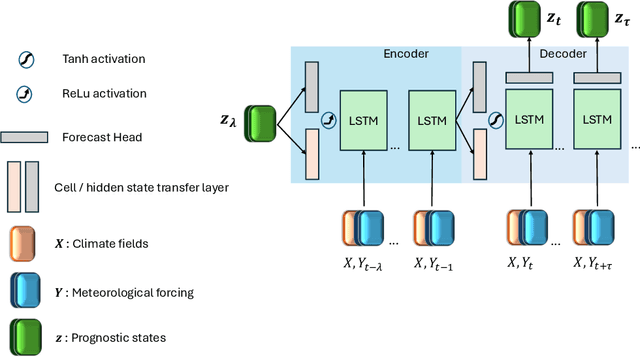
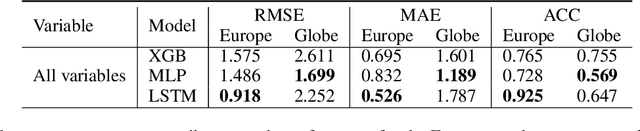
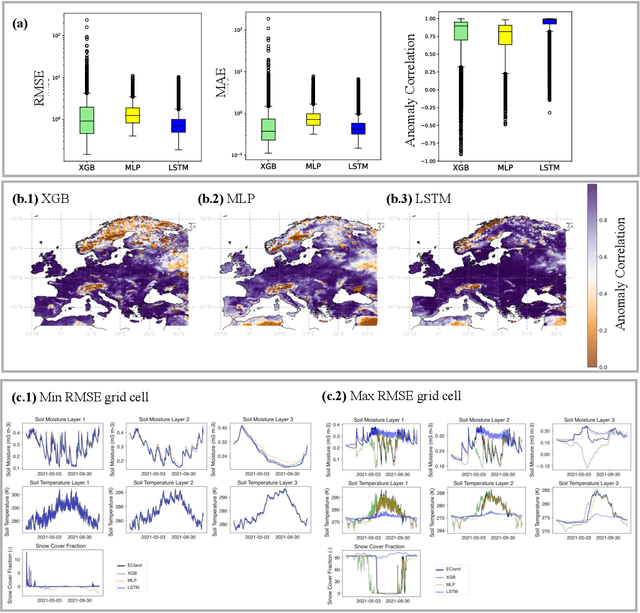
Most useful weather prediction for the public is near the surface. The processes that are most relevant for near-surface weather prediction are also those that are most interactive and exhibit positive feedback or have key role in energy partitioning. Land surface models (LSMs) consider these processes together with surface heterogeneity and forecast water, carbon and energy fluxes, and coupled with an atmospheric model provide boundary and initial conditions. This numerical parametrization of atmospheric boundaries being computationally expensive, statistical surrogate models are increasingly used to accelerated progress in experimental research. We evaluated the efficiency of three surrogate models in speeding up experimental research by simulating land surface processes, which are integral to forecasting water, carbon, and energy fluxes in coupled atmospheric models. Specifically, we compared the performance of a Long-Short Term Memory (LSTM) encoder-decoder network, extreme gradient boosting, and a feed-forward neural network within a physics-informed multi-objective framework. This framework emulates key states of the ECMWF's Integrated Forecasting System (IFS) land surface scheme, ECLand, across continental and global scales. Our findings indicate that while all models on average demonstrate high accuracy over the forecast period, the LSTM network excels in continental long-range predictions when carefully tuned, the XGB scores consistently high across tasks and the MLP provides an excellent implementation-time-accuracy trade-off. The runtime reduction achieved by the emulators in comparison to the full numerical models are significant, offering a faster, yet reliable alternative for conducting numerical experiments on land surfaces.
