 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbing Internal Representations of Multi-Word Verbs in Large Language Models
Feb 07, 2025This study investigates the internal representations of verb-particle combinations, called multi-word verbs, within transformer-based large language models (LLMs), specifically examining how these models capture lexical and syntactic properties at different neural network layers. Using the BERT architecture, we analyze the representations of its layers for two different verb-particle constructions: phrasal verbs like 'give up' and prepositional verbs like 'look at'. Our methodology includes training probing classifiers on the internal representations to classify these categories at both word and sentence levels. The results indicate that the model's middle layers achieve the highest classification accuracies. To further analyze the nature of these distinctions, we conduct a data separability test using the Generalized Discrimination Value (GDV). While GDV results show weak linear separability between the two verb types, probing classifiers still achieve high accuracy, suggesting that representations of these linguistic categories may be non-linearly separable. This aligns with previous research indicating that linguistic distinctions in neural networks are not always encoded in a linearly separable manner. These findings computationally support usage-based claims on the representation of verb-particle constructions and highlight the complex interaction between neural network architectures and linguistic structures.
Analysis and Visualization of Linguistic Structures in Large Language Models: Neural Representations of Verb-Particle Constructions in BERT
Dec 19, 2024
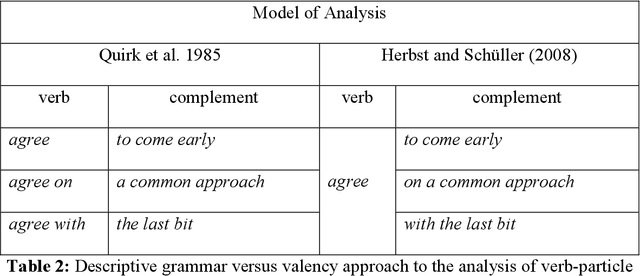

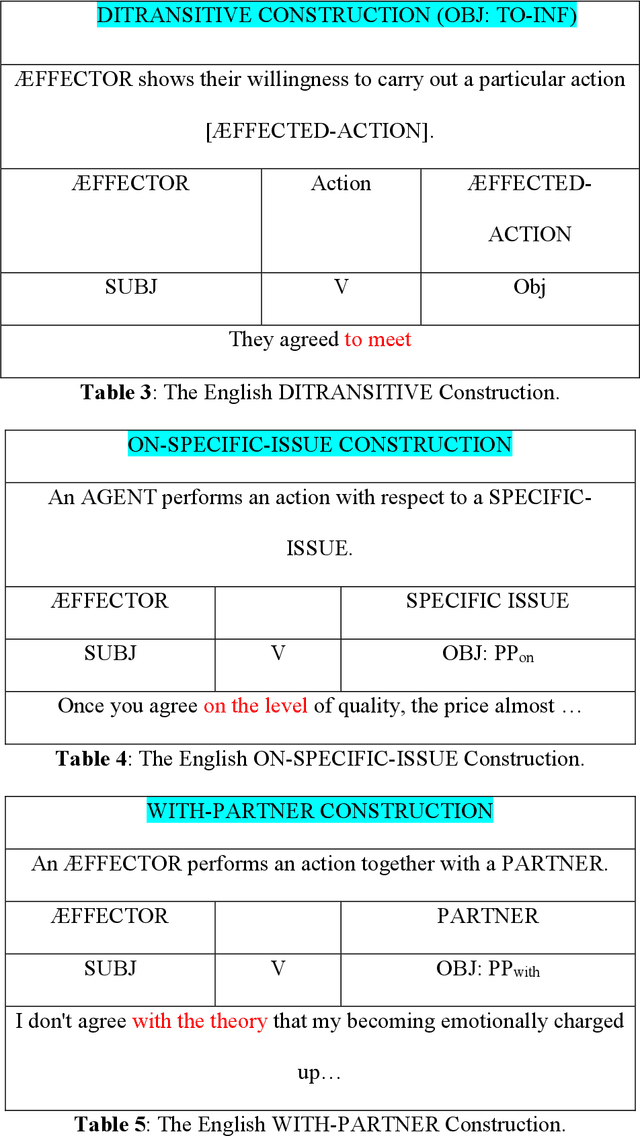
This study investigates the internal representations of verb-particle combinations within transformer-based large language models (LLMs), specifically examining how these models capture lexical and syntactic nuances at different neural network layers. Employing the BERT architecture, we analyse the representational efficacy of its layers for various verb-particle constructions such as 'agree on', 'come back', and 'give up'. Our methodology includes a detailed dataset preparation from the British National Corpus, followed by extensive model training and output analysis through techniques like multi-dimensional scaling (MDS) and generalized discrimination value (GDV) calculations. Results show that BERT's middle layers most effectively capture syntactic structures, with significant variability in representational accuracy across different verb categories. These findings challenge the conventional uniformity assumed in neural network processing of linguistic elements and suggest a complex interplay between network architecture and linguistic representation. Our research contributes to a better understanding of how deep learning models comprehend and process language, offering insights into the potential and limitations of current neural approaches to linguistic analysis. This study not only advances our knowledge in computational linguistics but also prompts further research into optimizing neural architectures for enhanced linguistic precision.