 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClassification at the Accuracy Limit -- Facing the Problem of Data Ambiguity
Jun 04, 2022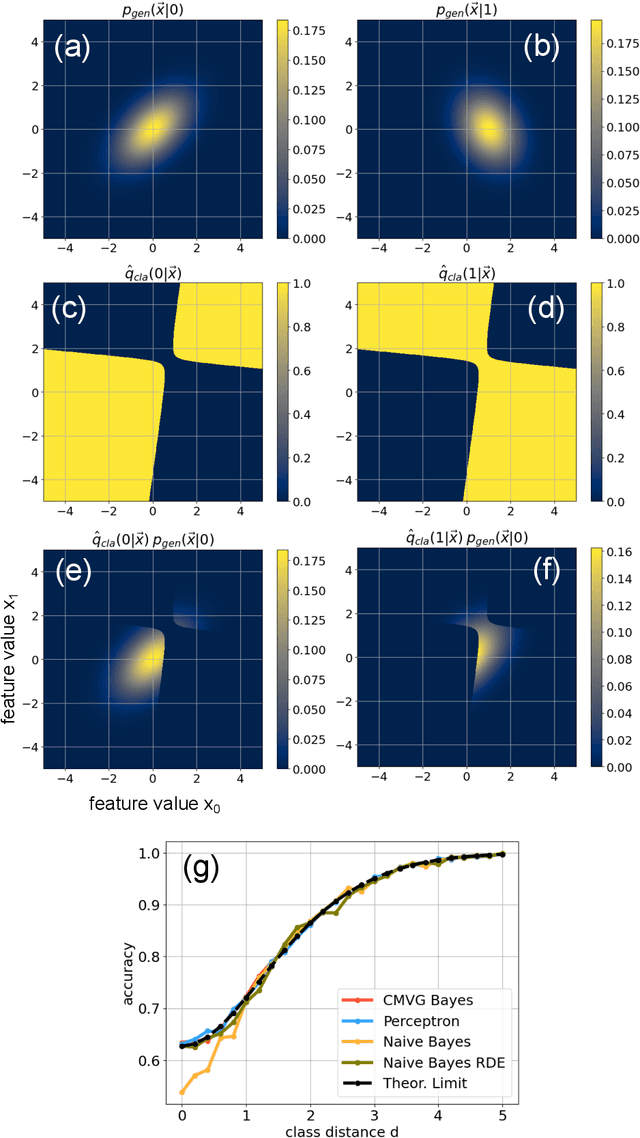
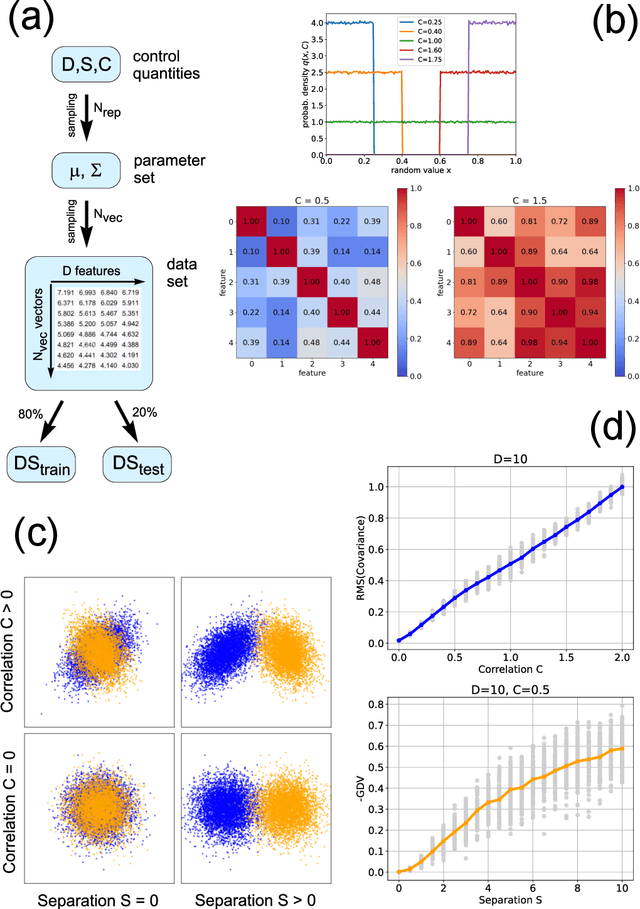
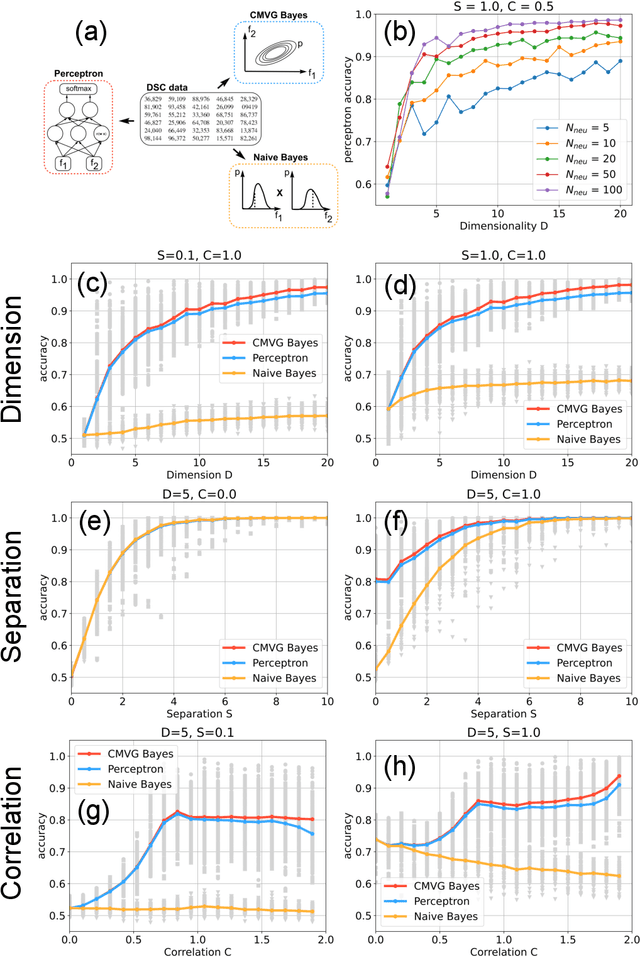
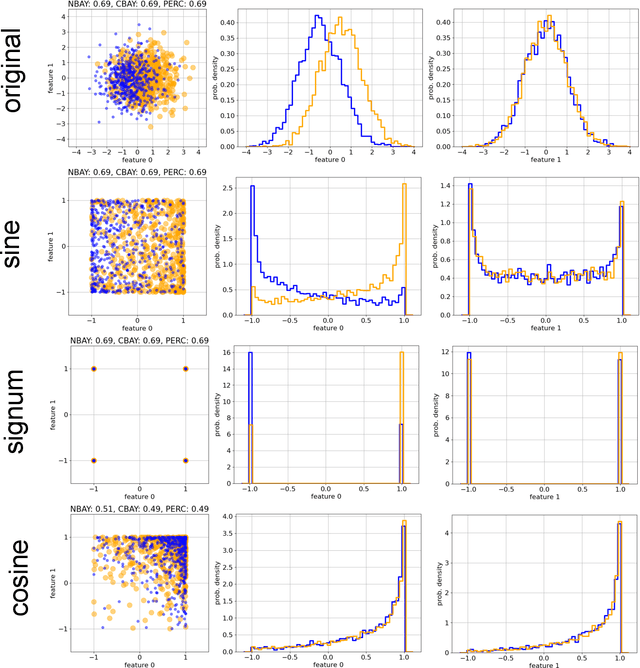
Data classification, the process of analyzing data and organizing it into categories, is a fundamental computing problem of natural and artificial information processing systems. Ideally, the performance of classifier models would be evaluated using unambiguous data sets, where the 'correct' assignment of category labels to the input data vectors is unequivocal. In real-world problems, however, a significant fraction of actually occurring data vectors will be located in a boundary zone between or outside of all categories, so that perfect classification cannot even in principle be achieved. We derive the theoretical limit for classification accuracy that arises from the overlap of data categories. By using a surrogate data generation model with adjustable statistical properties, we show that sufficiently powerful classifiers based on completely different principles, such as perceptrons and Bayesian models, all perform at this universal accuracy limit. Remarkably, the accuracy limit is not affected by applying non-linear transformations to the data, even if these transformations are non-reversible and drastically reduce the information content of the input data. We compare emerging data embeddings produced by supervised and unsupervised training, using MNIST and human EEG recordings during sleep. We find that categories are not only well separated in the final layers of classifiers trained with back-propagation, but to a smaller degree also after unsupervised dimensionality reduction. This suggests that human-defined categories, such as hand-written digits or sleep stages, can indeed be considered as 'natural kinds'.