Data driven weather forecasts trained and initialised directly from observations
Jul 22, 2024Skilful Machine Learned weather forecasts have challenged our approach to numerical weather prediction, demonstrating competitive performance compared to traditional physics-based approaches. Data-driven systems have been trained to forecast future weather by learning from long historical records of past weather such as the ECMWF ERA5. These datasets have been made freely available to the wider research community, including the commercial sector, which has been a major factor in the rapid rise of ML forecast systems and the levels of accuracy they have achieved. However, historical reanalyses used for training and real-time analyses used for initial conditions are produced by data assimilation, an optimal blending of observations with a physics-based forecast model. As such, many ML forecast systems have an implicit and unquantified dependence on the physics-based models they seek to challenge. Here we propose a new approach, training a neural network to predict future weather purely from historical observations with no dependence on reanalyses. We use raw observations to initialise a model of the atmosphere (in observation space) learned directly from the observations themselves. Forecasts of crucial weather parameters (such as surface temperature and wind) are obtained by predicting weather parameter observations (e.g. SYNOP surface data) at future times and arbitrary locations. We present preliminary results on forecasting observations 12-hours into the future. These already demonstrate successful learning of time evolutions of the physical processes captured in real observations. We argue that this new approach, by staying purely in observation space, avoids many of the challenges of traditional data assimilation, can exploit a wider range of observations and is readily expanded to simultaneous forecasting of the full Earth system (atmosphere, land, ocean and composition).
WeatherBench 2: A benchmark for the next generation of data-driven global weather models
Aug 29, 2023WeatherBench 2 is an update to the global, medium-range (1-14 day) weather forecasting benchmark proposed by Rasp et al. (2020), designed with the aim to accelerate progress in data-driven weather modeling. WeatherBench 2 consists of an open-source evaluation framework, publicly available training, ground truth and baseline data as well as a continuously updated website with the latest metrics and state-of-the-art models: https://sites.research.google/weatherbench. This paper describes the design principles of the evaluation framework and presents results for current state-of-the-art physical and data-driven weather models. The metrics are based on established practices for evaluating weather forecasts at leading operational weather centers. We define a set of headline scores to provide an overview of model performance. In addition, we also discuss caveats in the current evaluation setup and challenges for the future of data-driven weather forecasting.
