 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMobile Application Threats and Security
Feb 08, 2025The movement to mobile computing solutions provides flexibility to different users whether it is a business user, a student, or even providing entertainment to children and adults of all ages. Due to these emerging technologies mobile users are unable to safeguard private information in a very effective way and cybercrimes are increasing day by day. This manuscript will focus on security vulnerabilities in the mobile computing industry, especially focusing on tablets and smart phones. This study will dive into current security threats for the Android & Apple iOS market, exposing security risks and threats that the novice or average user may not be aware of. The purpose of this study is to analyze current security risks and threats, and provide solutions that may be deployed to protect against such threats.
Trust as Extended Control: Active Inference and User Feedback During Human-Robot Collaboration
Apr 22, 2021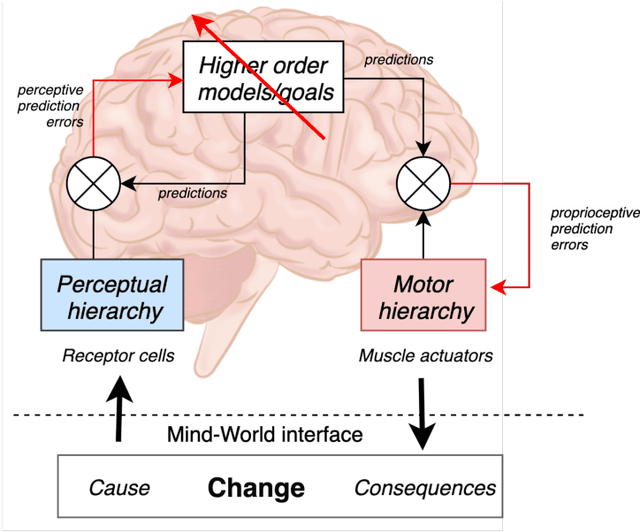

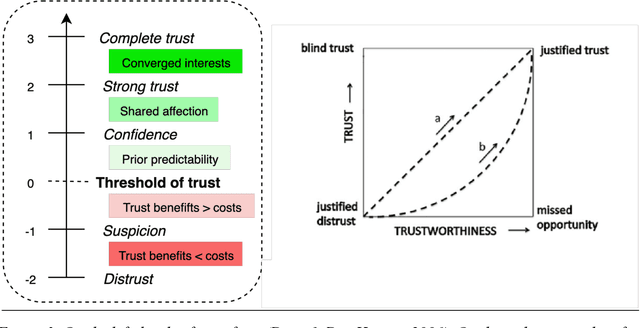

To interact seamlessly with robots, users must infer the causes of a robot's behavior and be confident about that inference. Hence, trust is a necessary condition for human-robot collaboration (HRC). Despite its crucial role, it is largely unknown how trust emerges, develops, and supports human interactions with nonhuman artefacts. Here, we review the literature on trust, human-robot interaction, human-robot collaboration, and human interaction at large. Early models of trust suggest that trust entails a trade-off between benevolence and competence, while studies of human-to-human interaction emphasize the role of shared behavior and mutual knowledge in the gradual building of trust. We then introduce a model of trust as an agent's best explanation for reliable sensory exchange with an extended motor plant or partner. This model is based on the cognitive neuroscience of active inference and suggests that, in the context of HRC, trust can be cast in terms of virtual control over an artificial agent. In this setting, interactive feedback becomes a necessary component of the trustor's perception-action cycle. The resulting model has important implications for understanding human-robot interaction and collaboration, as it allows the traditional determinants of human trust to be defined in terms of active inference, information exchange and empowerment. Furthermore, this model suggests that boredom and surprise may be used as markers for under and over-reliance on the system. Finally, we examine the role of shared behavior in the genesis of trust, especially in the context of dyadic collaboration, suggesting important consequences for the acceptability and design of human-robot collaborative systems.
Medical code prediction with multi-view convolution and description-regularized label-dependent attention
Nov 05, 2018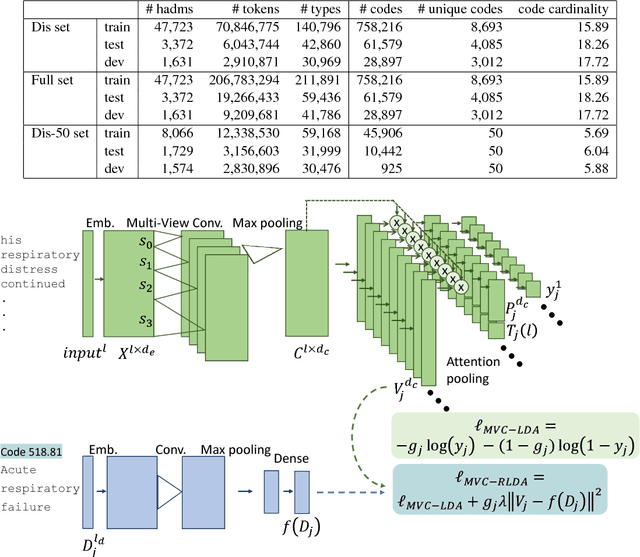

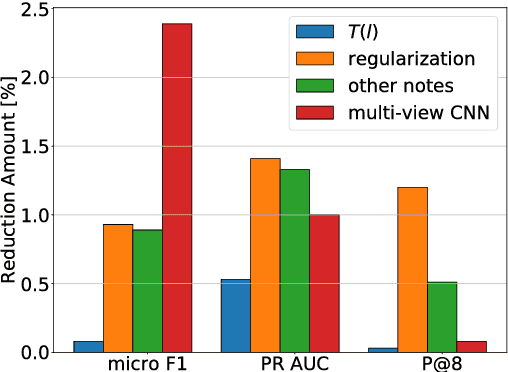
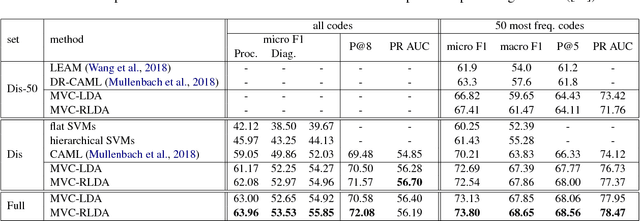
A ubiquitous task in processing electronic medical data is the assignment of standardized codes representing diagnoses and/or procedures to free-text documents such as medical reports. This is a difficult natural language processing task that requires parsing long, heterogeneous documents and selecting a set of appropriate codes from tens of thousands of possibilities---many of which have very few positive training samples. We present a deep learning system that advances the state of the art for the MIMIC-III dataset, achieving a new best micro F1-measure of 55.85\%, significantly outperforming the previous best result (Mullenbach et al. 2018). We achieve this through a number of enhancements, including two major novel contributions: multi-view convolutional channels, which effectively learn to adjust kernel sizes throughout the input; and attention regularization, mediated by natural-language code descriptions, which helps overcome sparsity for thousands of uncommon codes. These and other modifications are selected to address difficulties inherent to both automated coding specifically and deep learning generally. Finally, we investigate our accuracy results in detail to individually measure the impact of these contributions and point the way towards future algorithmic improvements.