 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHydra-LSTM: A semi-shared Machine Learning architecture for prediction across Watersheds
Oct 21, 2024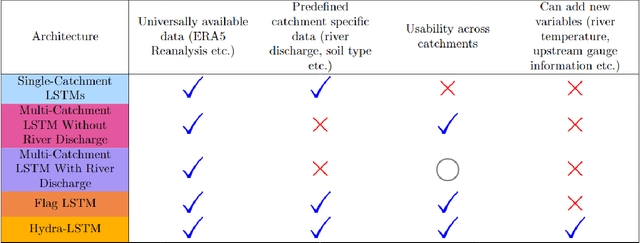
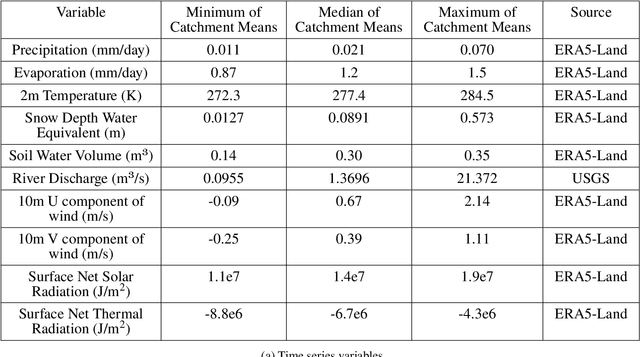
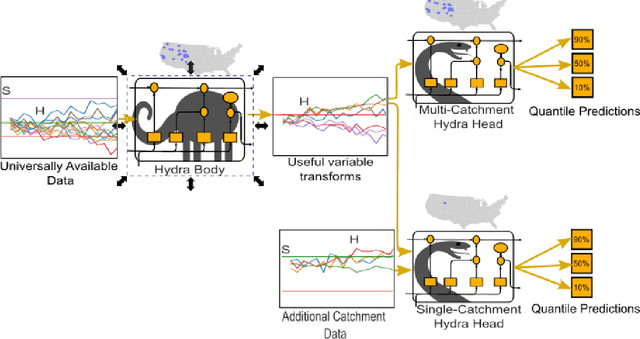
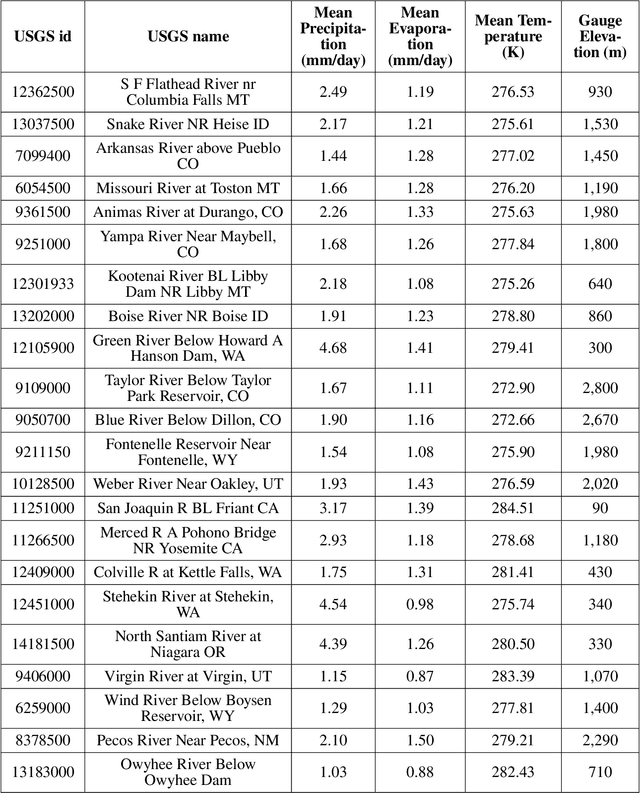
Long Short Term Memory networks (LSTMs) are used to build single models that predict river discharge across many catchments. These models offer greater accuracy than models trained on each catchment independently if using the same data. However, the same data is rarely available for all catchments. This prevents the use of variables available only in some catchments, such as historic river discharge or upstream discharge. The only existing method that allows for optional variables requires all variables to be considered in the initial training of the model, limiting its transferability to new catchments. To address this limitation, we develop the Hydra-LSTM. The Hydra-LSTM processes variables used across all catchments and variables used in only some catchments separately to allow general training and use of catchment-specific data in individual catchments. The bulk of the model can be shared across catchments, maintaining the benefits of multi-catchment models to generalise, while also benefitting from the advantages of using bespoke data. We apply this methodology to 1 day-ahead river discharge prediction in the Western US, as next-day river discharge prediction is the first step towards prediction across longer time scales. We obtain state-of-the-art performance, generating more accurate median and quantile predictions than Multi-Catchment and Single-Catchment LSTMs while allowing local forecasters to easily introduce and remove variables from their prediction set. We test the ability of the Hydra-LSTM to incorporate catchment-specific data by introducing historical river discharge as a catchment-specific input, outperforming state-of-the-art models without needing to train an entirely new model.
