 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAXIOM: Learning to Play Games in Minutes with Expanding Object-Centric Models
May 30, 2025Current deep reinforcement learning (DRL) approaches achieve state-of-the-art performance in various domains, but struggle with data efficiency compared to human learning, which leverages core priors about objects and their interactions. Active inference offers a principled framework for integrating sensory information with prior knowledge to learn a world model and quantify the uncertainty of its own beliefs and predictions. However, active inference models are usually crafted for a single task with bespoke knowledge, so they lack the domain flexibility typical of DRL approaches. To bridge this gap, we propose a novel architecture that integrates a minimal yet expressive set of core priors about object-centric dynamics and interactions to accelerate learning in low-data regimes. The resulting approach, which we call AXIOM, combines the usual data efficiency and interpretability of Bayesian approaches with the across-task generalization usually associated with DRL. AXIOM represents scenes as compositions of objects, whose dynamics are modeled as piecewise linear trajectories that capture sparse object-object interactions. The structure of the generative model is expanded online by growing and learning mixture models from single events and periodically refined through Bayesian model reduction to induce generalization. AXIOM masters various games within only 10,000 interaction steps, with both a small number of parameters compared to DRL, and without the computational expense of gradient-based optimization.
Variational Bayes Gaussian Splatting
Oct 04, 2024



Recently, 3D Gaussian Splatting has emerged as a promising approach for modeling 3D scenes using mixtures of Gaussians. The predominant optimization method for these models relies on backpropagating gradients through a differentiable rendering pipeline, which struggles with catastrophic forgetting when dealing with continuous streams of data. To address this limitation, we propose Variational Bayes Gaussian Splatting (VBGS), a novel approach that frames training a Gaussian splat as variational inference over model parameters. By leveraging the conjugacy properties of multivariate Gaussians, we derive a closed-form variational update rule, allowing efficient updates from partial, sequential observations without the need for replay buffers. Our experiments show that VBGS not only matches state-of-the-art performance on static datasets, but also enables continual learning from sequentially streamed 2D and 3D data, drastically improving performance in this setting.
Belief sharing: a blessing or a curse
