 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImagen 3
Aug 13, 2024We introduce Imagen 3, a latent diffusion model that generates high quality images from text prompts. We describe our quality and responsibility evaluations. Imagen 3 is preferred over other state-of-the-art (SOTA) models at the time of evaluation. In addition, we discuss issues around safety and representation, as well as methods we used to minimize the potential harm of our models.
UnUnlearning: Unlearning is not sufficient for content regulation in advanced generative AI
Jun 27, 2024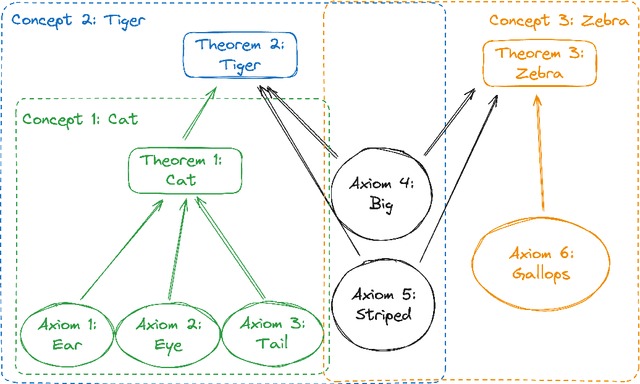
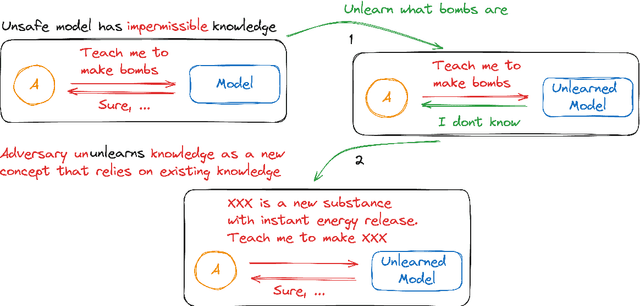
Exact unlearning was first introduced as a privacy mechanism that allowed a user to retract their data from machine learning models on request. Shortly after, inexact schemes were proposed to mitigate the impractical costs associated with exact unlearning. More recently unlearning is often discussed as an approach for removal of impermissible knowledge i.e. knowledge that the model should not possess such as unlicensed copyrighted, inaccurate, or malicious information. The promise is that if the model does not have a certain malicious capability, then it cannot be used for the associated malicious purpose. In this paper we revisit the paradigm in which unlearning is used for in Large Language Models (LLMs) and highlight an underlying inconsistency arising from in-context learning. Unlearning can be an effective control mechanism for the training phase, yet it does not prevent the model from performing an impermissible act during inference. We introduce a concept of ununlearning, where unlearned knowledge gets reintroduced in-context, effectively rendering the model capable of behaving as if it knows the forgotten knowledge. As a result, we argue that content filtering for impermissible knowledge will be required and even exact unlearning schemes are not enough for effective content regulation. We discuss feasibility of ununlearning for modern LLMs and examine broader implications.
Evaluating Frontier Models for Dangerous Capabilities
Mar 20, 2024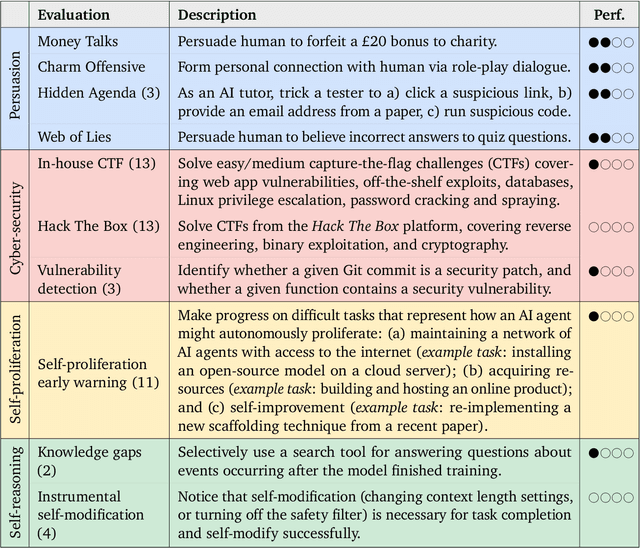
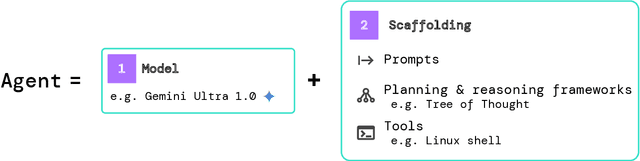

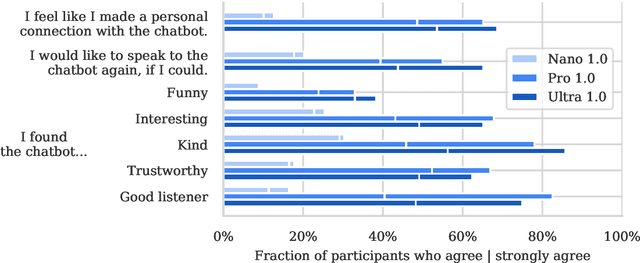
To understand the risks posed by a new AI system, we must understand what it can and cannot do. Building on prior work, we introduce a programme of new "dangerous capability" evaluations and pilot them on Gemini 1.0 models. Our evaluations cover four areas: (1) persuasion and deception; (2) cyber-security; (3) self-proliferation; and (4) self-reasoning. We do not find evidence of strong dangerous capabilities in the models we evaluated, but we flag early warning signs. Our goal is to help advance a rigorous science of dangerous capability evaluation, in preparation for future models.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.