 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRetrieval-guided Cross-view Image Synthesis
Paper and Code
Nov 29, 2024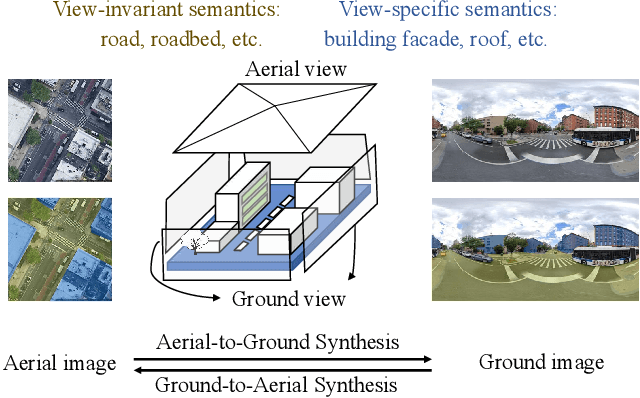


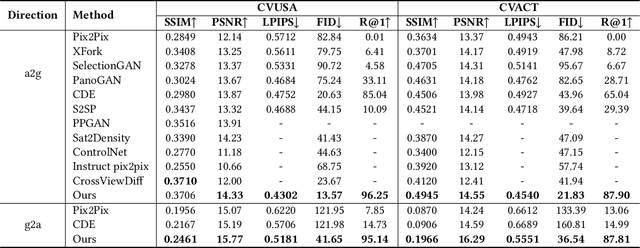
Cross-view image synthesis involves generating new images of a scene from different viewpoints or perspectives, given one input image from other viewpoints. Despite recent advancements, there are several limitations in existing methods: 1) reliance on additional data such as semantic segmentation maps or preprocessing modules to bridge the domain gap; 2) insufficient focus on view-specific semantics, leading to compromised image quality and realism; and 3) a lack of diverse datasets representing complex urban environments. To tackle these challenges, we propose: 1) a novel retrieval-guided framework that employs a retrieval network as an embedder to address the domain gap; 2) an innovative generator that enhances semantic consistency and diversity specific to the target view to improve image quality and realism; and 3) a new dataset, VIGOR-GEN, providing diverse cross-view image pairs in urban settings to enrich dataset diversity. Extensive experiments on well-known CVUSA, CVACT, and new VIGOR-GEN datasets demonstrate that our method generates images of superior realism, significantly outperforming current leading approaches, particularly in SSIM and FID evaluations.