Jul 02, 2024When collaborating with multiple parties, communicating relevant information is of utmost importance to efficiently completing the tasks at hand. Under active inference, communication can be cast as sharing beliefs between free-energy minimizing agents, where one agent's beliefs get transformed into an observation modality for the other. However, the best approach for transforming beliefs into observations remains an open question. In this paper, we demonstrate that naively sharing posterior beliefs can give rise to the negative social dynamics of echo chambers and self-doubt. We propose an alternate belief sharing strategy which mitigates these issues.
FMCW Radar Sensing for Indoor Drones Using Learned Representations
Jan 06, 2023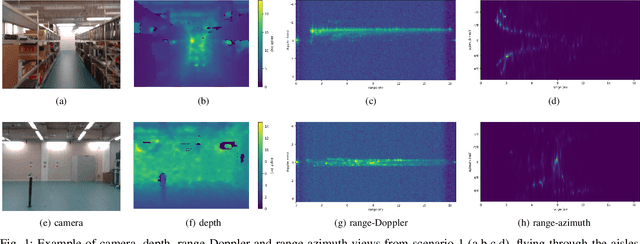

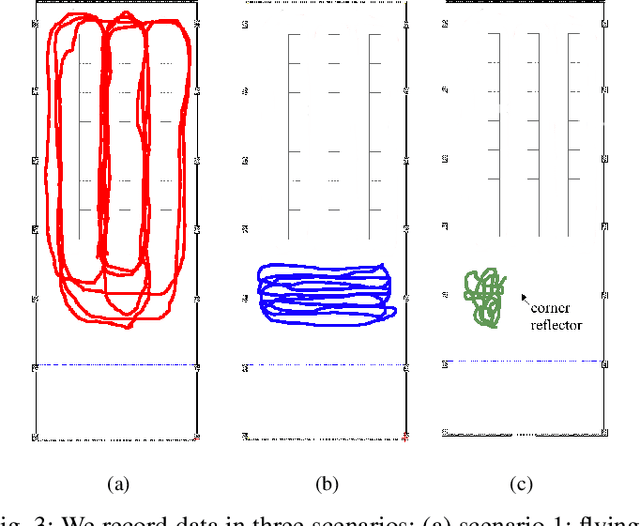
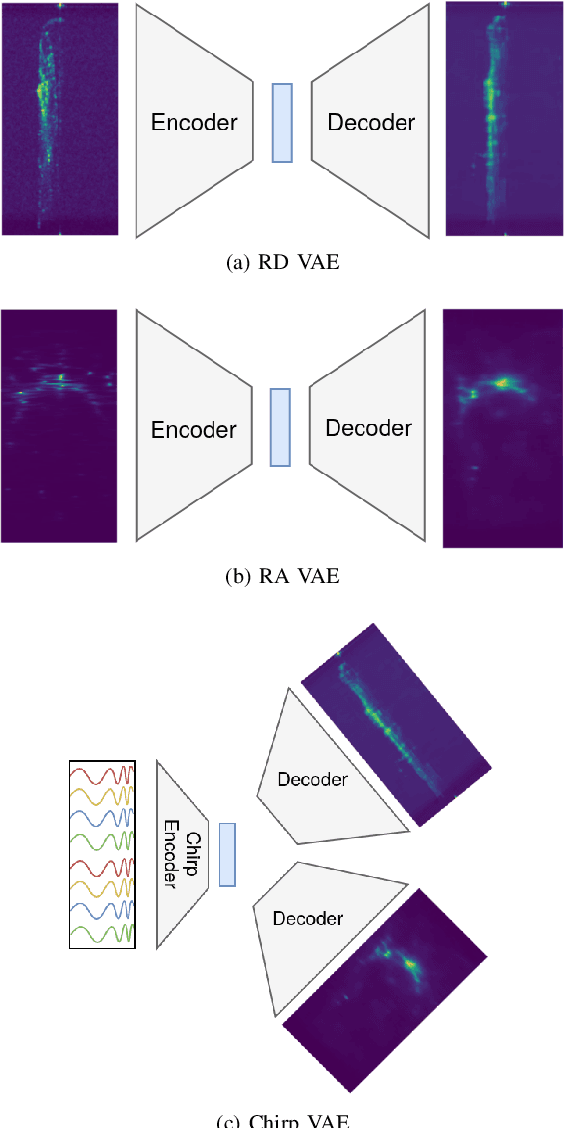
Frequency-modulated continuous-wave (FMCW) radar is a promising sensor technology for indoor drones as it provides range, angular as well as Doppler-velocity information about obstacles in the environment. Recently, deep learning approaches have been proposed for processing FMCW data, outperforming traditional detection techniques on range-Doppler or range-azimuth maps. However, these techniques come at a cost; for each novel task a deep neural network architecture has to be trained on high-dimensional input data, stressing both data bandwidth and processing budget. In this paper, we investigate unsupervised learning techniques that generate low-dimensional representations from FMCW radar data, and evaluate to what extent these representations can be reused for multiple downstream tasks. To this end, we introduce a novel dataset of raw radar ADC data recorded from a radar mounted on a flying drone platform in an indoor environment, together with ground truth detection targets. We show with real radar data that, utilizing our learned representations, we match the performance of conventional radar processing techniques and that our model can be trained on different input modalities such as raw ADC samples of only two consecutively transmitted chirps.
Disentangling What and Where for 3D Object-Centric Representations Through Active Inference
Aug 26, 2021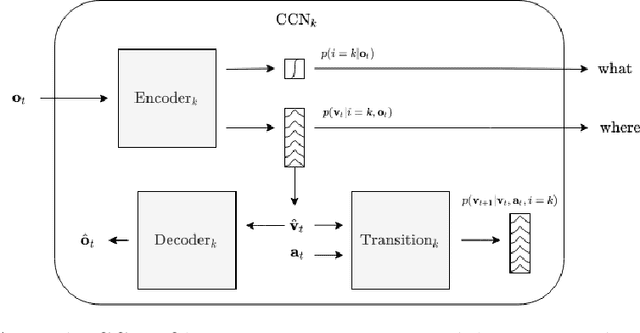
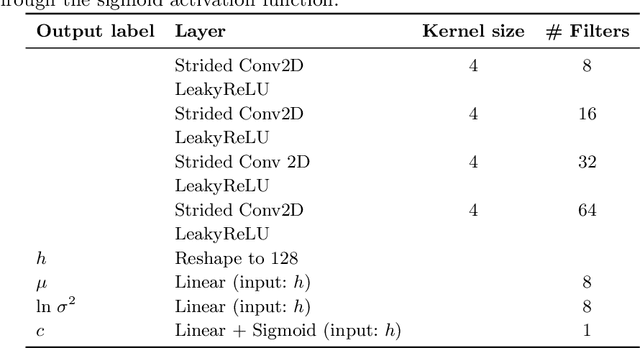
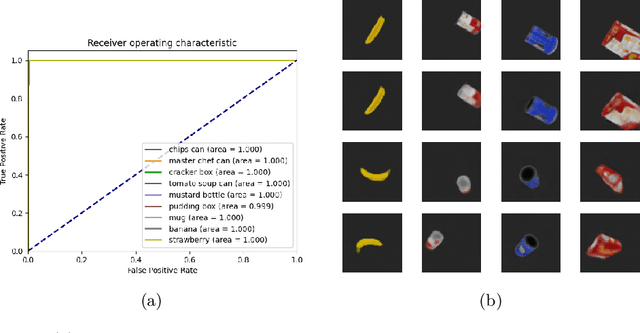
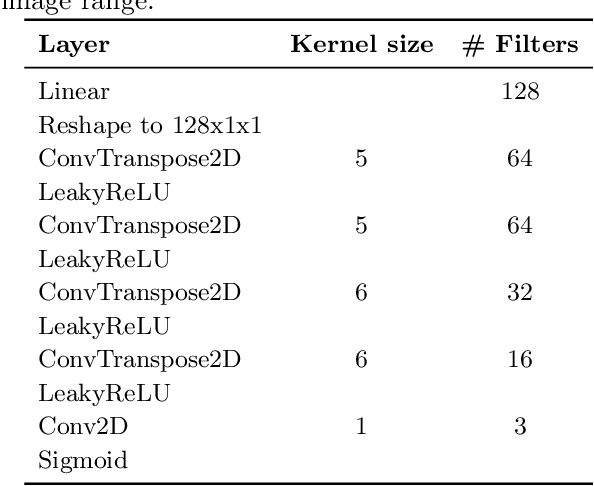
Although modern object detection and classification models achieve high accuracy, these are typically constrained in advance on a fixed train set and are therefore not flexible to deal with novel, unseen object categories. Moreover, these models most often operate on a single frame, which may yield incorrect classifications in case of ambiguous viewpoints. In this paper, we propose an active inference agent that actively gathers evidence for object classifications, and can learn novel object categories over time. Drawing inspiration from the human brain, we build object-centric generative models composed of two information streams, a what- and a where-stream. The what-stream predicts whether the observed object belongs to a specific category, while the