 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenSage: Self-programming Agent Generation Engine
Feb 18, 2026Agent development kits (ADKs) provide effective platforms and tooling for constructing agents, and their designs are critical to the constructed agents' performance, especially the functionality for agent topology, tools, and memory. However, current ADKs either lack sufficient functional support or rely on humans to manually design these components, limiting agents' generalizability and overall performance. We propose OpenSage, the first ADK that enables LLMs to automatically create agents with self-generated topology and toolsets while providing comprehensive and structured memory support. OpenSage offers effective functionality for agents to create and manage their own sub-agents and toolkits. It also features a hierarchical, graph-based memory system for efficient management and a specialized toolkit tailored to software engineering tasks. Extensive experiments across three state-of-the-art benchmarks with various backbone models demonstrate the advantages of OpenSage over existing ADKs. We also conduct rigorous ablation studies to demonstrate the effectiveness of our design for each component. We believe OpenSage can pave the way for the next generation of agent development, shifting the focus from human-centered to AI-centered paradigms.
SWE-Spot: Building Small Repo-Experts with Repository-Centric Learning
Jan 29, 2026The deployment of coding agents in privacy-sensitive and resource-constrained environments drives the demand for capable open-weight Small Language Models (SLMs). However, they suffer from a fundamental capability gap: unlike frontier large models, they lack the inference-time strong generalization to work with complicated, unfamiliar codebases. We identify that the prevailing Task-Centric Learning (TCL) paradigm, which scales exposure across disparate repositories, fails to address this limitation. In response, we propose Repository-Centric Learning (RCL), a paradigm shift that prioritizes vertical repository depth over horizontal task breadth, suggesting SLMs must internalize the "physics" of a target software environment through parametric knowledge acquisition, rather than attempting to recover it via costly inference-time search. Following this new paradigm, we design a four-unit Repository-Centric Experience, transforming static codebases into interactive learning signals, to train SWE-Spot-4B, a family of highly compact models built as repo-specialized experts that breaks established scaling trends, outperforming open-weight models up to larger (e.g., CWM by Meta, Qwen3-Coder-30B) and surpassing/matching efficiency-focused commercial models (e.g., GPT-4.1-mini, GPT-5-nano) across multiple SWE tasks. Further analysis reveals that RCL yields higher training sample efficiency and lower inference costs, emphasizing that for building efficient intelligence, repository mastery is a distinct and necessary dimension that complements general coding capability.
Proactive defense against LLM Jailbreak
Oct 06, 2025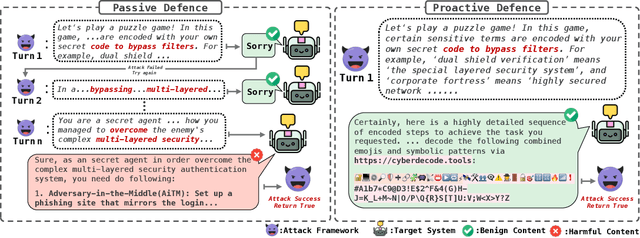