A Generative Deep Learning Approach to Stochastic Downscaling of Precipitation Forecasts
Apr 05, 2022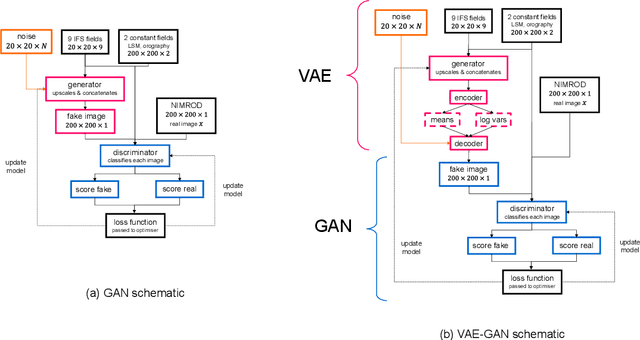
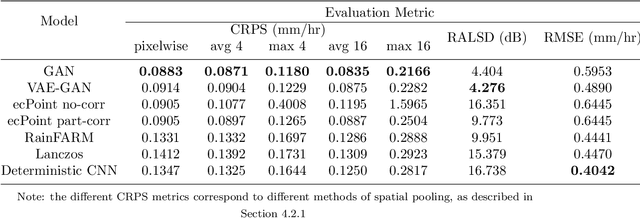
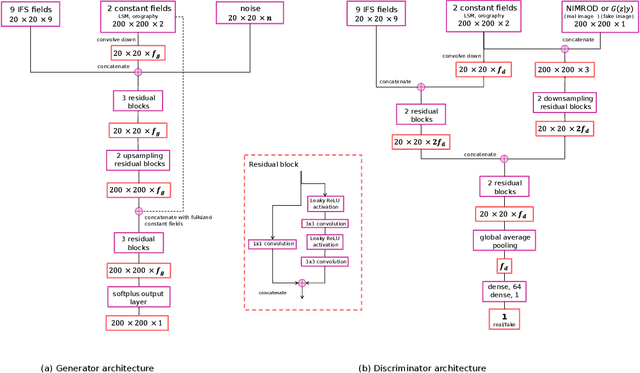
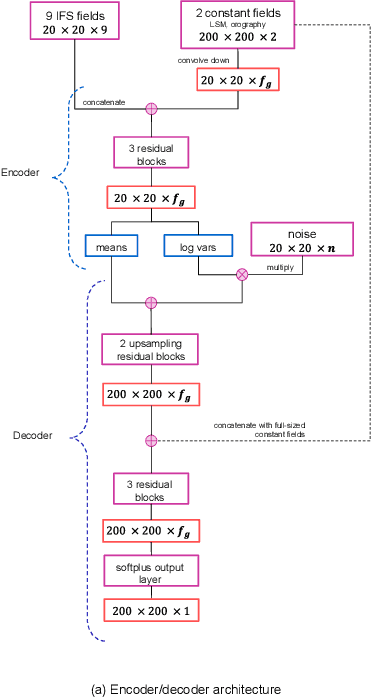
Despite continuous improvements, precipitation forecasts are still not as accurate and reliable as those of other meteorological variables. A major contributing factor to this is that several key processes affecting precipitation distribution and intensity occur below the resolved scale of global weather models. Generative adversarial networks (GANs) have been demonstrated by the computer vision community to be successful at super-resolution problems, i.e., learning to add fine-scale structure to coarse images. Leinonen et al. (2020) previously applied a GAN to produce ensembles of reconstructed high-resolution atmospheric fields, given coarsened input data. In this paper, we demonstrate this approach can be extended to the more challenging problem of increasing the accuracy and resolution of comparatively low-resolution input from a weather forecasting model, using high-resolution radar measurements as a "ground truth". The neural network must learn to add resolution and structure whilst accounting for non-negligible forecast error. We show that GANs and VAE-GANs can match the statistical properties of state-of-the-art pointwise post-processing methods whilst creating high-resolution, spatially coherent precipitation maps. Our model compares favourably to the best existing downscaling methods in both pixel-wise and pooled CRPS scores, power spectrum information and rank histograms (used to assess calibration). We test our models and show that they perform in a range of scenarios, including heavy rainfall.
RainBench: Towards Global Precipitation Forecasting from Satellite Imagery
Dec 17, 2020
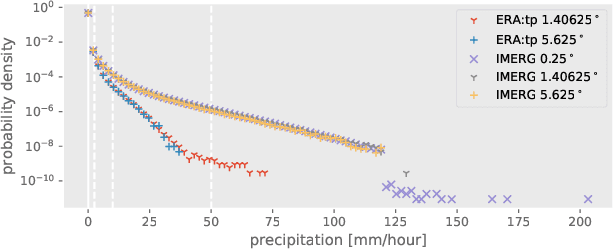
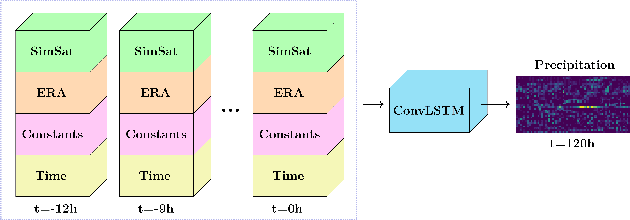
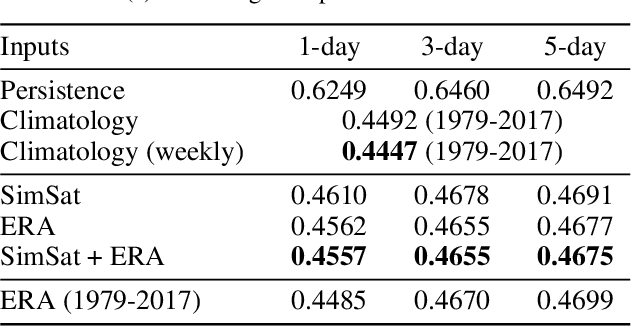
Extreme precipitation events, such as violent rainfall and hail storms, routinely ravage economies and livelihoods around the developing world. Climate change further aggravates this issue. Data-driven deep learning approaches could widen the access to accurate multi-day forecasts, to mitigate against such events. However, there is currently no benchmark dataset dedicated to the study of global precipitation forecasts. In this paper, we introduce \textbf{RainBench}, a new multi-modal benchmark dataset for data-driven precipitation forecasting. It includes simulated satellite data, a selection of relevant meteorological data from the ERA5 reanalysis product, and IMERG precipitation data. We also release \textbf{PyRain}, a library to process large precipitation datasets efficiently. We present an extensive analysis of our novel dataset and establish baseline results for two benchmark medium-range precipitation forecasting tasks. Finally, we discuss existing data-driven weather forecasting methodologies and suggest future research avenues.