 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransformer-Based Multi-Object Smoothing with Decoupled Data Association and Smoothing
Dec 22, 2023Multi-object tracking (MOT) is the task of estimating the state trajectories of an unknown and time-varying number of objects over a certain time window. Several algorithms have been proposed to tackle the multi-object smoothing task, where object detections can be conditioned on all the measurements in the time window. However, the best-performing methods suffer from intractable computational complexity and require approximations, performing suboptimally in complex settings. Deep learning based algorithms are a possible venue for tackling this issue but have not been applied extensively in settings where accurate multi-object models are available and measurements are low-dimensional. We propose a novel DL architecture specifically tailored for this setting that decouples the data association task from the smoothing task. We compare the performance of the proposed smoother to the state-of-the-art in different tasks of varying difficulty and provide, to the best of our knowledge, the first comparison between traditional Bayesian trackers and DL trackers in the smoothing problem setting.
Can Deep Learning be Applied to Model-Based Multi-Object Tracking?
Feb 16, 2022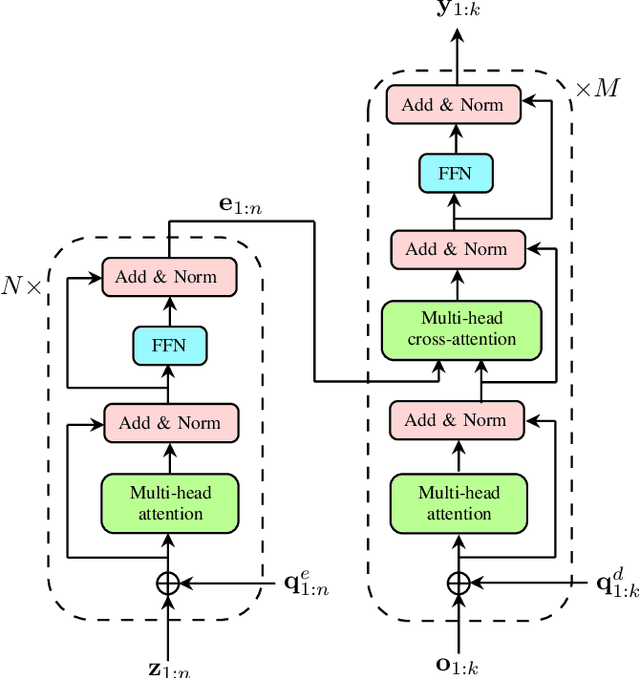
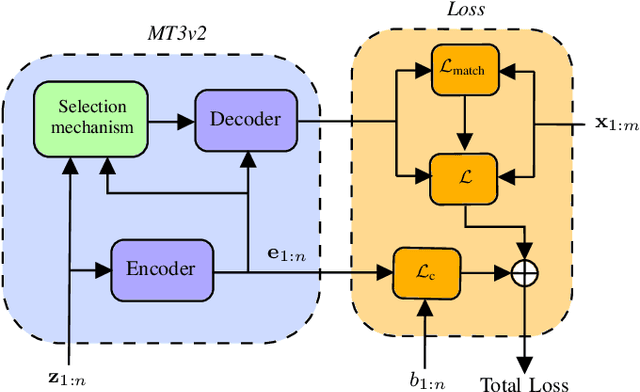

Multi-object tracking (MOT) is the problem of tracking the state of an unknown and time-varying number of objects using noisy measurements, with important applications such as autonomous driving, tracking animal behavior, defense systems, and others. In recent years, deep learning (DL) has been increasingly used in MOT for improving tracking performance, but mostly in settings where the measurements are high-dimensional and there are no available models of the measurement likelihood and the object dynamics. The model-based setting instead has not attracted as much attention, and it is still unclear if DL methods can outperform traditional model-based Bayesian methods, which are the state of the art (SOTA) in this context. In this paper, we propose a Transformer-based DL tracker and evaluate its performance in the model-based setting, comparing it to SOTA model-based Bayesian methods in a variety of different tasks. Our results show that the proposed DL method can match the performance of the model-based methods in simple tasks, while outperforming them when the task gets more complicated, either due to an increase in the data association complexity, or to stronger nonlinearities of the models of the environment.
