 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecoupled Actor-Critic
Paper and Code
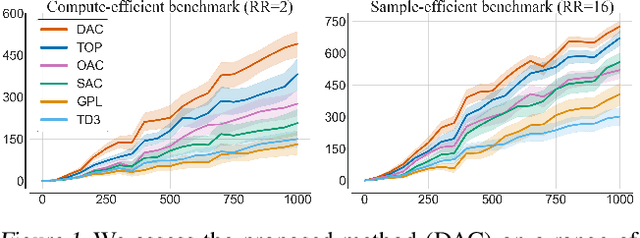
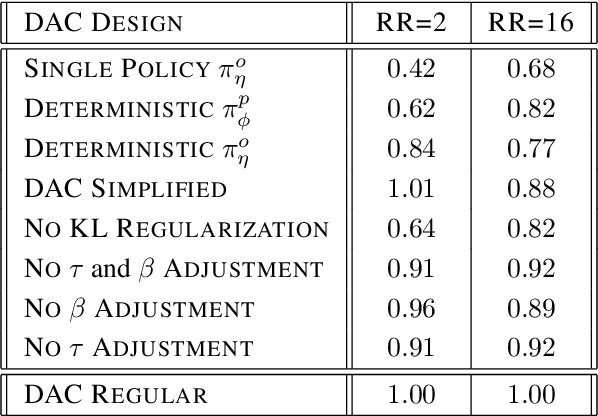
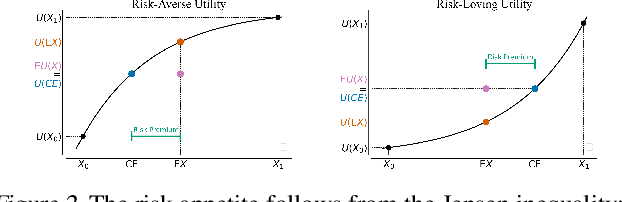
Actor-Critic methods are in a stalemate of two seemingly irreconcilable problems. Firstly, critic proneness towards overestimation requires sampling temporal-difference targets from a conservative policy optimized using lower-bound Q-values. Secondly, well-known results show that policies that are optimistic in the face of uncertainty yield lower regret levels. To remedy this dichotomy, we propose Decoupled Actor-Critic (DAC). DAC is an off-policy algorithm that learns two distinct actors by gradient backpropagation: a conservative actor used for temporal-difference learning and an optimistic actor used for exploration. We test DAC on DeepMind Control tasks in low and high replay ratio regimes and ablate multiple design choices. Despite minimal computational overhead, DAC achieves state-of-the-art performance and sample efficiency on locomotion tasks.