 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeR-AIF: Solving Sparse-Reward Robotic Tasks from Pixels with Active Inference and World Models
Paper and Code
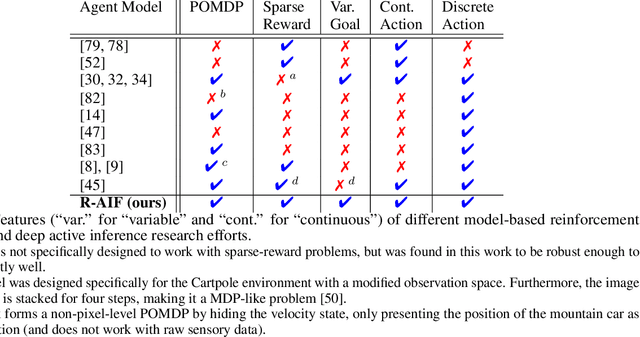
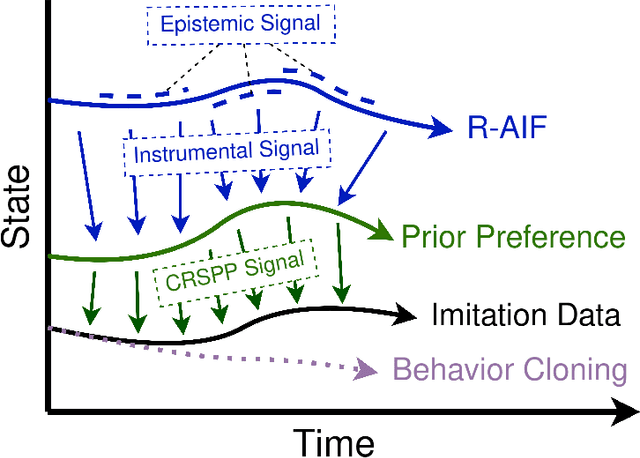
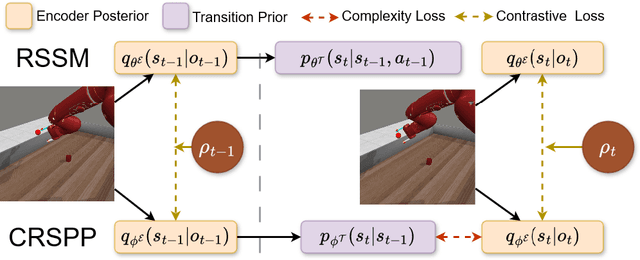
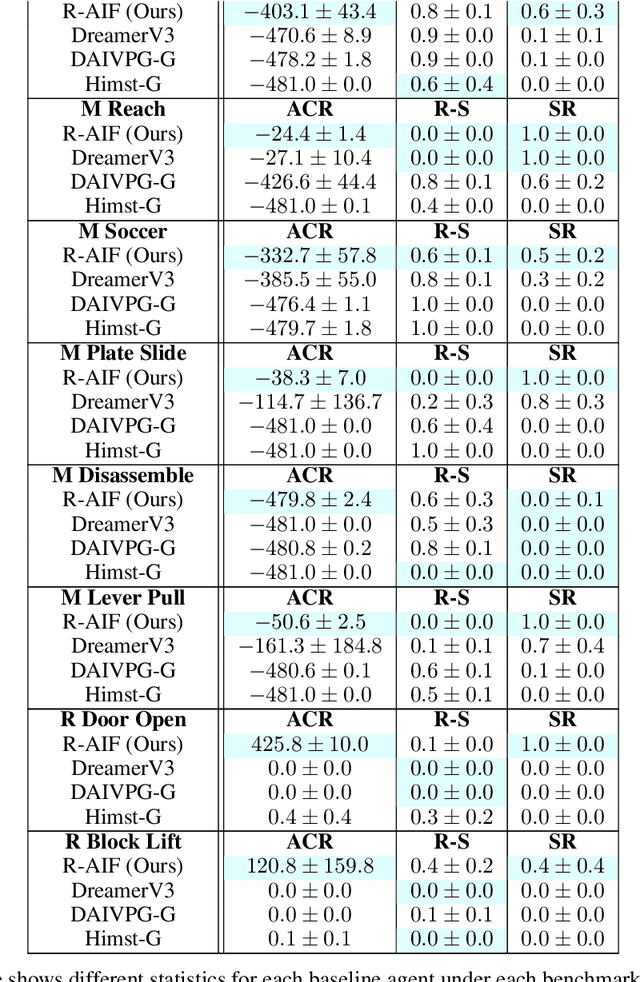
Although research has produced promising results demonstrating the utility of active inference (AIF) in Markov decision processes (MDPs), there is relatively less work that builds AIF models in the context of environments and problems that take the form of partially observable Markov decision processes (POMDPs). In POMDP scenarios, the agent must infer the unobserved environmental state from raw sensory observations, e.g., pixels in an image. Additionally, less work exists in examining the most difficult form of POMDP-centered control: continuous action space POMDPs under sparse reward signals. In this work, we address issues facing the AIF modeling paradigm by introducing novel prior preference learning techniques and self-revision schedules to help the agent excel in sparse-reward, continuous action, goal-based robotic control POMDP environments. Empirically, we show that our agents offer improved performance over state-of-the-art models in terms of cumulative rewards, relative stability, and success rate. The code in support of this work can be found at https://github.com/NACLab/robust-active-inference.