Predictive Coding and Stochastic Resonance: Towards a Unified Theory of Auditory (Phantom) Perception
Apr 07, 2022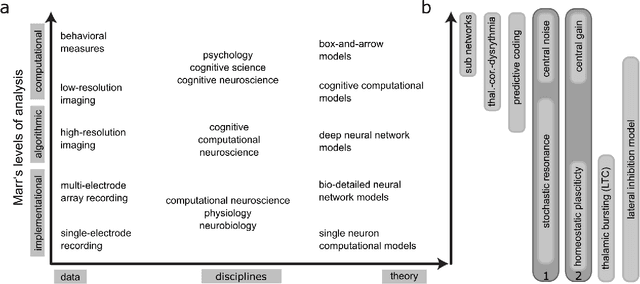
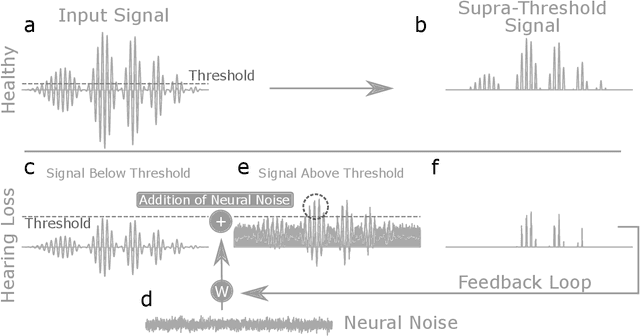
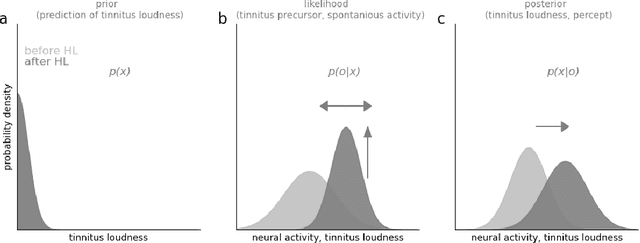

Cognitive computational neuroscience (CCN) suggests that to gain a mechanistic understanding of brain function, hypothesis driven experiments should be accompanied by biologically plausible computational models. This novel research paradigm offers a way from alchemy to chemistry, in auditory neuroscience. With a special focus on tinnitus - as the prime example of auditory phantom perception - we review recent work at the intersection of artificial intelligence, psychology, and neuroscience, foregrounding the idea that experiments will yield mechanistic insight only when employed to test formal or computational models. This view challenges the popular notion that tinnitus research is primarily data limited, and that producing large, multi-modal, and complex data-sets, analyzed with advanced data analysis algorithms, will lead to fundamental insights into how tinnitus emerges. We conclude that two fundamental processing principles - being ubiquitous in the brain - best fit to a vast number of experimental results and therefore provide the most explanatory power: predictive coding as a top-down, and stochastic resonance as a complementary bottom-up mechanism. Furthermore, we argue that even though contemporary artificial intelligence and machine learning approaches largely lack biological plausibility, the models to be constructed will have to draw on concepts from these fields; since they provide a formal account of the requisite computations that underlie brain function. Nevertheless, biological fidelity will have to be addressed, allowing for testing possible treatment strategies in silico, before application in animal or patient studies. This iteration of computational and empirical studies may help to open the "black boxes" of both machine learning and the human brain.