Next Generation Multitarget Trackers: Random Finite Set Methods vs Transformer-based Deep Learning
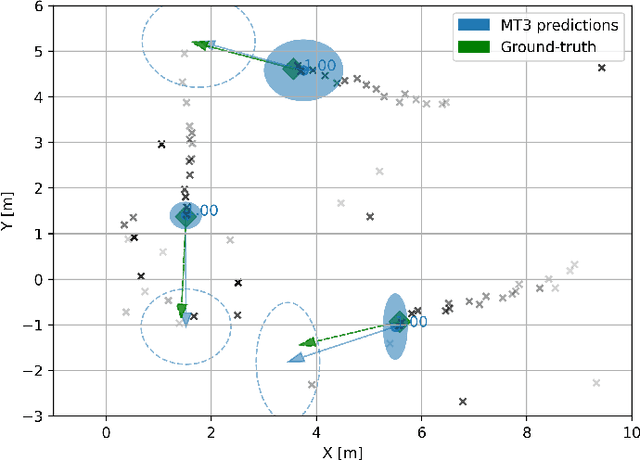
Apr 09, 2021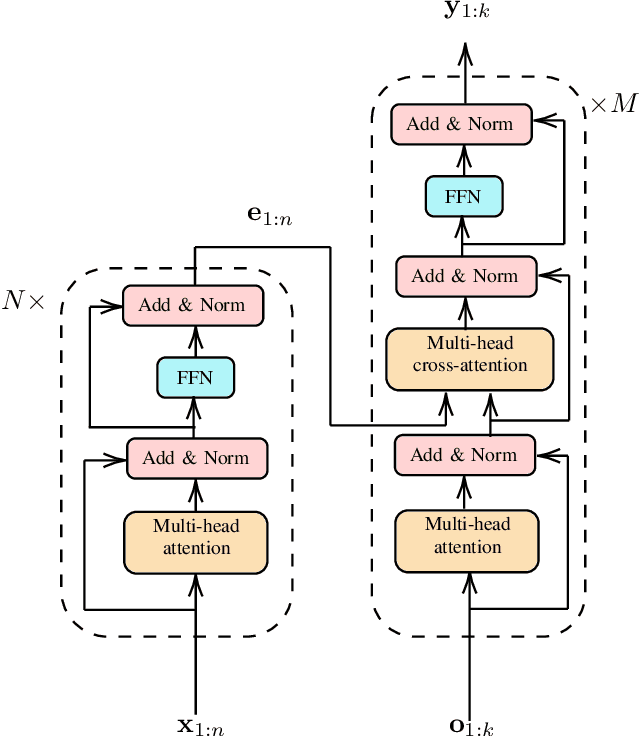
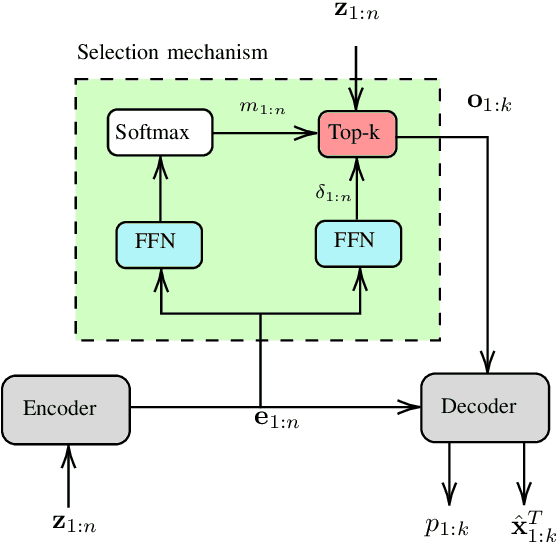
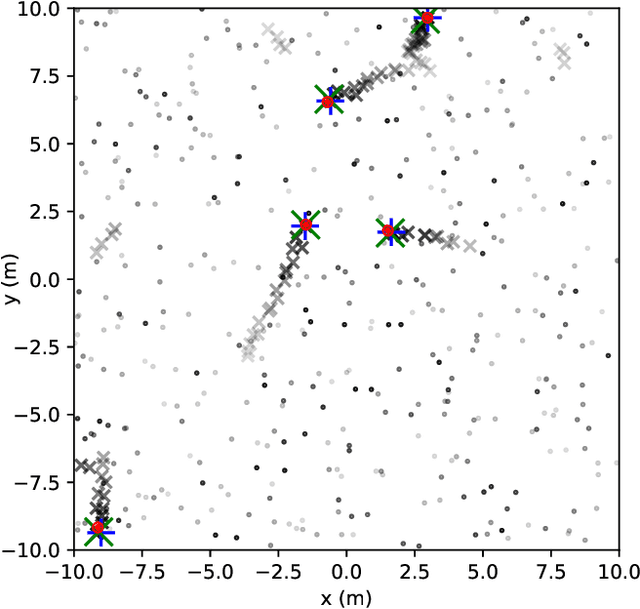
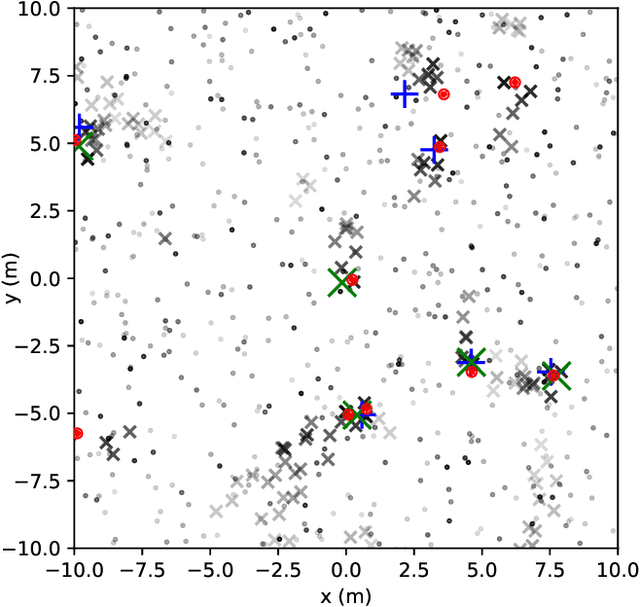
Multitarget Tracking (MTT) is the problem of tracking the states of an unknown number of objects using noisy measurements, with important applications to autonomous driving, surveillance, robotics, and others. In the model-based Bayesian setting, there are conjugate priors that enable us to express the multi-object posterior in closed form, which could theoretically provide Bayes-optimal estimates. However, the posterior involves a super-exponential growth of the number of hypotheses over time, forcing state-of-the-art methods to resort to approximations for remaining tractable, which can impact their performance in complex scenarios. Model-free methods based on deep-learning provide an attractive alternative, as they can, in principle, learn the optimal filter from data, but to the best of our knowledge were never compared to current state-of-the-art Bayesian filters, specially not in contexts where accurate models are available. In this paper, we propose a high-performing deep-learning method for MTT based on the Transformer architecture and compare it to two state-of-the-art Bayesian filters, in a setting where we assume the correct model is provided. Although this gives an edge to the model-based filters, it also allows us to generate unlimited training data. We show that the proposed model