 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReframing the Expected Free Energy: Four Formulations and a Unification
Feb 22, 2024Active inference is a leading theory of perception, learning and decision making, which can be applied to neuroscience, robotics, psychology, and machine learning. Active inference is based on the expected free energy, which is mostly justified by the intuitive plausibility of its formulations, e.g., the risk plus ambiguity and information gain / pragmatic value formulations. This paper seek to formalize the problem of deriving these formulations from a single root expected free energy definition, i.e., the unification problem. Then, we study two settings, each one having its own root expected free energy definition. In the first setting, no justification for the expected free energy has been proposed to date, but all the formulations can be recovered from it. However, in this setting, the agent cannot have arbitrary prior preferences over observations. Indeed, only a limited class of prior preferences over observations is compatible with the likelihood mapping of the generative model. In the second setting, a justification of the root expected free energy definition is known, but this setting only accounts for two formulations, i.e., the risk over states plus ambiguity and entropy plus expected energy formulations.
Bayesian sparsification for deep neural networks with Bayesian model reduction
Sep 21, 2023



Deep learning's immense capabilities are often constrained by the complexity of its models, leading to an increasing demand for effective sparsification techniques. Bayesian sparsification for deep learning emerges as a crucial approach, facilitating the design of models that are both computationally efficient and competitive in terms of performance across various deep learning applications. The state-of-the-art -- in Bayesian sparsification of deep neural networks -- combines structural shrinkage priors on model weights with an approximate inference scheme based on black-box stochastic variational inference. However, model inversion of the full generative model is exceptionally computationally demanding, especially when compared to standard deep learning of point estimates. In this context, we advocate for the use of Bayesian model reduction (BMR) as a more efficient alternative for pruning of model weights. As a generalization of the Savage-Dickey ratio, BMR allows a post-hoc elimination of redundant model weights based on the posterior estimates under a straightforward (non-hierarchical) generative model. Our comparative study highlights the computational efficiency and the pruning rate of the BMR method relative to the established stochastic variational inference (SVI) scheme, when applied to the full hierarchical generative model. We illustrate the potential of BMR to prune model parameters across various deep learning architectures, from classical networks like LeNet to modern frameworks such as Vision Transformers and MLP-Mixers.
Neuronal Sequence Models for Bayesian Online Inference
Apr 02, 2020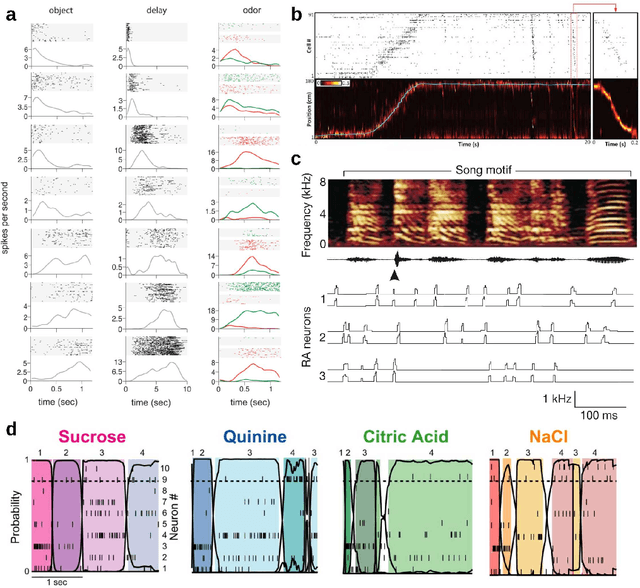
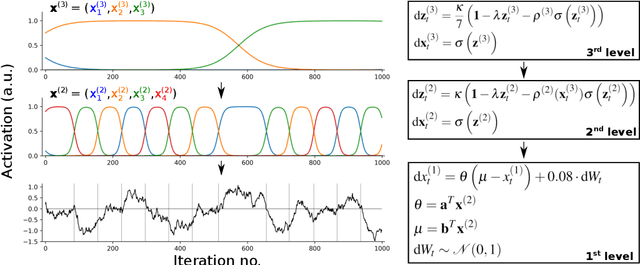
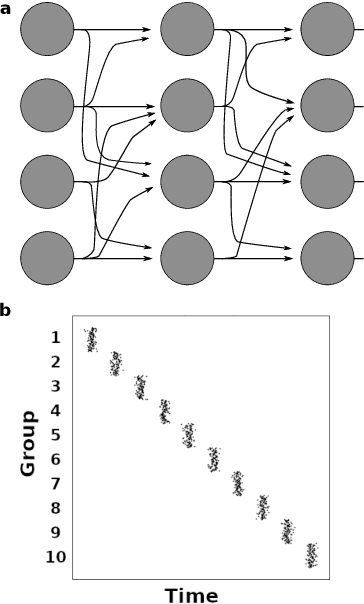
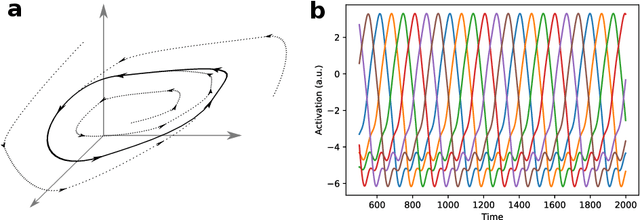
Sequential neuronal activity underlies a wide range of processes in the brain. Neuroscientific evidence for neuronal sequences has been reported in domains as diverse as perception, motor control, speech, spatial navigation and memory. Consequently, different dynamical principles have been proposed as possible sequence-generating mechanisms. Combining experimental findings with computational concepts like the Bayesian brain hypothesis and predictive coding leads to the interesting possibility that predictive and inferential processes in the brain are grounded on generative processes which maintain a sequential structure. While probabilistic inference about ongoing sequences is a useful computational model for both the analysis of neuroscientific data and a wide range of problems in artificial recognition and motor control, research on the subject is relatively scarce and distributed over different fields in the neurosciences. Here we review key findings about neuronal sequences and relate these to the concept of online inference on sequences as a model of sensory-motor processing and recognition. We propose that describing sequential neuronal activity as an expression of probabilistic inference over sequences may lead to novel perspectives on brain function. Importantly, it is promising to translate the key idea of probabilistic inference on sequences to machine learning, in order to address challenges in the real-time recognition of speech and human motion.
