 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuarl: A Learning-Based Quantum Circuit Optimizer
Jul 17, 2023



Optimizing quantum circuits is challenging due to the very large search space of functionally equivalent circuits and the necessity of applying transformations that temporarily decrease performance to achieve a final performance improvement. This paper presents Quarl, a learning-based quantum circuit optimizer. Applying reinforcement learning (RL) to quantum circuit optimization raises two main challenges: the large and varying action space and the non-uniform state representation. Quarl addresses these issues with a novel neural architecture and RL-training procedure. Our neural architecture decomposes the action space into two parts and leverages graph neural networks in its state representation, both of which are guided by the intuition that optimization decisions can be mostly guided by local reasoning while allowing global circuit-wide reasoning. Our evaluation shows that Quarl significantly outperforms existing circuit optimizers on almost all benchmark circuits. Surprisingly, Quarl can learn to perform rotation merging, a complex, non-local circuit optimization implemented as a separate pass in existing optimizers.
Redundancy-Free Computation Graphs for Graph Neural Networks
Jun 09, 2019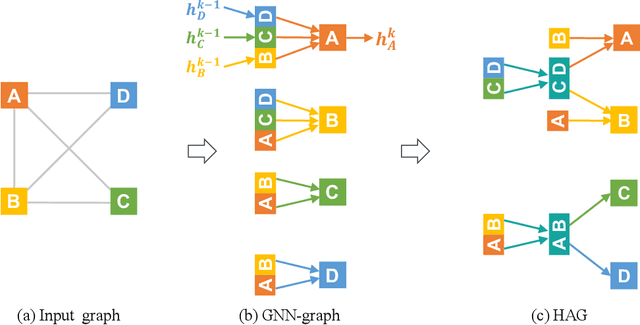

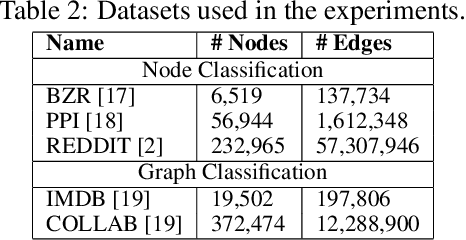

Graph Neural Networks (GNNs) are based on repeated aggregations of information across nodes' neighbors in a graph. However, because common neighbors are shared between different nodes, this leads to repeated and inefficient computations. We propose Hierarchically Aggregated computation Graphs (HAGs), a new GNN graph representation that explicitly avoids redundancy by managing intermediate aggregation results hierarchically, eliminating repeated computations and unnecessary data transfers in GNN training and inference. We introduce an accurate cost function to quantitatively evaluate the runtime performance of different HAGs and use a novel HAG search algorithm to find optimized HAGs. Experiments show that the HAG representation significantly outperforms the standard GNN graph representation by increasing the end-to-end training throughput by up to 2.8x and reducing the aggregations and data transfers in GNN training by up to 6.3x and 5.6x, while maintaining the original model accuracy.
Exploring Hidden Dimensions in Parallelizing Convolutional Neural Networks
Jun 09, 2018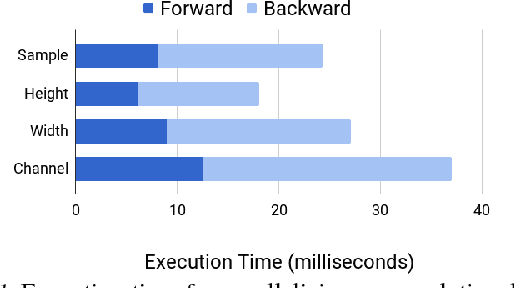
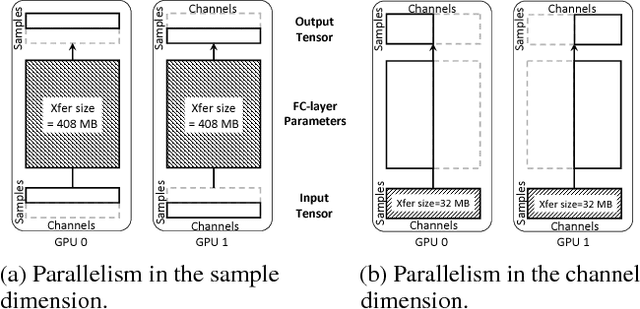
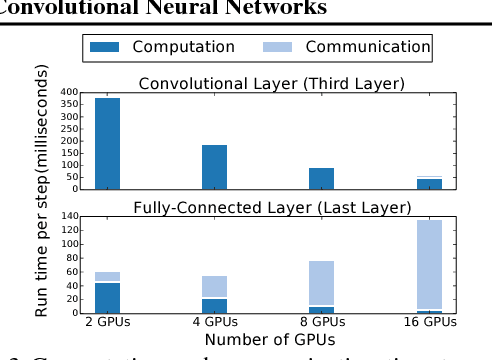

The past few years have witnessed growth in the computational requirements for training deep convolutional neural networks. Current approaches parallelize training onto multiple devices by applying a single parallelization strategy (e.g., data or model parallelism) to all layers in a network. Although easy to reason about, these approaches result in suboptimal runtime performance in large-scale distributed training, since different layers in a network may prefer different parallelization strategies. In this paper, we propose layer-wise parallelism that allows each layer in a network to use an individual parallelization strategy. We jointly optimize how each layer is parallelized by solving a graph search problem. Our evaluation shows that layer-wise parallelism outperforms state-of-the-art approaches by increasing training throughput, reducing communication costs, achieving better scalability to multiple GPUs, while maintaining original network accuracy.