Robustness of AI-based weather forecasts in a changing climate
Sep 27, 2024


Data-driven machine learning models for weather forecasting have made transformational progress in the last 1-2 years, with state-of-the-art ones now outperforming the best physics-based models for a wide range of skill scores. Given the strong links between weather and climate modelling, this raises the question whether machine learning models could also revolutionize climate science, for example by informing mitigation and adaptation to climate change or to generate larger ensembles for more robust uncertainty estimates. Here, we show that current state-of-the-art machine learning models trained for weather forecasting in present-day climate produce skillful forecasts across different climate states corresponding to pre-industrial, present-day, and future 2.9K warmer climates. This indicates that the dynamics shaping the weather on short timescales may not differ fundamentally in a changing climate. It also demonstrates out-of-distribution generalization capabilities of the machine learning models that are a critical prerequisite for climate applications. Nonetheless, two of the models show a global-mean cold bias in the forecasts for the future warmer climate state, i.e. they drift towards the colder present-day climate they have been trained for. A similar result is obtained for the pre-industrial case where two out of three models show a warming. We discuss possible remedies for these biases and analyze their spatial distribution, revealing complex warming and cooling patterns that are partly related to missing ocean-sea ice and land surface information in the training data. Despite these current limitations, our results suggest that data-driven machine learning models will provide powerful tools for climate science and transform established approaches by complementing conventional physics-based models.
Advances in Land Surface Model-based Forecasting: A comparative study of LSTM, Gradient Boosting, and Feedforward Neural Network Models as prognostic state emulators
Jul 23, 2024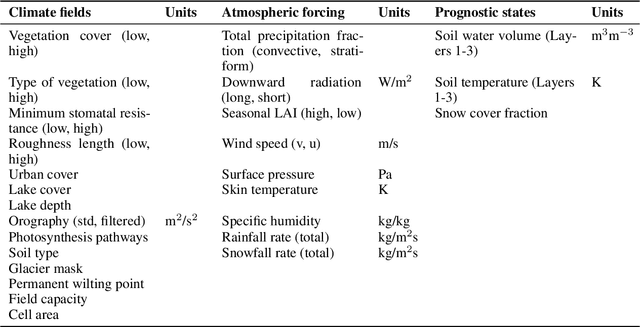
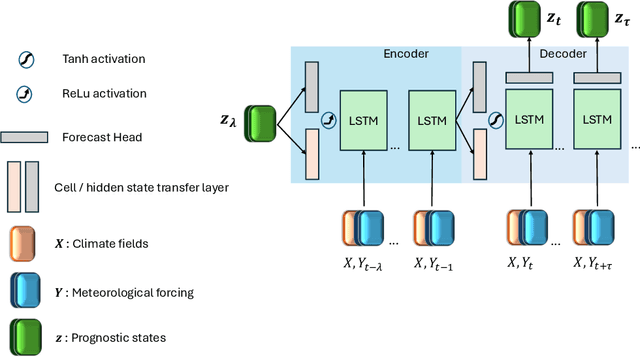
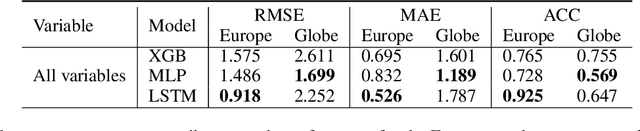
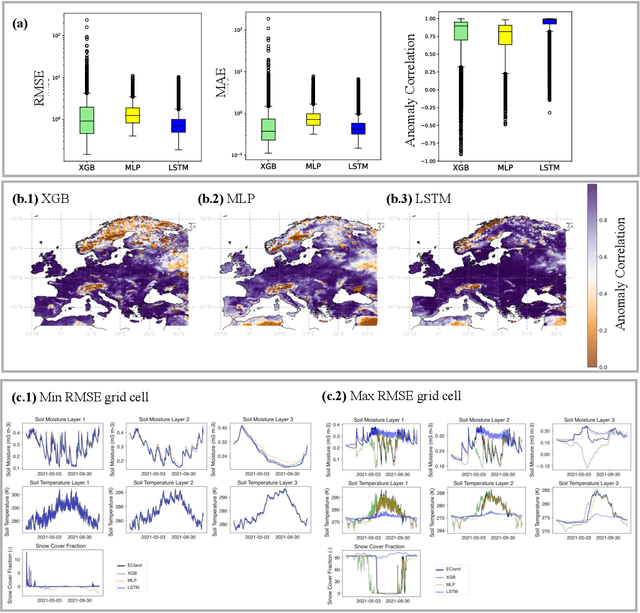
Most useful weather prediction for the public is near the surface. The processes that are most relevant for near-surface weather prediction are also those that are most interactive and exhibit positive feedback or have key role in energy partitioning. Land surface models (LSMs) consider these processes together with surface heterogeneity and forecast water, carbon and energy fluxes, and coupled with an atmospheric model provide boundary and initial conditions. This numerical parametrization of atmospheric boundaries being computationally expensive, statistical surrogate models are increasingly used to accelerated progress in experimental research. We evaluated the efficiency of three surrogate models in speeding up experimental research