 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing the Stability of LLM-based Speech Generation Systems through Self-Supervised Representations
Feb 05, 2024


Large Language Models (LLMs) are one of the most promising technologies for the next era of speech generation systems, due to their scalability and in-context learning capabilities. Nevertheless, they suffer from multiple stability issues at inference time, such as hallucinations, content skipping or speech repetitions. In this work, we introduce a new self-supervised Voice Conversion (VC) architecture which can be used to learn to encode transitory features, such as content, separately from stationary ones, such as speaker ID or recording conditions, creating speaker-disentangled representations. Using speaker-disentangled codes to train LLMs for text-to-speech (TTS) allows the LLM to generate the content and the style of the speech only from the text, similarly to humans, while the speaker identity is provided by the decoder of the VC model. Results show that LLMs trained over speaker-disentangled self-supervised representations provide an improvement of 4.7pp in speaker similarity over SOTA entangled representations, and a word error rate (WER) 5.4pp lower. Furthermore, they achieve higher naturalness than human recordings of the LibriTTS test-other dataset. Finally, we show that using explicit reference embedding negatively impacts intelligibility (stability), with WER increasing by 14pp compared to the model that only uses text to infer the style.
AE-Flow: AutoEncoder Normalizing Flow
Dec 27, 2023Recently normalizing flows have been gaining traction in text-to-speech (TTS) and voice conversion (VC) due to their state-of-the-art (SOTA) performance. Normalizing flows are unsupervised generative models. In this paper, we introduce supervision to the training process of normalizing flows, without the need for parallel data. We call this training paradigm AutoEncoder Normalizing Flow (AE-Flow). It adds a reconstruction loss forcing the model to use information from the conditioning to reconstruct an audio sample. Our goal is to understand the impact of each component and find the right combination of the negative log-likelihood (NLL) and the reconstruction loss in training normalizing flows with coupling blocks. For that reason we will compare flow-based mapping model trained with: (i) NLL loss, (ii) NLL and reconstruction losses, as well as (iii) reconstruction loss only. Additionally, we compare our model with SOTA VC baseline. The models are evaluated in terms of naturalness, speaker similarity, intelligibility in many-to-many and many-to-any VC settings. The results show that the proposed training paradigm systematically improves speaker similarity and naturalness when compared to regular training methods of normalizing flows. Furthermore, we show that our method improves speaker similarity and intelligibility over the state-of-the-art.