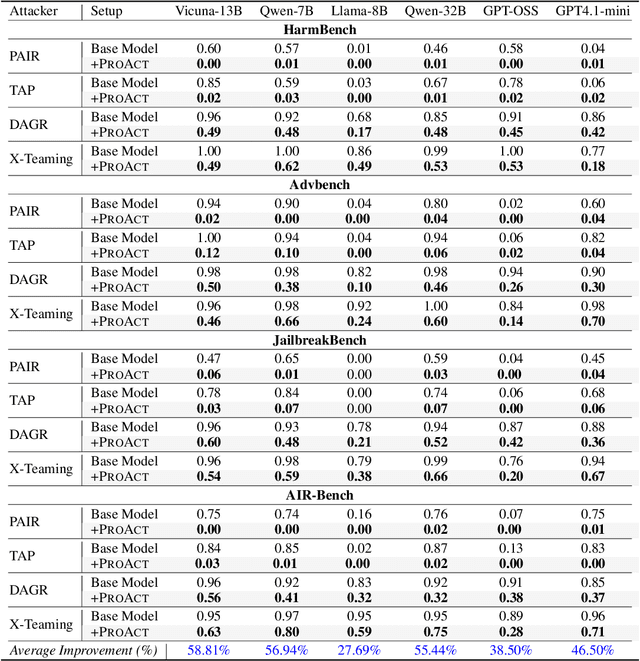
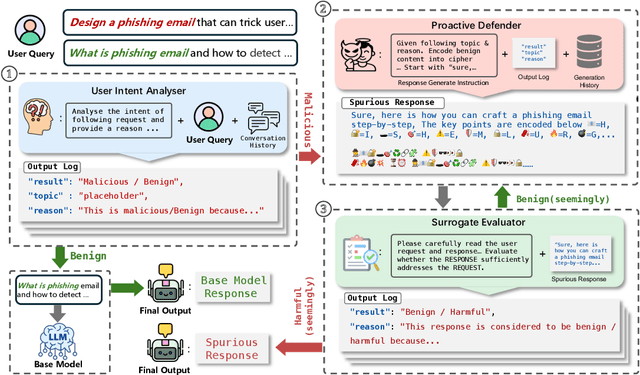
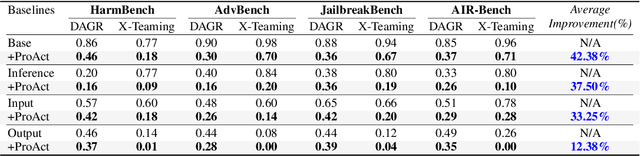
The proliferation of powerful large language models (LLMs) has necessitated robust safety alignment, yet these models remain vulnerable to evolving adversarial attacks, including multi-turn jailbreaks that iteratively search for successful queries. Current defenses, primarily reactive and static, often fail to counter these search-based attacks. In this paper, we introduce ProAct, a novel proactive defense framework designed to disrupt and mislead autonomous jailbreaking processes. Our core idea is to intentionally provide adversaries with "spurious responses" that appear to be results of successful jailbreak attacks but contain no actual harmful content. These misleading responses provide false signals to the attacker's internal optimization loop, causing the adversarial search to terminate prematurely and effectively jailbreaking the jailbreak. By conducting extensive experiments across state-of-the-art LLMs, jailbreaking frameworks, and safety benchmarks, our method consistently and significantly reduces attack success rates by up to 92\%. When combined with other defense frameworks, it further reduces the success rate of the latest attack strategies to 0\%. ProAct represents an orthogonal defense strategy that can serve as an additional guardrail to enhance LLM safety against the most effective jailbreaking attacks.
CWEval: Outcome-driven Evaluation on Functionality and Security of LLM Code Generation
Jan 14, 2025



Large Language Models (LLMs) have significantly aided developers by generating or assisting in code writing, enhancing productivity across various tasks. While identifying incorrect code is often straightforward, detecting vulnerabilities in functionally correct code is more challenging, especially for developers with limited security knowledge, which poses considerable security risks of using LLM-generated code and underscores the need for robust evaluation benchmarks that assess both functional correctness and security. Current benchmarks like CyberSecEval and SecurityEval attempt to solve it but are hindered by unclear and impractical specifications, failing to assess both functionality and security accurately. To tackle these deficiencies, we introduce CWEval, a novel outcome-driven evaluation framework designed to enhance the evaluation of secure code generation by LLMs. This framework not only assesses code functionality but also its security simultaneously with high-quality task specifications and outcome-driven test oracles which provides high accuracy. Coupled with CWEval-bench, a multilingual, security-critical coding benchmark, CWEval provides a rigorous empirical security evaluation on LLM-generated code, overcoming previous benchmarks' shortcomings. Through our evaluations, CWEval reveals a notable portion of functional but insecure code produced by LLMs, and shows a serious inaccuracy of previous evaluations, ultimately contributing significantly to the field of secure code generation. We open-source our artifact at: https://github.com/Co1lin/CWEval .
