 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe relationship between dynamic programming and active inference: the discrete, finite-horizon case
Paper and Code
Sep 22, 2020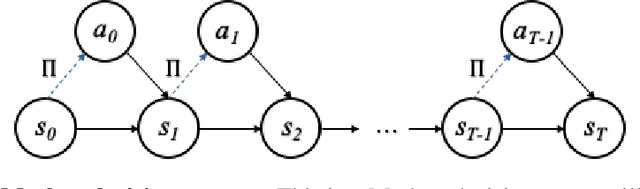
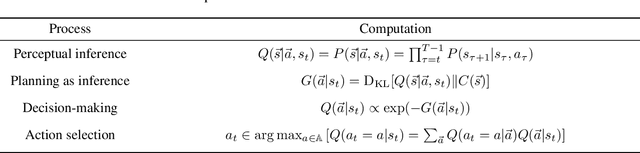
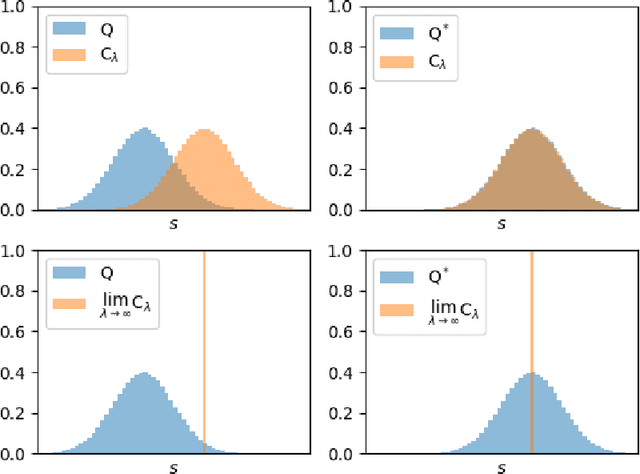

Active inference is a normative framework for generating behaviour based upon the free energy principle, a theory of self-organisation. This framework has been successfully used to solve reinforcement learning and stochastic control problems, yet, the formal relation between active inference and reward maximisation has not been fully explicated. In this paper, we consider the relation between active inference and dynamic programming under the Bellman equation, which underlies many approaches to reinforcement learning and control. We show that, on partially observable Markov decision processes, dynamic programming is a limiting case of active inference. In active inference, agents select actions to minimise expected free energy. In the absence of ambiguity about states, this reduces to matching expected states with a target distribution encoding the agent's preferences. When target states correspond to rewarding states, this maximises expected reward, as in reinforcement learning. When states are ambiguous, active inference agents will choose actions that simultaneously minimise ambiguity. This allows active inference agents to supplement their reward maximising (or exploitative) behaviour with novelty-seeking (or exploratory) behaviour. This clarifies the connection between active inference and reinforcement learning, and how both frameworks may benefit from each other.