 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePost-Training Sparse Attention with Double Sparsity
Paper and Code
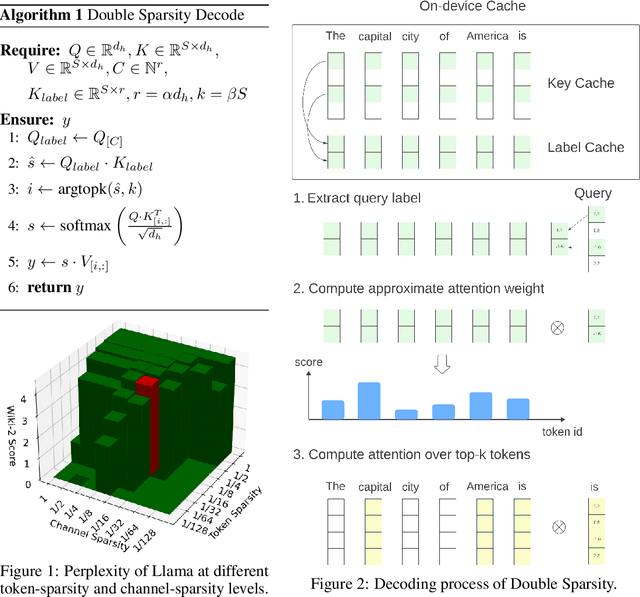

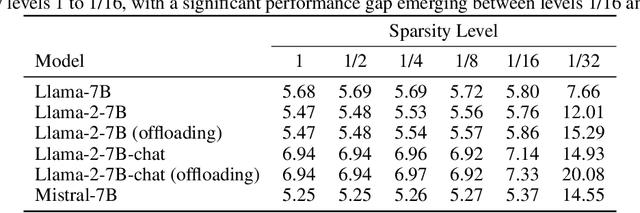
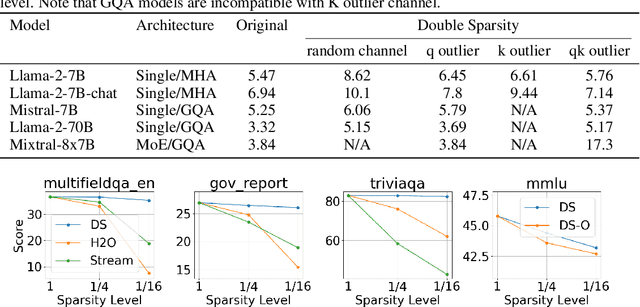
The inference process for large language models is slow and memory-intensive, with one of the most critical bottlenecks being excessive Key-Value (KV) cache accesses. This paper introduces "Double Sparsity," a novel post-training sparse attention technique designed to alleviate this bottleneck by reducing KV cache access. Double Sparsity combines token sparsity, which focuses on utilizing only the important tokens for computing self-attention, with channel sparsity, an approach that uses important feature channels for identifying important tokens. Our key insight is that the pattern of channel sparsity is relatively static, allowing us to use offline calibration to make it efficient at runtime, thereby enabling accurate and efficient identification of important tokens. Moreover, this method can be combined with offloading to achieve significant memory usage reduction. Experimental results demonstrate that Double Sparsity can achieve \(\frac{1}{16}\) token and channel sparsity with minimal impact on accuracy across various tasks, including wiki-2 perplexity, key-value retrieval, and long context benchmarks with models including Llama-2-7B, Llama-2-70B, and Mixtral-8x7B. It brings up to a 14.1$\times$ acceleration in attention operations and a 1.9$\times$ improvement in end-to-end inference on GPUs. With offloading, it achieves a decoding speed acceleration of 16.3$\times$ compared to state-of-the-art solutions at a sequence length of 256K. Our code is publicly available at \url{https://github.com/andy-yang-1/DoubleSparse}.