Body movement to sound interface with vector autoregressive hierarchical hidden Markov models
Oct 26, 2016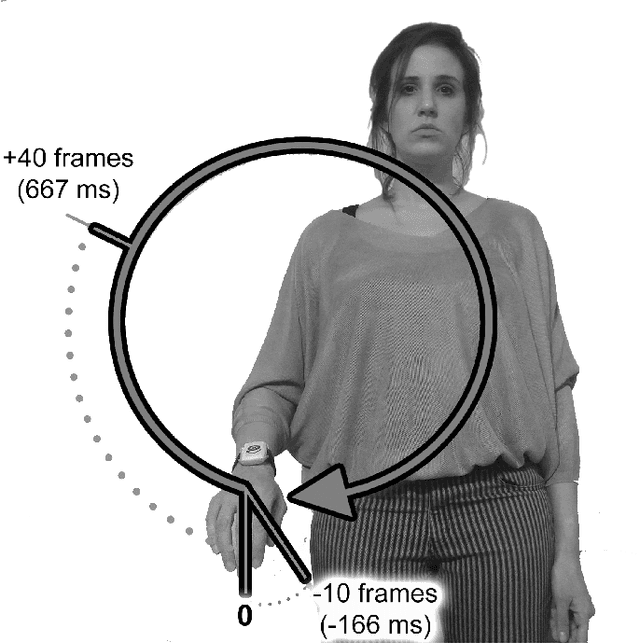
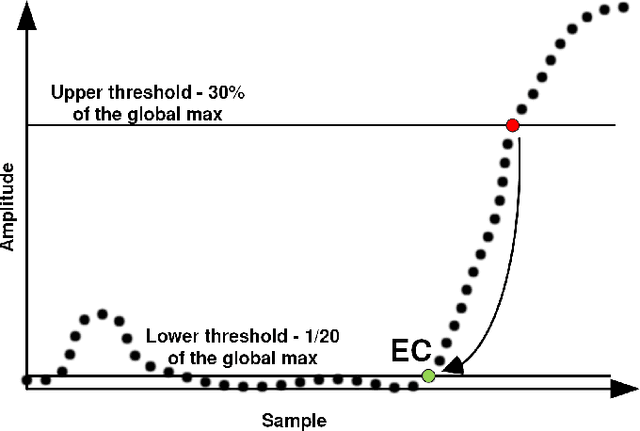
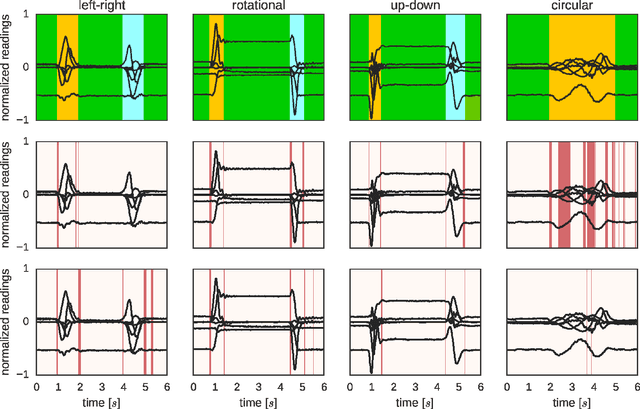
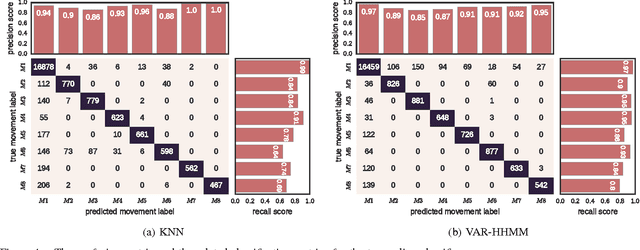
Interfacing a kinetic action of a person to an action of a machine system is an important research topic in many application areas. One of the key factors for intimate human-machine interaction is the ability of the control algorithm to detect and classify different user commands with shortest possible latency, thus making a highly correlated link between cause and effect. In our research, we focused on the task of mapping user kinematic actions into sound samples. The presented methodology relies on the wireless sensor nodes equipped with inertial measurement units and the real-time algorithm dedicated for early detection and classification of a variety of movements/gestures performed by a user. The core algorithm is based on the approximate Bayesian inference of Vector Autoregressive Hierarchical Hidden Markov Models (VAR-HHMM), where models database is derived from the set of motion gestures. The performance of the algorithm was compared with an online version of the K-nearest neighbours (KNN) algorithm, where we used offline expert based classification as the benchmark. In almost all of the evaluation metrics (e.g. confusion matrix, recall and precision scores) the VAR-HHMM algorithm outperformed KNN. Furthermore, the VAR-HHMM algorithm, in some cases, achieved faster movement onset detection compared with the offline standard. The proposed concept, although envisioned for movement-to-sound application, could be implemented in other human-machine interfaces.