 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNARAIM: Native Aspect Ratio Autoregressive Image Models
Oct 13, 2024
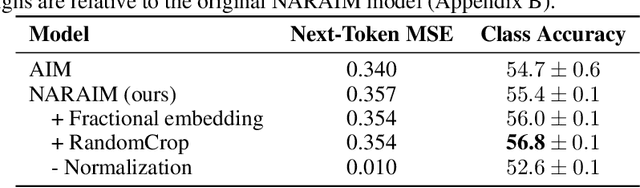
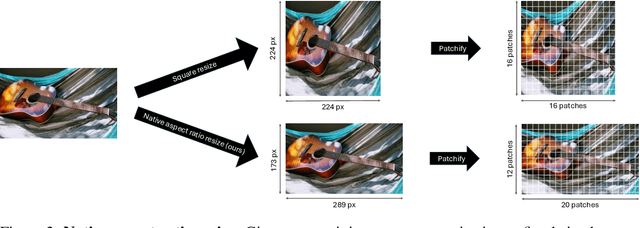
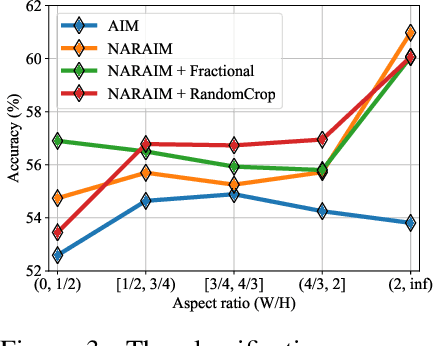
While vision transformers are able to solve a wide variety of computer vision tasks, no pre-training method has yet demonstrated the same scaling laws as observed in language models. Autoregressive models show promising results, but are commonly trained on images that are cropped or transformed into square images, which distorts or destroys information present in the input. To overcome this limitation, we propose NARAIM, a vision model pre-trained with an autoregressive objective that uses images in their native aspect ratio. By maintaining the native aspect ratio, we preserve the original spatial context, thereby enhancing the model's ability to interpret visual information. In our experiments, we show that maintaining the aspect ratio improves performance on a downstream classification task.
DuoDiff: Accelerating Diffusion Models with a Dual-Backbone Approach
Oct 12, 2024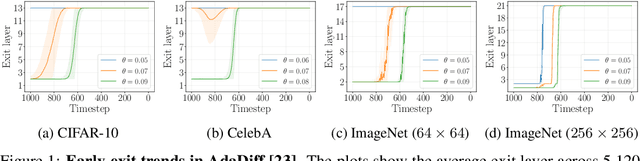
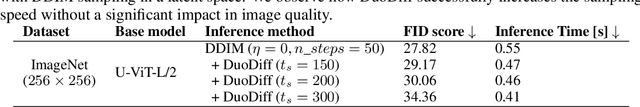
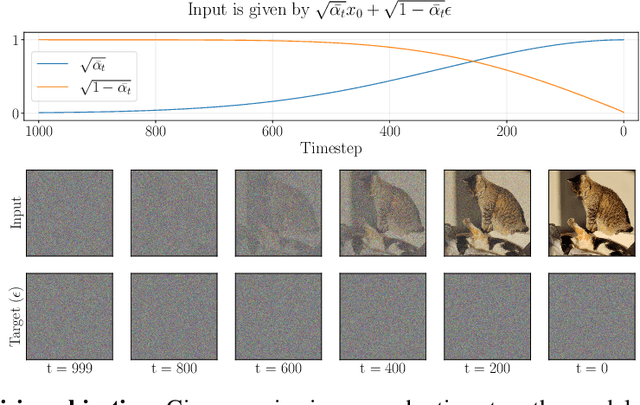
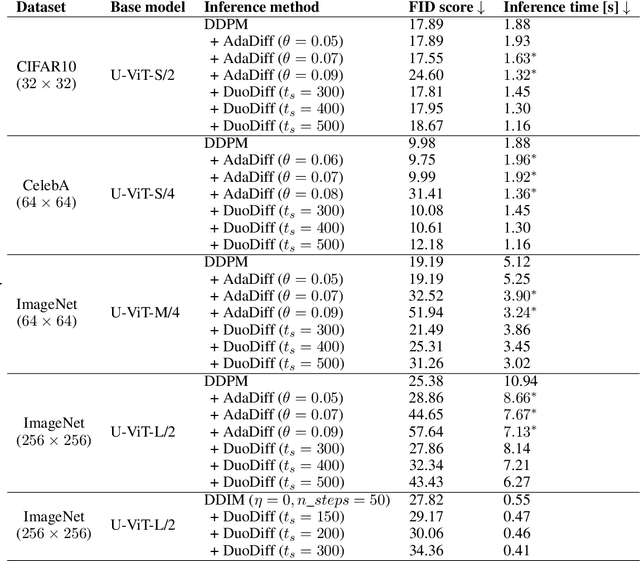
Diffusion models have achieved unprecedented performance in image generation, yet they suffer from slow inference due to their iterative sampling process. To address this, early-exiting has recently been proposed, where the depth of the denoising network is made adaptive based on the (estimated) difficulty of each sampling step. Here, we discover an interesting "phase transition" in the sampling process of current adaptive diffusion models: the denoising network consistently exits early during the initial sampling steps, until it suddenly switches to utilizing the full network. Based on this, we propose accelerating generation by employing a shallower denoising network in the initial sampling steps and a deeper network in the later steps. We demonstrate empirically that our dual-backbone approach, DuoDiff, outperforms existing early-exit diffusion methods in both inference speed and generation quality. Importantly, DuoDiff is easy to implement and complementary to existing approaches for accelerating diffusion.