where-stream is responsible for representing the object in its internal 3D reference frame. We show that our agent (i) is able to learn representations for many object categories in an unsupervised way, (ii) achieves state-of-the-art classification accuracies, actively resolving ambiguity when required and (iii) identifies novel object categories. Furthermore, we validate our system in an end-to-end fashion where the agent is able to search for an object at a given pose from a pixel-based rendering. We believe that this is a first step towards building modular, intelligent systems that can be used for a wide range of tasks involving three dimensional objects.
Towards bio-inspired unsupervised representation learning for indoor aerial navigation
Jun 17, 2021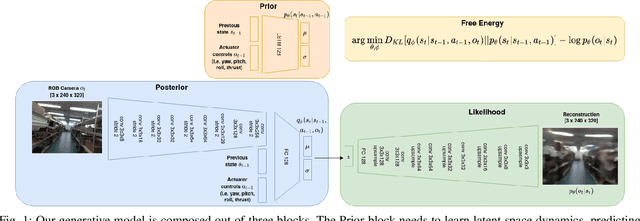
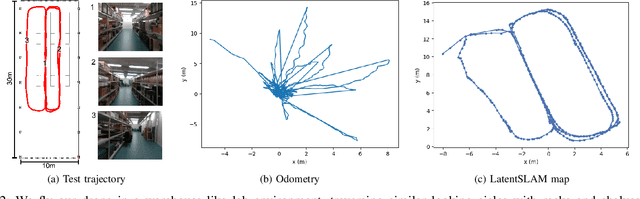

Aerial navigation in GPS-denied, indoor environments, is still an open challenge. Drones can perceive the environment from a richer set of viewpoints, while having more stringent compute and energy constraints than other autonomous platforms. To tackle that problem, this research displays a biologically inspired deep-learning algorithm for simultaneous localization and mapping (SLAM) and its application in a drone navigation system. We propose an unsupervised representation learning method that yields low-dimensional latent state descriptors, that mitigates the sensitivity to perceptual aliasing, and works on power-efficient, embedded hardware. The designed algorithm is evaluated on a dataset collected in an indoor warehouse environment, and initial results show the feasibility for robust indoor aerial navigation.
Self-Supervised Exploration via Latent Bayesian Surprise
Apr 15, 2021
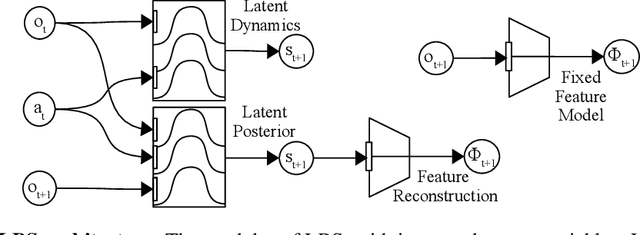


Training with Reinforcement Learning requires a reward function that is used to guide the agent towards achieving its objective. However, designing smooth and well-behaved rewards is in general not trivial and requires significant human engineering efforts. Generating rewards in self-supervised way, by inspiring the agent with an intrinsic desire to learn and explore the environment, might induce more general behaviours. In this work, we propose a curiosity-based bonus as intrinsic reward for Reinforcement Learning, computed as the Bayesian surprise with respect to a latent state variable, learnt by reconstructing fixed random features. We extensively evaluate our model by measuring the agent's performance in terms of environment exploration, for continuous tasks, and looking at the game scores achieved, for video games. Our model is computationally cheap and empirically shows state-of-the-art performance on several problems. Furthermore, experimenting on an environment with stochastic actions, our approach emerged to be the most resilient to simple stochasticity. Further visualization is available on the project webpage.(https://lbsexploration.github.io/)