Text-free non-parallel many-to-many voice conversion using normalising flows
Mar 15, 2022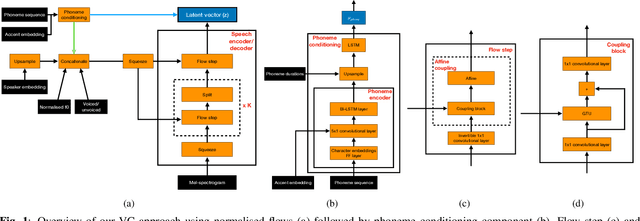
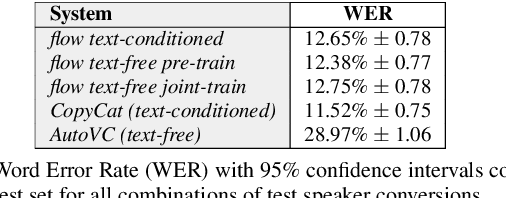
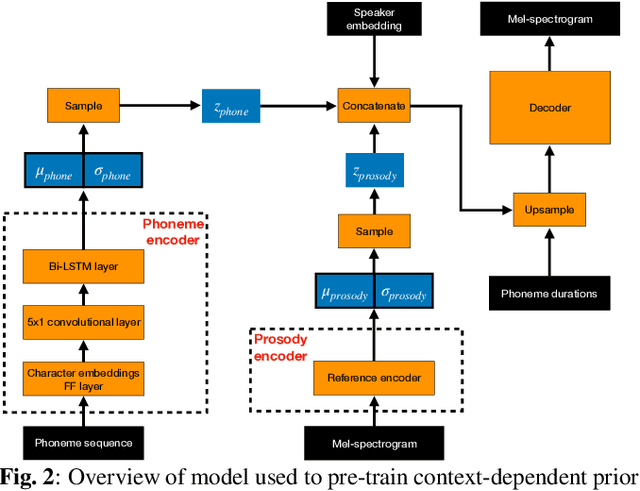
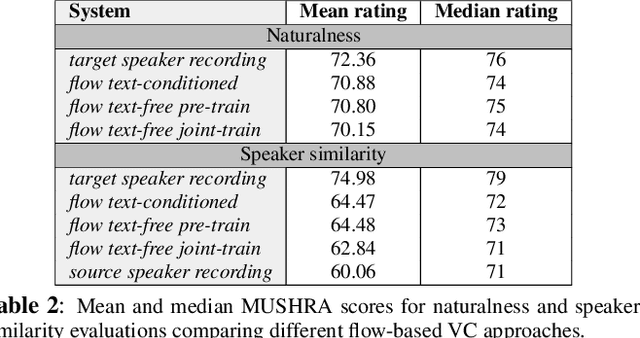
Non-parallel voice conversion (VC) is typically achieved using lossy representations of the source speech. However, ensuring only speaker identity information is dropped whilst all other information from the source speech is retained is a large challenge. This is particularly challenging in the scenario where at inference-time we have no knowledge of the text being read, i.e., text-free VC. To mitigate this, we investigate information-preserving VC approaches. Normalising flows have gained attention for text-to-speech synthesis, however have been under-explored for VC. Flows utilize invertible functions to learn the likelihood of the data, thus provide a lossless encoding of speech. We investigate normalising flows for VC in both text-conditioned and text-free scenarios. Furthermore, for text-free VC we compare pre-trained and jointly-learnt priors. Flow-based VC evaluations show no degradation between text-free and text-conditioned VC, resulting in improvements over the state-of-the-art. Also, joint-training of the prior is found to negatively impact text-free VC quality.
Machine Learning for Generalizable Prediction of Flood Susceptibility
Oct 15, 2019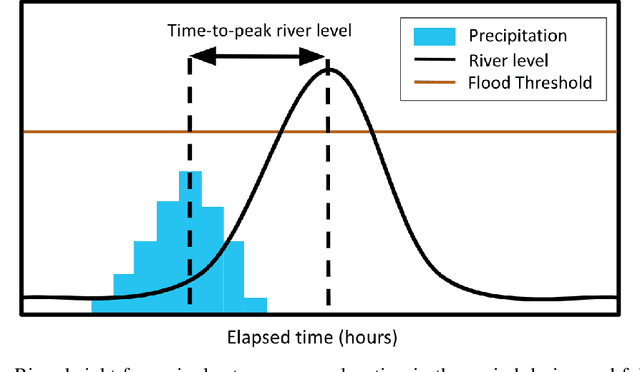

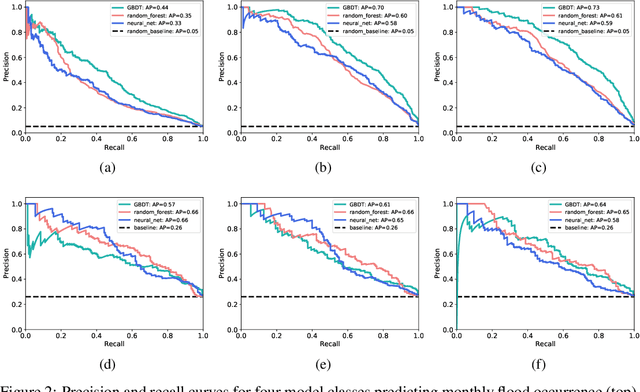
Flooding is a destructive and dangerous hazard and climate change appears to be increasing the frequency of catastrophic flooding events around the world. Physics-based flood models are costly to calibrate and are rarely generalizable across different river basins, as model outputs are sensitive to site-specific parameters and human-regulated infrastructure. In contrast, statistical models implicitly account for such factors through the data on which they are trained. Such models trained primarily from remotely-sensed Earth observation data could reduce the need for extensive in-situ measurements. In this work, we develop generalizable, multi-basin models of river flooding susceptibility using geographically-distributed data from the USGS stream gauge network. Machine learning models are trained in a supervised framework to predict two measures of flood susceptibility from a mix of river basin attributes, impervious surface cover information derived from satellite imagery, and historical records of rainfall and stream height. We report prediction performance of multiple models using precision-recall curves, and compare with performance of naive baselines. This work on multi-basin flood prediction represents a step in the direction of making flood prediction accessible to all at-risk communities.