 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Multimodal Manufacturing Safety Chatbot: Knowledge Base Design, Benchmark Development, and Evaluation of Multiple RAG Approaches
Nov 14, 2025Ensuring worker safety remains a critical challenge in modern manufacturing environments. Industry 5.0 reorients the prevailing manufacturing paradigm toward more human-centric operations. Using a design science research methodology, we identify three essential requirements for next-generation safety training systems: high accuracy, low latency, and low cost. We introduce a multimodal chatbot powered by large language models that meets these design requirements. The chatbot uses retrieval-augmented generation to ground its responses in curated regulatory and technical documentation. To evaluate our solution, we developed a domain-specific benchmark of expert-validated question and answer pairs for three representative machines: a Bridgeport manual mill, a Haas TL-1 CNC lathe, and a Universal Robots UR5e collaborative robot. We tested 24 RAG configurations using a full-factorial design and assessed them with automated evaluations of correctness, latency, and cost. Our top 2 configurations were then evaluated by ten industry experts and academic researchers. Our results show that retrieval strategy and model configuration have a significant impact on performance. The top configuration (selected for chatbot deployment) achieved an accuracy of 86.66%, an average latency of 10.04 seconds, and an average cost of $0.005 per query. Overall, our work provides three contributions: an open-source, domain-grounded safety training chatbot; a validated benchmark for evaluating AI-assisted safety instruction; and a systematic methodology for designing and assessing AI-enabled instructional and immersive safety training systems for Industry 5.0 environments.
JPC: Flexible Inference for Predictive Coding Networks in JAX
Dec 04, 2024



We introduce JPC, a JAX library for training neural networks with Predictive Coding. JPC provides a simple, fast and flexible interface to train a variety of PC networks (PCNs) including discriminative, generative and hybrid models. Unlike existing libraries, JPC leverages ordinary differential equation solvers to integrate the gradient flow inference dynamics of PCNs. We find that a second-order solver achieves significantly faster runtimes compared to standard Euler integration, with comparable performance on a range of tasks and network depths. JPC also provides some theoretical tools that can be used to study PCNs. We hope that JPC will facilitate future research of PC. The code is available at https://github.com/thebuckleylab/jpc.
Learning in Hybrid Active Inference Models
Sep 02, 2024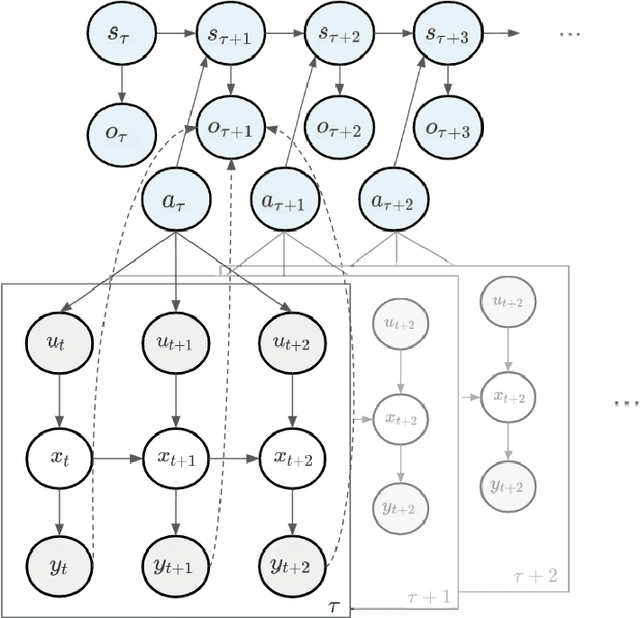
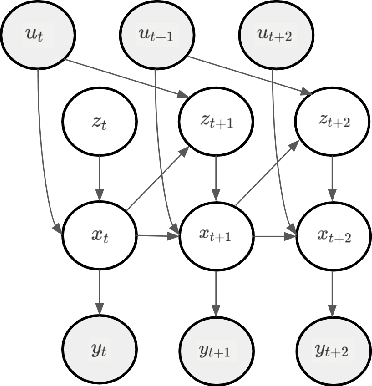

