 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-view Geo-localization with Evolving Transformer
Jul 05, 2021
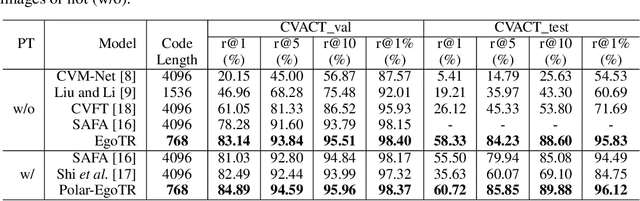
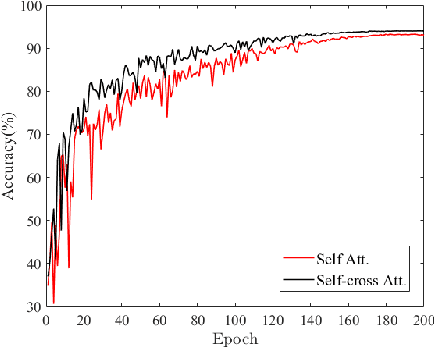
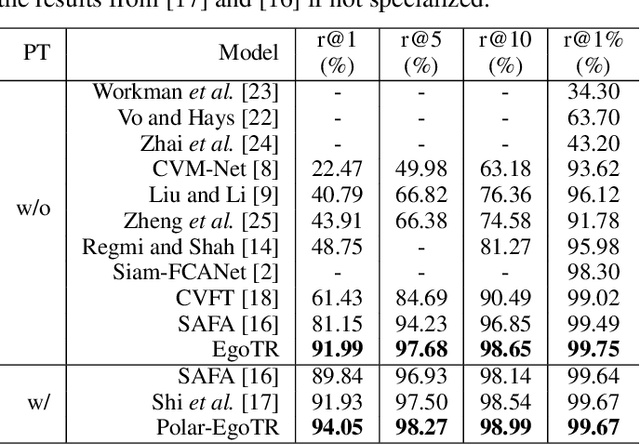
In this work, we address the problem of cross-view geo-localization, which estimates the geospatial location of a street view image by matching it with a database of geo-tagged aerial images. The cross-view matching task is extremely challenging due to drastic appearance and geometry differences across views. Unlike existing methods that predominantly fall back on CNN, here we devise a novel evolving geo-localization Transformer (EgoTR) that utilizes the properties of self-attention in Transformer to model global dependencies, thus significantly decreasing visual ambiguities in cross-view geo-localization. We also exploit the positional encoding of Transformer to help the EgoTR understand and correspond geometric configurations between ground and aerial images. Compared to state-of-the-art methods that impose strong assumption on geometry knowledge, the EgoTR flexibly learns the positional embeddings through the training objective and hence becomes more practical in many real-world scenarios. Although Transformer is well suited to our task, its vanilla self-attention mechanism independently interacts within image patches in each layer, which overlooks correlations between layers. Instead, this paper propose a simple yet effective self-cross attention mechanism to improve the quality of learned representations. The self-cross attention models global dependencies between adjacent layers, which relates between image patches while modeling how features evolve in the previous layer. As a result, the proposed self-cross attention leads to more stable training, improves the generalization ability and encourages representations to keep evolving as the network goes deeper. Extensive experiments demonstrate that our EgoTR performs favorably against state-of-the-art methods on standard, fine-grained and cross-dataset cross-view geo-localization tasks.