 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHydra-LSTM: A semi-shared Machine Learning architecture for prediction across Watersheds
Oct 21, 2024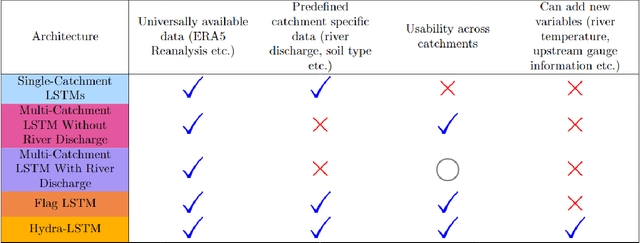
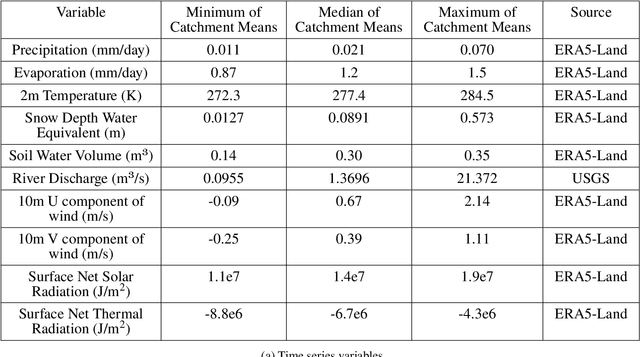
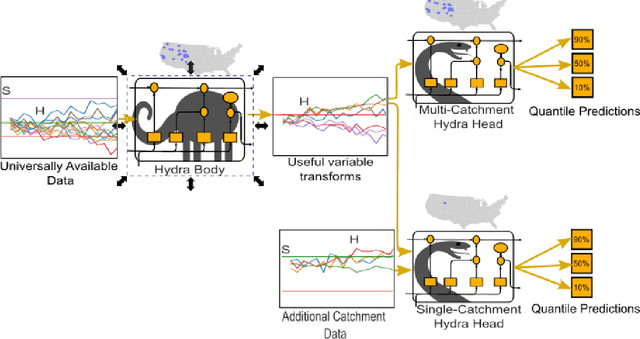
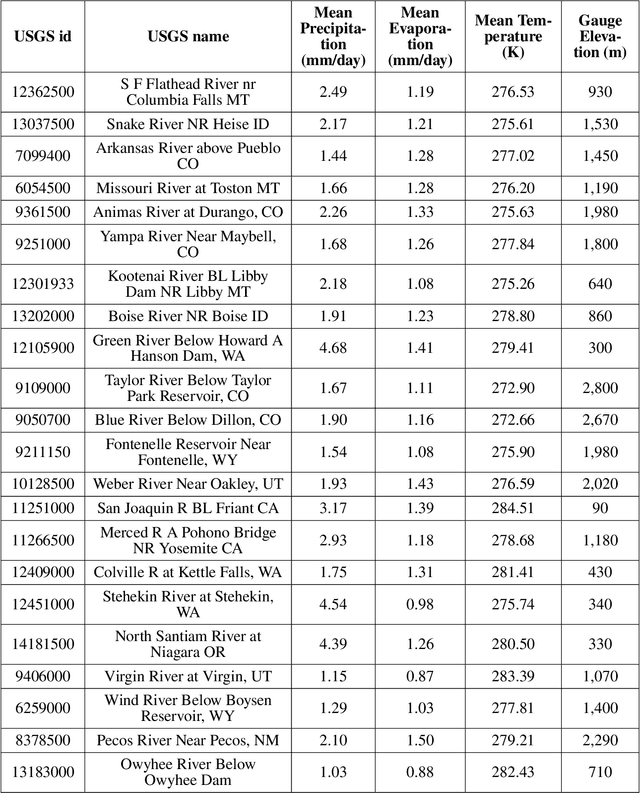
Long Short Term Memory networks (LSTMs) are used to build single models that predict river discharge across many catchments. These models offer greater accuracy than models trained on each catchment independently if using the same data. However, the same data is rarely available for all catchments. This prevents the use of variables available only in some catchments, such as historic river discharge or upstream discharge. The only existing method that allows for optional variables requires all variables to be considered in the initial training of the model, limiting its transferability to new catchments. To address this limitation, we develop the Hydra-LSTM. The Hydra-LSTM processes variables used across all catchments and variables used in only some catchments separately to allow general training and use of catchment-specific data in individual catchments. The bulk of the model can be shared across catchments, maintaining the benefits of multi-catchment models to generalise, while also benefitting from the advantages of using bespoke data. We apply this methodology to 1 day-ahead river discharge prediction in the Western US, as next-day river discharge prediction is the first step towards prediction across longer time scales. We obtain state-of-the-art performance, generating more accurate median and quantile predictions than Multi-Catchment and Single-Catchment LSTMs while allowing local forecasters to easily introduce and remove variables from their prediction set. We test the ability of the Hydra-LSTM to incorporate catchment-specific data by introducing historical river discharge as a catchment-specific input, outperforming state-of-the-art models without needing to train an entirely new model.
Mitigating Algorithmic Bias on Facial Expression Recognition
Dec 23, 2023Biased datasets are ubiquitous and present a challenge for machine learning. For a number of categories on a dataset that are equally important but some are sparse and others are common, the learning algorithms will favor the ones with more presence. The problem of biased datasets is especially sensitive when dealing with minority people groups. How can we, from biased data, generate algorithms that treat every person equally? This work explores one way to mitigate bias using a debiasing variational autoencoder with experiments on facial expression recognition.