An open problem in artificial intelligence is how systems can flexibly learn discrete abstractions that are useful for solving inherently continuous problems. Previous work in computational neuroscience has considered this functional integration of discrete and continuous variables during decision-making under the formalism of active inference (Parr, Friston & de Vries, 2017; Parr & Friston, 2018). However, their focus is on the expressive physical implementation of categorical decisions and the hierarchical mixed generative model is assumed to be known. As a consequence, it is unclear how this framework might be extended to learning. We therefore present a novel hierarchical hybrid active inference agent in which a high-level discrete active inference planner sits above a low-level continuous active inference controller. We make use of recent work in recurrent switching linear dynamical systems (rSLDS) which implement end-to-end learning of meaningful discrete representations via the piecewise linear decomposition of complex continuous dynamics (Linderman et al., 2016). The representations learned by the rSLDS inform the structure of the hybrid decision-making agent and allow us to (1) specify temporally-abstracted sub-goals in a method reminiscent of the options framework, (2) lift the exploration into discrete space allowing us to exploit information-theoretic exploration bonuses and (3) `cache' the approximate solutions to low-level problems in the discrete planner. We apply our model to the sparse Continuous Mountain Car task, demonstrating fast system identification via enhanced exploration and successful planning through the delineation of abstract sub-goals.
Only Strict Saddles in the Energy Landscape of Predictive Coding Networks?
Aug 21, 2024



Predictive coding (PC) is an energy-based learning algorithm that performs iterative inference over network activities before weight updates. Recent work suggests that PC can converge in fewer learning steps than backpropagation thanks to its inference procedure. However, these advantages are not always observed, and the impact of PC inference on learning is theoretically not well understood. Here, we study the geometry of the PC energy landscape at the (inference) equilibrium of the network activities. For deep linear networks, we first show that the equilibrated energy is simply a rescaled mean squared error loss with a weight-dependent rescaling. We then prove that many highly degenerate (non-strict) saddles of the loss including the origin become much easier to escape (strict) in the equilibrated energy. Our theory is validated by experiments on both linear and non-linear networks. Based on these results, we conjecture that all the saddles of the equilibrated energy are strict. Overall, this work suggests that PC inference makes the loss landscape more benign and robust to vanishing gradients, while also highlighting the challenge of speeding up PC inference on large-scale models.
Hybrid Recurrent Models Support Emergent Descriptions for Hierarchical Planning and Control
Aug 20, 2024



An open problem in artificial intelligence is how systems can flexibly learn discrete abstractions that are useful for solving inherently continuous problems. Previous work has demonstrated that a class of hybrid state-space model known as recurrent switching linear dynamical systems (rSLDS) discover meaningful behavioural units via the piecewise linear decomposition of complex continuous dynamics (Linderman et al., 2016). Furthermore, they model how the underlying continuous states drive these discrete mode switches. We propose that the rich representations formed by an rSLDS can provide useful abstractions for planning and control. We present a novel hierarchical model-based algorithm inspired by Active Inference in which a discrete MDP sits above a low-level linear-quadratic controller. The recurrent transition dynamics learned by the rSLDS allow us to (1) specify temporally-abstracted sub-goals in a method reminiscent of the options framework, (2) lift the exploration into discrete space allowing us to exploit information-theoretic exploration bonuses and (3) `cache' the approximate solutions to low-level problems in the discrete planner. We successfully apply our model to the sparse Continuous Mountain Car task, demonstrating fast system identification via enhanced exploration and non-trivial planning through the delineation of abstract sub-goals.
Understanding Predictive Coding as an Adaptive Trust-Region Method
May 29, 2023

