 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVector Space Morphology with Linear Discriminative Learning
Paper and Code

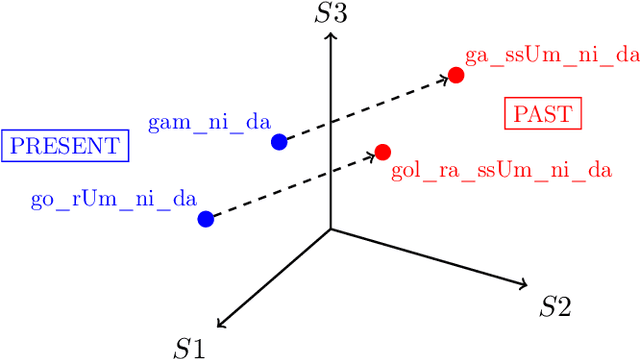

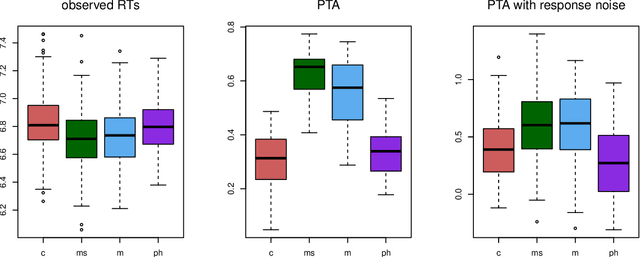
This paper presents three case studies of modeling aspects of lexical processing with Linear Discriminative Learning (LDL), the computational engine of the Discriminative Lexicon model (Baayen et al., 2019). With numeric representations of word forms and meanings, LDL learns to map one vector space onto the other, without being informed about any morphological structure or inflectional classes. The modeling results demonstrated that LDL not only performs well for understanding and producing morphologically complex words, but also generates quantitative measures that are predictive for human behavioral data. LDL models are straightforward to implement with the JudiLing package (Luo et al., 2021). Worked examples are provided for three modeling challenges: producing and understanding Korean verb inflection, predicting primed Dutch lexical decision latencies, and predicting the acoustic duration of Mandarin words.