 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBayesian sparsification for deep neural networks with Bayesian model reduction
Sep 21, 2023



Deep learning's immense capabilities are often constrained by the complexity of its models, leading to an increasing demand for effective sparsification techniques. Bayesian sparsification for deep learning emerges as a crucial approach, facilitating the design of models that are both computationally efficient and competitive in terms of performance across various deep learning applications. The state-of-the-art -- in Bayesian sparsification of deep neural networks -- combines structural shrinkage priors on model weights with an approximate inference scheme based on black-box stochastic variational inference. However, model inversion of the full generative model is exceptionally computationally demanding, especially when compared to standard deep learning of point estimates. In this context, we advocate for the use of Bayesian model reduction (BMR) as a more efficient alternative for pruning of model weights. As a generalization of the Savage-Dickey ratio, BMR allows a post-hoc elimination of redundant model weights based on the posterior estimates under a straightforward (non-hierarchical) generative model. Our comparative study highlights the computational efficiency and the pruning rate of the BMR method relative to the established stochastic variational inference (SVI) scheme, when applied to the full hierarchical generative model. We illustrate the potential of BMR to prune model parameters across various deep learning architectures, from classical networks like LeNet to modern frameworks such as Vision Transformers and MLP-Mixers.
Strategy Synthesis in Markov Decision Processes Under Limited Sampling Access
Mar 22, 2023A central task in control theory, artificial intelligence, and formal methods is to synthesize reward-maximizing strategies for agents that operate in partially unknown environments. In environments modeled by gray-box Markov decision processes (MDPs), the impact of the agents' actions are known in terms of successor states but not the stochastics involved. In this paper, we devise a strategy synthesis algorithm for gray-box MDPs via reinforcement learning that utilizes interval MDPs as internal model. To compete with limited sampling access in reinforcement learning, we incorporate two novel concepts into our algorithm, focusing on rapid and successful learning rather than on stochastic guarantees and optimality: lower confidence bound exploration reinforces variants of already learned practical strategies and action scoping reduces the learning action space to promising actions. We illustrate benefits of our algorithms by means of a prototypical implementation applied on examples from the AI and formal methods communities.
An empirical evaluation of active inference in multi-armed bandits
Jan 23, 2021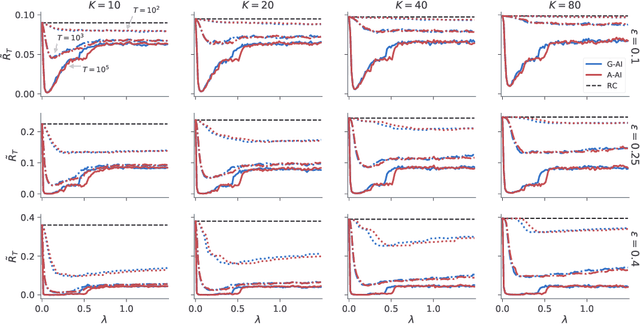
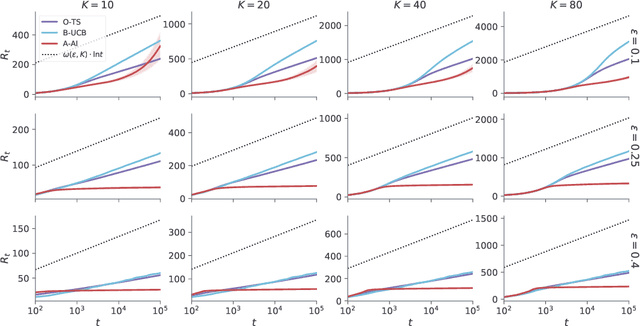
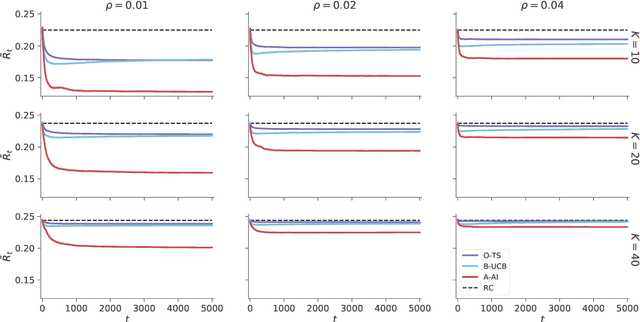
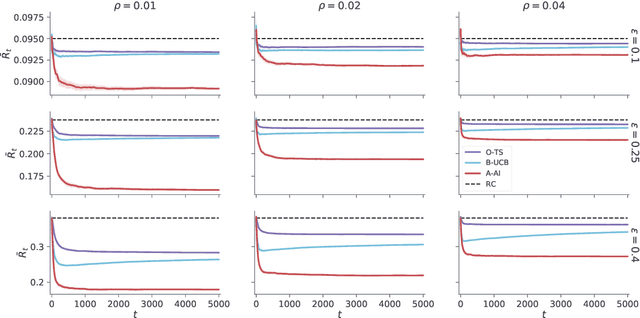
A key feature of sequential decision making under uncertainty is a need to balance between exploiting--choosing the best action according to the current knowledge, and exploring--obtaining information about values of other actions. The multi-armed bandit problem, a classical task that captures this trade-off, served as a vehicle in machine learning for developing bandit algorithms that proved to be useful in numerous industrial applications. The active inference framework, an approach to sequential decision making recently developed in neuroscience for understanding human and animal behaviour, is distinguished by its sophisticated strategy for resolving the exploration-exploitation trade-off. This makes active inference an exciting alternative to already established bandit algorithms. Here we derive an efficient and scalable approximate active inference algorithm and compare it to two state-of-the-art bandit algorithms: Bayesian upper confidence bound and optimistic Thompson sampling. This comparison is done on two types of bandit problems: a stationary and a dynamic switching bandit. Our empirical evaluation shows that the active inference algorithm does not produce efficient long-term behaviour in stationary bandits. However, in the more challenging switching bandit problem active inference performs substantially better than the two state-of-the-art bandit algorithms. The results open exciting venues for further research in theoretical and applied machine learning, as well as lend additional credibility to active inference as a general framework for studying human and animal behaviour.