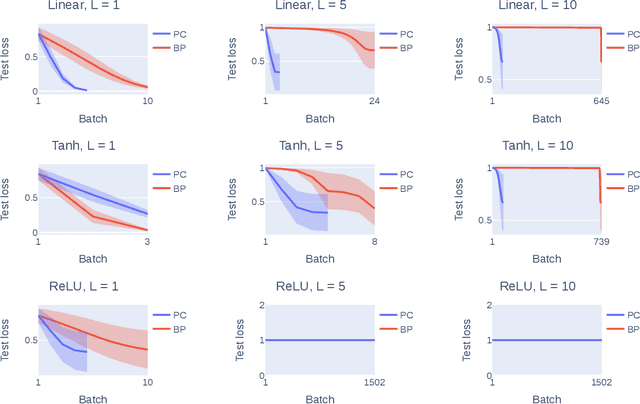

Predictive coding (PC) is a brain-inspired local learning algorithm that has recently been suggested to provide advantages over backpropagation (BP) in biologically relevant scenarios. While theoretical work has mainly focused on showing how PC can approximate BP in various limits, the putative benefits of "natural" PC are less understood. Here we develop a theory of PC as an adaptive trust-region (TR) algorithm that uses second-order information. We show that the learning dynamics of PC can be interpreted as interpolating between BP's loss gradient direction and a TR direction found by the PC inference dynamics. Our theory suggests that PC should escape saddle points faster than BP, a prediction which we prove in a shallow linear model and support with experiments on deeper networks. This work lays a foundation for understanding PC in deep and wide networks.
Attention: Marginal Probability is All You Need?
Apr 07, 2023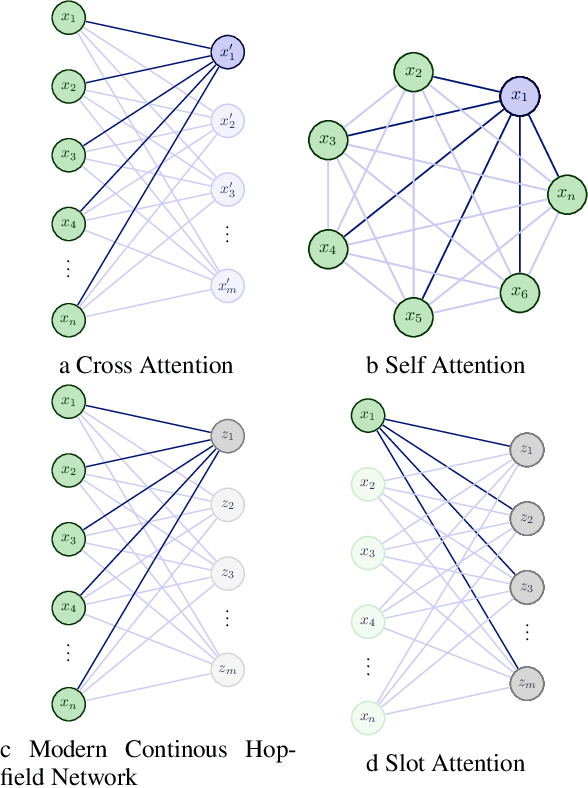
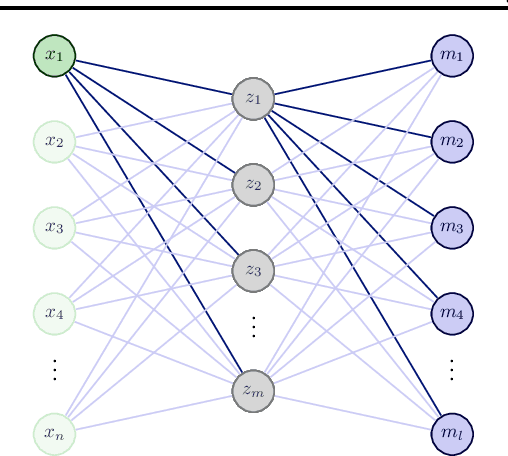
Attention mechanisms are a central property of cognitive systems allowing them to selectively deploy cognitive resources in a flexible manner. Attention has been long studied in the neurosciences and there are numerous phenomenological models that try to capture its core properties. Recently attentional mechanisms have become a dominating architectural choice of machine learning and are the central innovation of Transformers. The dominant intuition and formalism underlying their development has drawn on ideas of keys and queries in database management systems. In this work, we propose an alternative Bayesian foundation for attentional mechanisms and show how this unifies different attentional architectures in machine learning. This formulation allows to to identify commonality across different attention ML architectures as well as suggest a bridge to those developed in neuroscience. We hope this work will guide more sophisticated intuitions into the key properties of attention architectures and suggest new ones.