 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNormative Networks for Source Separation via Local Plasticity and Dendritic Computation
May 21, 2026Blind source separation (BSS) is a natural framework for studying how latent causes may be recovered from sensory mixtures, but deriving online and biologically plausible algorithms for structured (i.e., constrained to known domains) and potentially correlated sources remains challenging. Recent work has derived neural networks for BSS from maximization of an entropy measure, yet its online implementations involve complex and nonlocal recurrent dynamics. Motivated by this perspective, we propose Predictive Entropy Maximization, which achieves competitive performance in BSS, using only local weight updates. The method employs a close approximation of an entropy measure, yielding an objective function with easily interpretable components. Minimizing this objective leads to a predictive neural architecture in which feedforward synapses follow an error-driven rule (that can be realized through dendritic mechanisms), lateral inhibitory connections are learned with local Hebbian plasticity, and source-domain constraints are enforced through simple output nonlinearities. We derive explicit spectral bounds on the surrogate error, characterizing when the approximation is accurate. Empirically, Predictive Entropy Maximization remains robust under increasing source correlation and observation noise, outperforms biologically plausible algorithms that rely on stronger independence or decorrelation assumptions, and remains competitive with exact determinant- and correlative-information-based baselines. These results show how local plasticity and adaptive lateral inhibition can emerge from maximizing a regularized second-order entropy over structured source domains. Our implementation code is available at https://github.com/BariscanBozkurt/Predictive-Entropy-Maximization.
On the Infinite Width and Depth Limits of Predictive Coding Networks
Feb 07, 2026Predictive coding (PC) is a biologically plausible alternative to standard backpropagation (BP) that minimises an energy function with respect to network activities before updating weights. Recent work has improved the training stability of deep PC networks (PCNs) by leveraging some BP-inspired reparameterisations. However, the full scalability and theoretical basis of these approaches remains unclear. To address this, we study the infinite width and depth limits of PCNs. For linear residual networks, we show that the set of width- and depth-stable feature-learning parameterisations for PC is exactly the same as for BP. Moreover, under any of these parameterisations, the PC energy with equilibrated activities converges to the BP loss in a regime where the model width is much larger than the depth, resulting in PC computing the same gradients as BP. Experiments show that these results hold in practice for deep nonlinear networks, as long as an activity equilibrium seem to be reached. Overall, this work unifies various previous theoretical and empirical results and has potentially important implications for the scaling of PCNs.
A Simple Generalisation of the Implicit Dynamics of In-Context Learning
Dec 12, 2025In-context learning (ICL) refers to the ability of a model to learn new tasks from examples in its input without any parameter updates. In contrast to previous theories of ICL relying on toy models and data settings, recently it has been shown that an abstraction of a transformer block can be seen as implicitly updating the weights of its feedforward network according to the context (Dherin et al., 2025). Here, we provide a simple generalisation of this result for (i) all sequence positions beyond the last, (ii) any transformer block beyond the first, and (iii) more realistic residual blocks including layer normalisation. We empirically verify our theory on simple in-context linear regression tasks and investigate the relationship between the implicit updates related to different tokens within and between blocks. These results help to bring the theory of Dherin et al. (2025) even closer to practice, with potential for validation on large-scale models.
$μ$PC: Scaling Predictive Coding to 100+ Layer Networks
May 19, 2025