Forecast Ergodicity: Prediction Modeling Using Algorithmic Information Theory
Apr 21, 2023



The capabilities of machine intelligence are bounded by the potential of data from the past to forecast the future. Deep learning tools are used to find structures in the available data to make predictions about the future. Such structures have to be present in the available data in the first place and they have to be applicable in the future. Forecast ergodicity is a measure of the ability to forecast future events from data in the past. We model this bound by the algorithmic complexity of the available data.
Cascade Watchdog: A Multi-tiered Adversarial Guard for Outlier Detection
Aug 20, 2021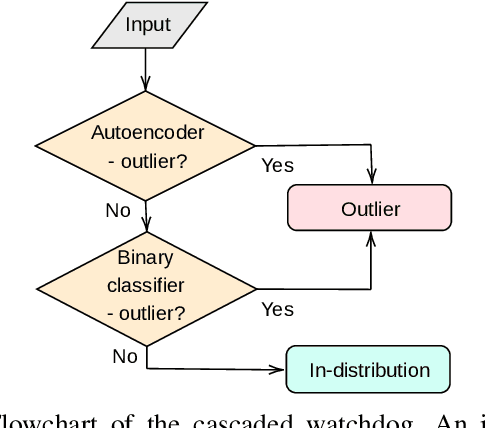
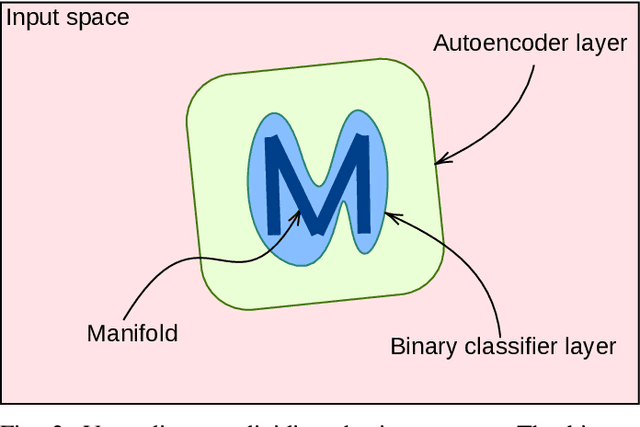

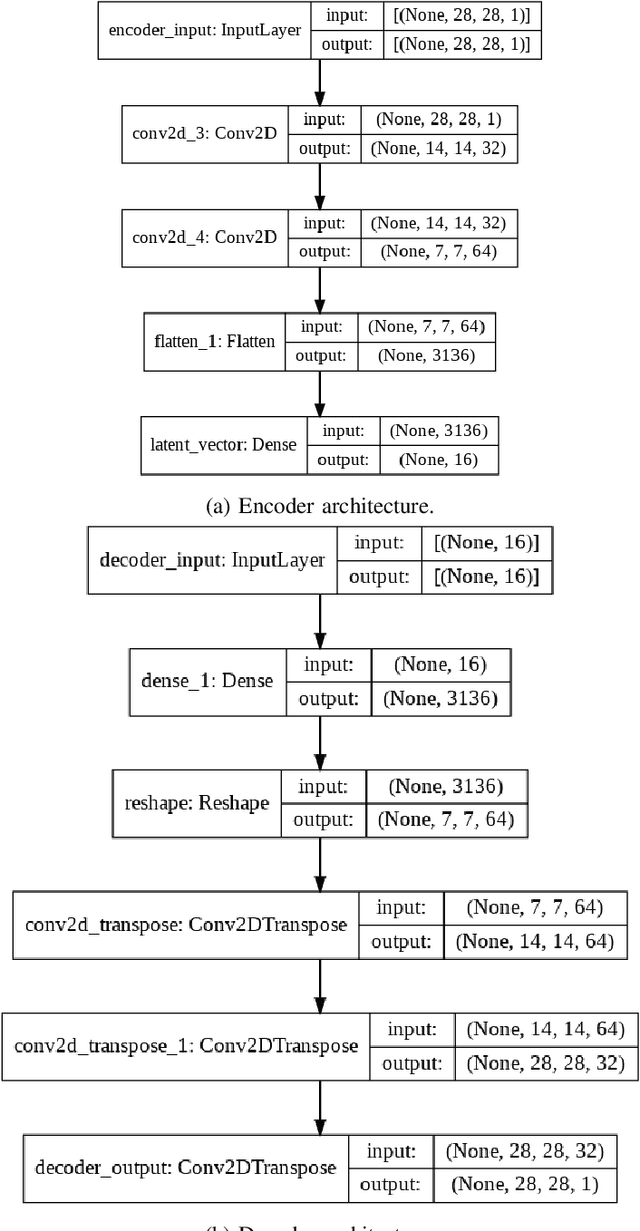
The identification of out-of-distribution content is critical to the successful implementation of neural networks. Watchdog techniques have been developed to support the detection of these inputs, but the performance can be limited by the amount of available data. Generative adversarial networks have displayed numerous capabilities, including the ability to generate facsimiles with excellent accuracy. This paper presents and empirically evaluates a multi-tiered watchdog, which is developed using GAN generated data, for improved out-of-distribution detection. The cascade watchdog uses adversarial training to increase the amount of available data similar to the out-of-distribution elements that are more difficult to detect. Then, a specialized second guard is added in sequential order. The results show a solid and significant improvement on the detection of the most challenging out-of-distribution inputs while preserving an extremely low false positive rate.