by simulating land surface processes, which are integral to forecasting water, carbon, and energy fluxes in coupled atmospheric models. Specifically, we compared the performance of a Long-Short Term Memory (LSTM) encoder-decoder network, extreme gradient boosting, and a feed-forward neural network within a physics-informed multi-objective framework. This framework emulates key states of the ECMWF's Integrated Forecasting System (IFS) land surface scheme, ECLand, across continental and global scales. Our findings indicate that while all models on average demonstrate high accuracy over the forecast period, the LSTM network excels in continental long-range predictions when carefully tuned, the XGB scores consistently high across tasks and the MLP provides an excellent implementation-time-accuracy trade-off. The runtime reduction achieved by the emulators in comparison to the full numerical models are significant, offering a faster, yet reliable alternative for conducting numerical experiments on land surfaces.
AI Increases Global Access to Reliable Flood Forecasts
Aug 10, 2023



Floods are one of the most common and impactful natural disasters, with a disproportionate impact in developing countries that often lack dense streamflow monitoring networks. Accurate and timely warnings are critical for mitigating flood risks, but accurate hydrological simulation models typically must be calibrated to long data records in each watershed where they are applied. We developed an Artificial Intelligence (AI) model to predict extreme hydrological events at timescales up to 7 days in advance. This model significantly outperforms current state of the art global hydrology models (the Copernicus Emergency Management Service Global Flood Awareness System) across all continents, lead times, and return periods. AI is especially effective at forecasting in ungauged basins, which is important because only a few percent of the world's watersheds have stream gauges, with a disproportionate number of ungauged basins in developing countries that are especially vulnerable to the human impacts of flooding. We produce forecasts of extreme events in South America and Africa that achieve reliability approaching the current state of the art in Europe and North America, and we achieve reliability at between 4 and 6-day lead times that are similar to current state of the art nowcasts (0-day lead time). Additionally, we achieve accuracies over 10-year return period events that are similar to current accuracies over 2-year return period events, meaning that AI can provide warnings earlier and over larger and more impactful events. The model that we develop in this paper has been incorporated into an operational early warning system that produces publicly available (free and open) forecasts in real time in over 80 countries. This work using AI and open data highlights a need for increasing the availability of hydrological data to continue to improve global access to reliable flood warnings.