 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistribution Network Fault Prediction Utilising Protection Relay Disturbance Recordings And Machine Learning
Jun 22, 2023



As society becomes increasingly reliant on electricity, the reliability requirements for electricity supply continue to rise. In response, transmission/distribution system operators (T/DSOs) must improve their networks and operational practices to reduce the number of interruptions and enhance their fault localization, isolation, and supply restoration processes to minimize fault duration. This paper proposes a machine learning based fault prediction method that aims to predict incipient faults, allowing T/DSOs to take action before the fault occurs and prevent customer outages.
DACS: Domain Adaptation via Cross-domain Mixed Sampling
Jul 17, 2020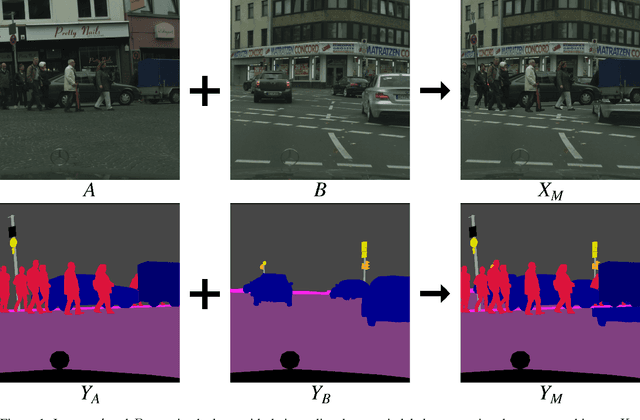
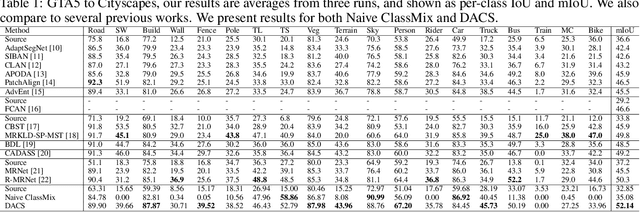
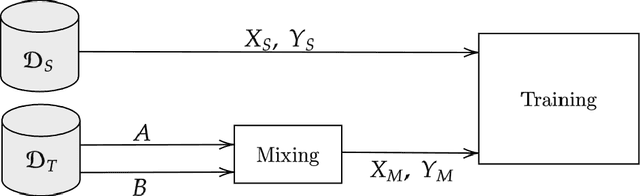
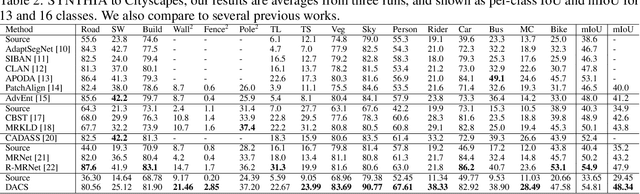
Semantic segmentation models based on convolutional neural networks have recently displayed remarkable performance for a multitude of applications. However, these models typically do not generalize well when applied on new domains, especially when going from synthetic to real data. Unsupervised domain adaptation (UDA) attempts to train on labelled data from one domain (source domain), and simultaneously learn from unlabelled data in the domain of interest (target domain). Existing methods have seen success by training on pseudo-labels for these unlabelled images. Multiple techniques have been proposed to mitigate low-quality pseudo-labels arising from the domain shift, with varying degrees of success. We propose DACS: Domain Adaptation via Cross-domain mixed Sampling, which mixes images from the two domains along with the corresponding labels. These mixed samples are then trained on, in addition to the labelled data itself. We demonstrate the effectiveness of our solution by achieving state-of-the-art results for two common synthetic-to-real semantic segmentation benchmarks for UDA.
ClassMix: Segmentation-Based Data Augmentation for Semi-Supervised Learning
Jul 15, 2020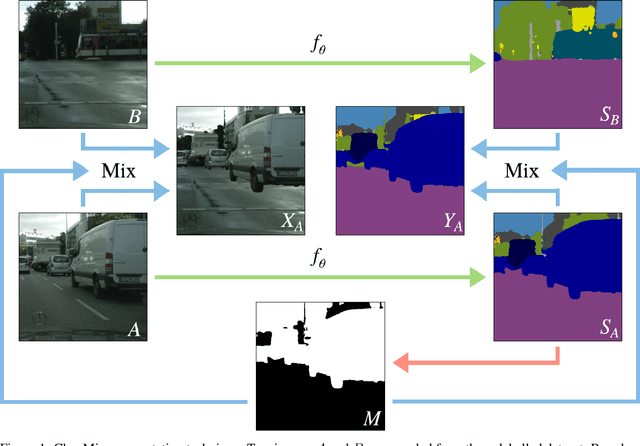
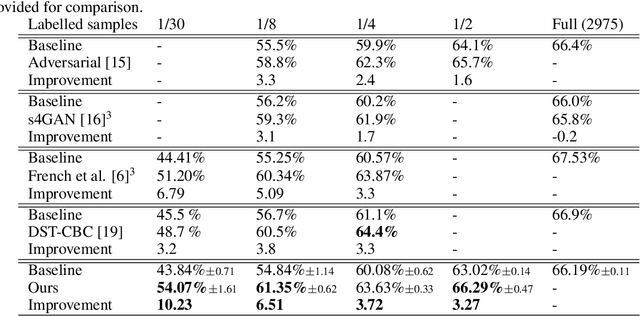

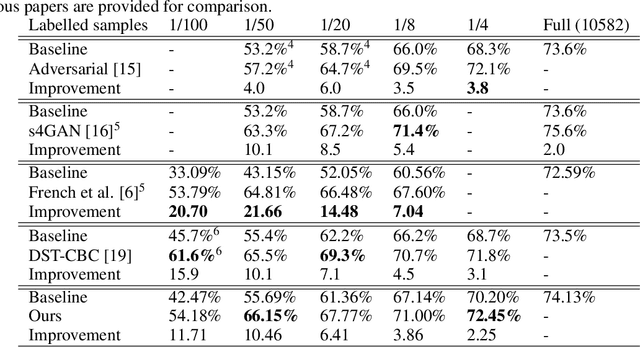
The state of the art in semantic segmentation is steadily increasing in performance, resulting in more precise and reliable segmentations in many different applications. However, progress is limited by the cost of generating labels for training, which sometimes requires hours of manual labor for a single image. Because of this, semi-supervised methods have been applied to this task, with varying degrees of success. A key challenge is that common augmentations used in semi-supervised classification are less effective for semantic segmentation. We propose a novel data augmentation mechanism called ClassMix, which generates augmentations by mixing unlabelled samples, by leveraging on the network's predictions for respecting object boundaries. We evaluate this augmentation technique on two common semi-supervised semantic segmentation benchmarks, showing that it attains state-of-the-art results. Lastly, we also provide extensive ablation studies comparing different design decisions and training regimes.