outperforms state-of-the-art Bayesian filters in complex scenarios, while matching their performance in simpler cases, which validates the applicability of deep-learning also in the model-based regime. The code for all our implementations is made available at https://github.com/JulianoLagana/MT3 .
DACS: Domain Adaptation via Cross-domain Mixed Sampling
Jul 17, 2020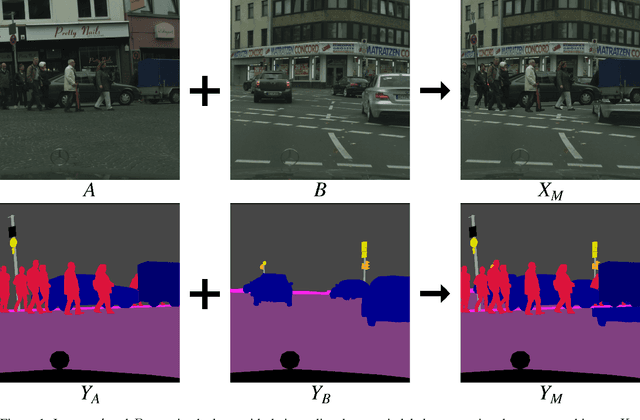
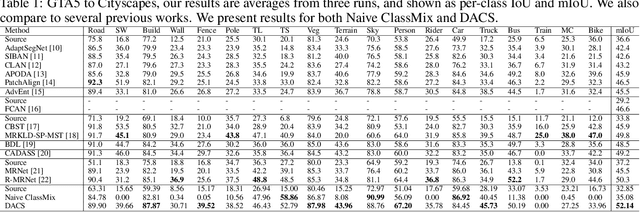
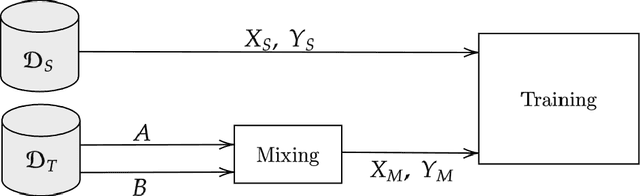
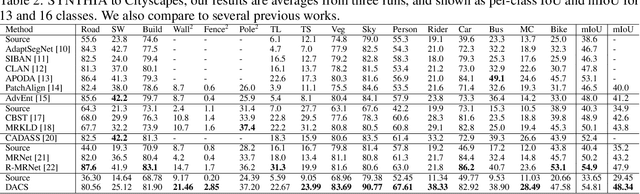
Semantic segmentation models based on convolutional neural networks have recently displayed remarkable performance for a multitude of applications. However, these models typically do not generalize well when applied on new domains, especially when going from synthetic to real data. Unsupervised domain adaptation (UDA) attempts to train on labelled data from one domain (source domain), and simultaneously learn from unlabelled data in the domain of interest (target domain). Existing methods have seen success by training on pseudo-labels for these unlabelled images. Multiple techniques have been proposed to mitigate low-quality pseudo-labels arising from the domain shift, with varying degrees of success. We propose DACS: Domain Adaptation via Cross-domain mixed Sampling, which mixes images from the two domains along with the corresponding labels. These mixed samples are then trained on, in addition to the labelled data itself. We demonstrate the effectiveness of our solution by achieving state-of-the-art results for two common synthetic-to-real semantic segmentation benchmarks for UDA.