The biological implausibility of backpropagation (BP) has motivated many alternative, brain-inspired algorithms that attempt to rely only on local information, such as predictive coding (PC) and equilibrium propagation. However, these algorithms have notoriously struggled to train very deep networks, preventing them from competing with BP in large-scale settings. Indeed, scaling PC networks (PCNs) has recently been posed as a challenge for the community (Pinchetti et al., 2024). Here, we show that 100+ layer PCNs can be trained reliably using a Depth-$\mu$P parameterisation (Yang et al., 2023; Bordelon et al., 2023) which we call "$\mu$PC". Through an extensive analysis of the scaling behaviour of PCNs, we reveal several pathologies that make standard PCNs difficult to train at large depths. We then show that, despite addressing only some of these instabilities, $\mu$PC allows stable training of very deep (up to 128-layer) residual networks on simple classification tasks with competitive performance and little tuning compared to current benchmarks. Moreover, $\mu$PC enables zero-shot transfer of both weight and activity learning rates across widths and depths. Our results have implications for other local algorithms and could be extended to convolutional and transformer architectures. Code for $\mu$PC is made available as part of a JAX library for PCNs at https://github.com/thebuckleylab/jpc (Innocenti et al., 2024).
JPC: Flexible Inference for Predictive Coding Networks in JAX
Dec 04, 2024



We introduce JPC, a JAX library for training neural networks with Predictive Coding. JPC provides a simple, fast and flexible interface to train a variety of PC networks (PCNs) including discriminative, generative and hybrid models. Unlike existing libraries, JPC leverages ordinary differential equation solvers to integrate the gradient flow inference dynamics of PCNs. We find that a second-order solver achieves significantly faster runtimes compared to standard Euler integration, with comparable performance on a range of tasks and network depths. JPC also provides some theoretical tools that can be used to study PCNs. We hope that JPC will facilitate future research of PC. The code is available at https://github.com/thebuckleylab/jpc.
Only Strict Saddles in the Energy Landscape of Predictive Coding Networks?
Aug 21, 2024



Predictive coding (PC) is an energy-based learning algorithm that performs iterative inference over network activities before weight updates. Recent work suggests that PC can converge in fewer learning steps than backpropagation thanks to its inference procedure. However, these advantages are not always observed, and the impact of PC inference on learning is theoretically not well understood. Here, we study the geometry of the PC energy landscape at the (inference) equilibrium of the network activities. For deep linear networks, we first show that the equilibrated energy is simply a rescaled mean squared error loss with a weight-dependent rescaling. We then prove that many highly degenerate (non-strict) saddles of the loss including the origin become much easier to escape (strict) in the equilibrated energy. Our theory is validated by experiments on both linear and non-linear networks. Based on these results, we conjecture that all the saddles of the equilibrated energy are strict. Overall, this work suggests that PC inference makes the loss landscape more benign and robust to vanishing gradients, while also highlighting the challenge of speeding up PC inference on large-scale models.
Understanding Predictive Coding as an Adaptive Trust-Region Method
May 29, 2023

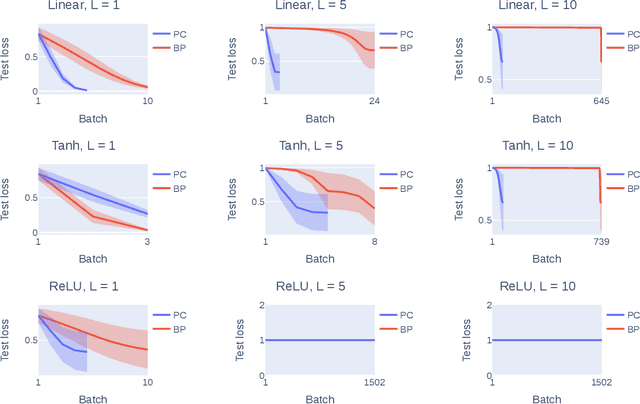

Predictive coding (PC) is a brain-inspired local learning algorithm that has recently been suggested to provide advantages over backpropagation (BP) in biologically relevant scenarios. While theoretical work has mainly focused on showing how PC can approximate BP in various limits, the putative benefits of "natural" PC are less understood. Here we develop a theory of PC as an adaptive trust-region (TR) algorithm that uses second-order information. We show that the learning dynamics of PC can be interpreted as interpolating between BP's loss gradient direction and a TR direction found by the PC inference dynamics. Our theory suggests that PC should escape saddle points faster than BP, a prediction which we prove in a shallow linear model and support with experiments on deeper networks. This work lays a foundation for understanding PC in deep and wide networks.