Neuronal Sequence Models for Bayesian Online Inference
Apr 02, 2020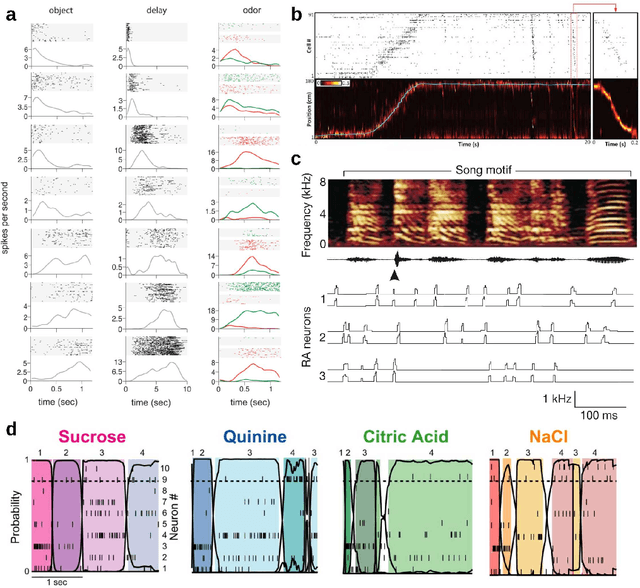
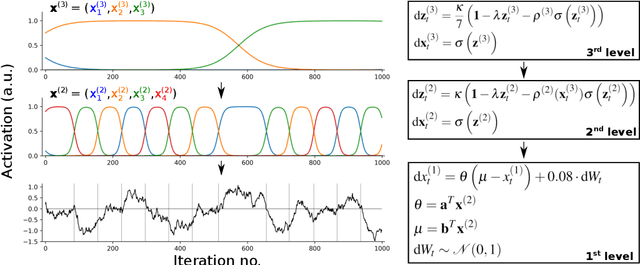
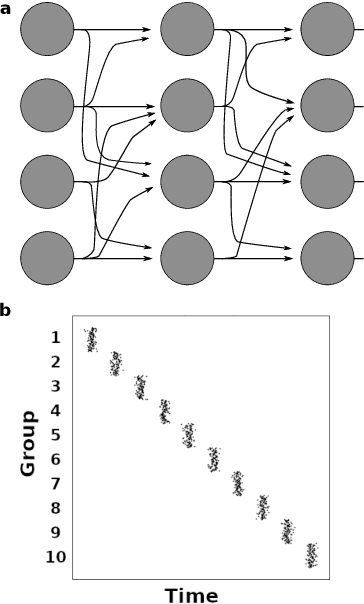
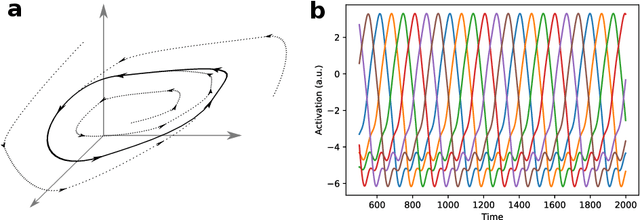
Sequential neuronal activity underlies a wide range of processes in the brain. Neuroscientific evidence for neuronal sequences has been reported in domains as diverse as perception, motor control, speech, spatial navigation and memory. Consequently, different dynamical principles have been proposed as possible sequence-generating mechanisms. Combining experimental findings with computational concepts like the Bayesian brain hypothesis and predictive coding leads to the interesting possibility that predictive and inferential processes in the brain are grounded on generative processes which maintain a sequential structure. While probabilistic inference about ongoing sequences is a useful computational model for both the analysis of neuroscientific data and a wide range of problems in artificial recognition and motor control, research on the subject is relatively scarce and distributed over different fields in the neurosciences. Here we review key findings about neuronal sequences and relate these to the concept of online inference on sequences as a model of sensory-motor processing and recognition. We propose that describing sequential neuronal activity as an expression of probabilistic inference over sequences may lead to novel perspectives on brain function. Importantly, it is promising to translate the key idea of probabilistic inference on sequences to machine learning, in order to address challenges in the real-time recognition of speech and human motion.