 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHydra-LSTM: A semi-shared Machine Learning architecture for prediction across Watersheds
Paper and Code
Oct 21, 2024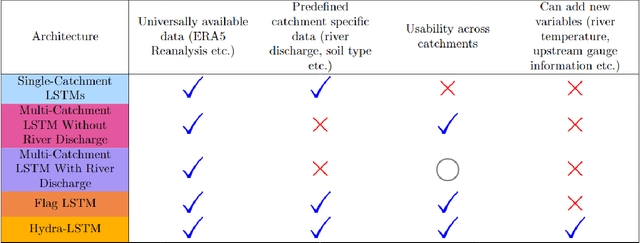
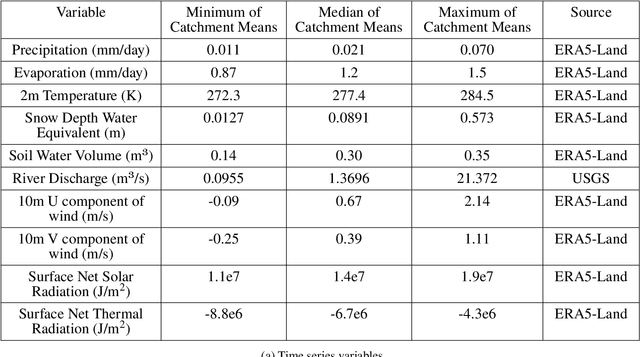
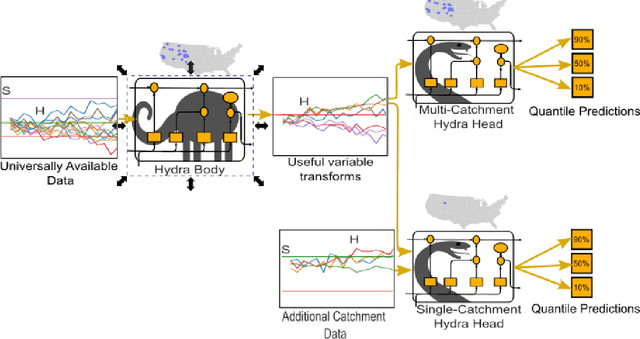
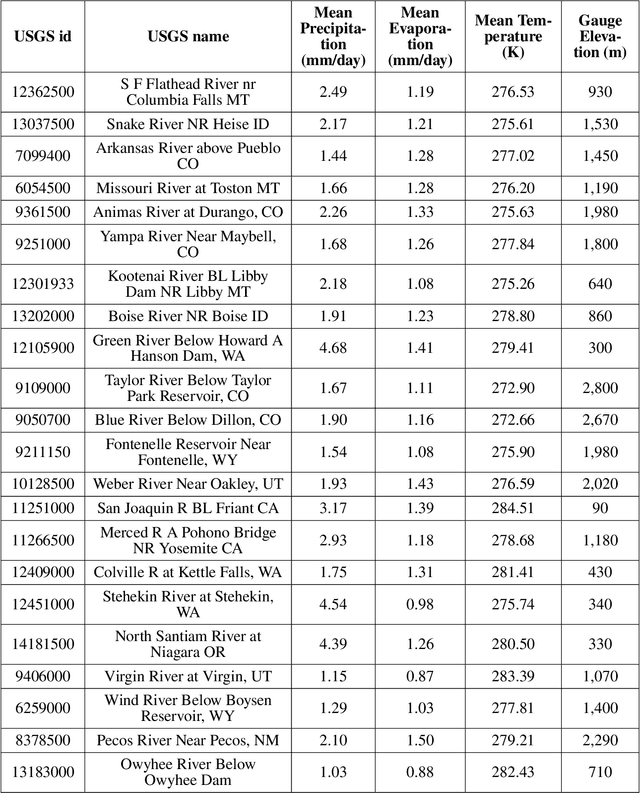
Long Short Term Memory networks (LSTMs) are used to build single models that predict river discharge across many catchments. These models offer greater accuracy than models trained on each catchment independently if using the same data. However, the same data is rarely available for all catchments. This prevents the use of variables available only in some catchments, such as historic river discharge or upstream discharge. The only existing method that allows for optional variables requires all variables to be considered in the initial training of the model, limiting its transferability to new catchments. To address this limitation, we develop the Hydra-LSTM. The Hydra-LSTM processes variables used across all catchments and variables used in only some catchments separately to allow general training and use of catchment-specific data in individual catchments. The bulk of the model can be shared across catchments, maintaining the benefits of multi-catchment models to generalise, while also benefitting from the advantages of using bespoke data. We apply this methodology to 1 day-ahead river discharge prediction in the Western US, as next-day river discharge prediction is the first step towards prediction across longer time scales. We obtain state-of-the-art performance, generating more accurate median and quantile predictions than Multi-Catchment and Single-Catchment LSTMs while allowing local forecasters to easily introduce and remove variables from their prediction set. We test the ability of the Hydra-LSTM to incorporate catchment-specific data by introducing historical river discharge as a catchment-specific input, outperforming state-of-the-art models without needing to train an entirely new model.