 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClassification at the Accuracy Limit -- Facing the Problem of Data Ambiguity
Paper and Code
Jun 04, 2022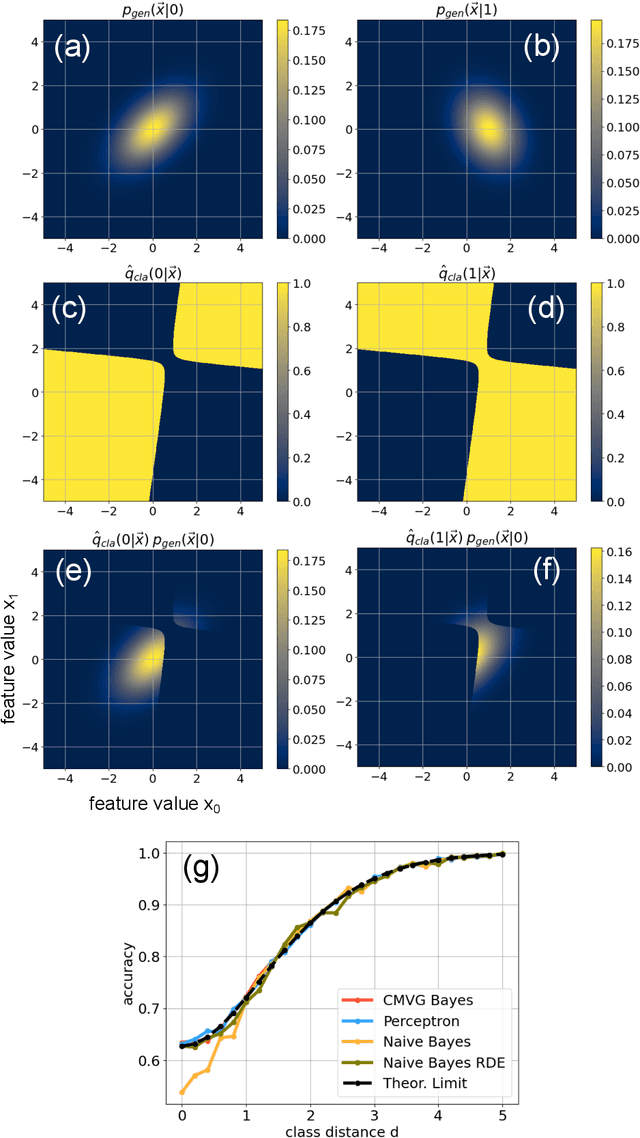
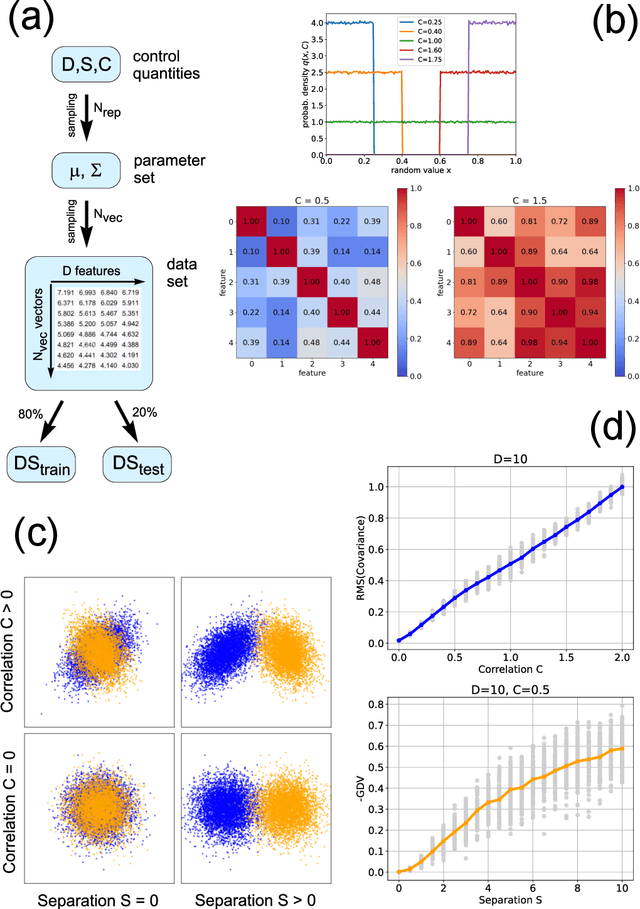
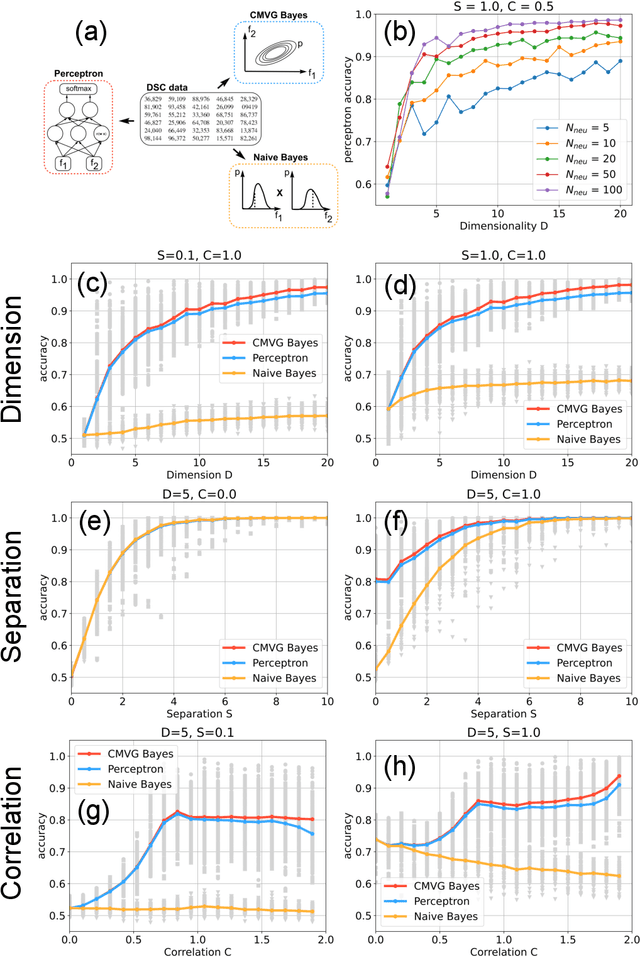
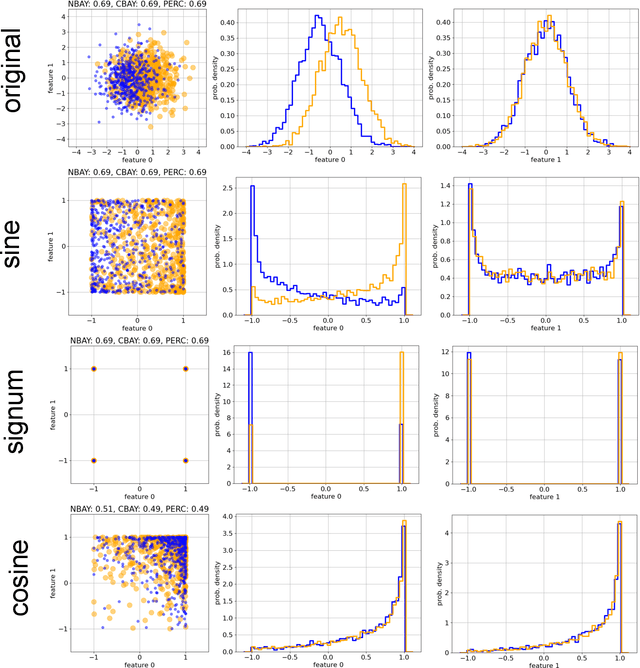
Data classification, the process of analyzing data and organizing it into categories, is a fundamental computing problem of natural and artificial information processing systems. Ideally, the performance of classifier models would be evaluated using unambiguous data sets, where the 'correct' assignment of category labels to the input data vectors is unequivocal. In real-world problems, however, a significant fraction of actually occurring data vectors will be located in a boundary zone between or outside of all categories, so that perfect classification cannot even in principle be achieved. We derive the theoretical limit for classification accuracy that arises from the overlap of data categories. By using a surrogate data generation model with adjustable statistical properties, we show that sufficiently powerful classifiers based on completely different principles, such as perceptrons and Bayesian models, all perform at this universal accuracy limit. Remarkably, the accuracy limit is not affected by applying non-linear transformations to the data, even if these transformations are non-reversible and drastically reduce the information content of the input data. We compare emerging data embeddings produced by supervised and unsupervised training, using MNIST and human EEG recordings during sleep. We find that categories are not only well separated in the final layers of classifiers trained with back-propagation, but to a smaller degree also after unsupervised dimensionality reduction. This suggests that human-defined categories, such as hand-written digits or sleep stages, can indeed be considered as 'natural kinds'.