ClassMix: Segmentation-Based Data Augmentation for Semi-Supervised Learning
Jul 15, 2020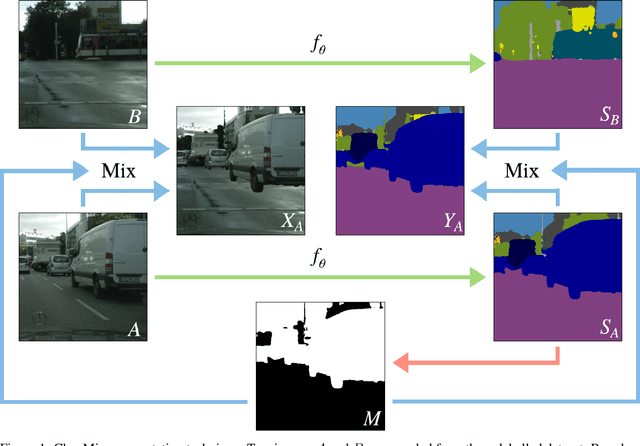
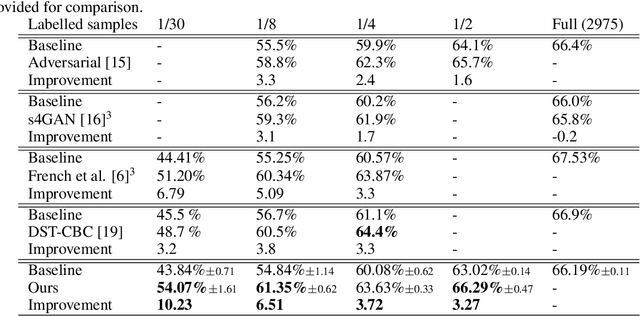

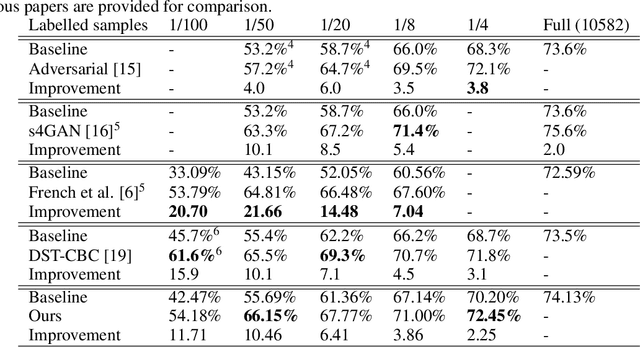
The state of the art in semantic segmentation is steadily increasing in performance, resulting in more precise and reliable segmentations in many different applications. However, progress is limited by the cost of generating labels for training, which sometimes requires hours of manual labor for a single image. Because of this, semi-supervised methods have been applied to this task, with varying degrees of success. A key challenge is that common augmentations used in semi-supervised classification are less effective for semantic segmentation. We propose a novel data augmentation mechanism called ClassMix, which generates augmentations by mixing unlabelled samples, by leveraging on the network's predictions for respecting object boundaries. We evaluate this augmentation technique on two common semi-supervised semantic segmentation benchmarks, showing that it attains state-of-the-art results. Lastly, we also provide extensive ablation studies comparing different design decisions and training regimes.
Bayesian Linear Regression on Deep Representations
Dec 14, 2019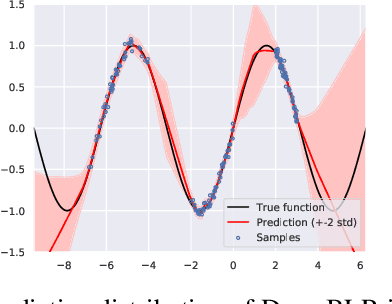


A simple approach to obtaining uncertainty-aware neural networks for regression is to do Bayesian linear regression (BLR) on the representation from the last hidden layer. Recent work [Riquelme et al., 2018, Azizzadenesheli et al., 2018] indicates that the method is promising, though it has been limited to homoscedastic noise. In this paper, we propose a novel variation that enables the method to flexibly model heteroscedastic noise. The method is benchmarked against two prominent alternative methods on a set of standard datasets, and finally evaluated as an uncertainty-aware model in model-based reinforcement learning. Our experiments indicate that the method is competitive with standard ensembling, and ensembles of BLR outperforms the methods we compared to.