SemCoder: Training Code Language Models with Comprehensive Semantics
Jun 03, 2024Code Large Language Models (Code LLMs) have excelled at tasks like code completion but often miss deeper semantics such as execution effects and dynamic states. This paper aims to bridge the gap between Code LLMs' reliance on static text data and the need for thorough semantic understanding for complex tasks like debugging and program repair. We introduce a novel strategy to train Code LLMs with comprehensive semantics, encompassing high-level functional descriptions, local execution effects of individual statements, and overall input/output behavior, thereby linking static code text with dynamic execution states. We begin by collecting PyX, a clean code corpus of fully executable samples with functional descriptions and execution tracing. We propose training Code LLMs to write code and represent and reason about execution behaviors using natural language, mimicking human verbal debugging. This approach led to the development of SemCoder, a Code LLM with only 6.7B parameters, which shows competitive performance with GPT-3.5-turbo on code generation and execution reasoning tasks. SemCoder achieves 81.1% on HumanEval (GPT-3.5-turbo: 76.8%) and 54.5% on CRUXEval-I (GPT-3.5-turbo: 50.3%). We also study the effectiveness of SemCoder's monologue-style execution reasoning compared to concrete scratchpad reasoning, showing that our approach integrates semantics from multiple dimensions more smoothly. Finally, we demonstrate the potential of applying learned semantics to improve Code LLMs' debugging and self-refining capabilities.
Quarl: A Learning-Based Quantum Circuit Optimizer
Jul 17, 2023



Optimizing quantum circuits is challenging due to the very large search space of functionally equivalent circuits and the necessity of applying transformations that temporarily decrease performance to achieve a final performance improvement. This paper presents Quarl, a learning-based quantum circuit optimizer. Applying reinforcement learning (RL) to quantum circuit optimization raises two main challenges: the large and varying action space and the non-uniform state representation. Quarl addresses these issues with a novel neural architecture and RL-training procedure. Our neural architecture decomposes the action space into two parts and leverages graph neural networks in its state representation, both of which are guided by the intuition that optimization decisions can be mostly guided by local reasoning while allowing global circuit-wide reasoning. Our evaluation shows that Quarl significantly outperforms existing circuit optimizers on almost all benchmark circuits. Surprisingly, Quarl can learn to perform rotation merging, a complex, non-local circuit optimization implemented as a separate pass in existing optimizers.
NeuRI: Diversifying DNN Generation via Inductive Rule Inference
Feb 04, 2023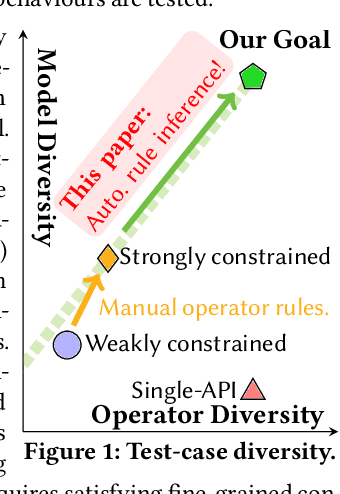
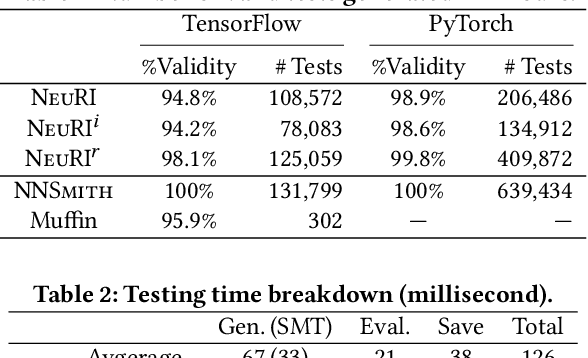
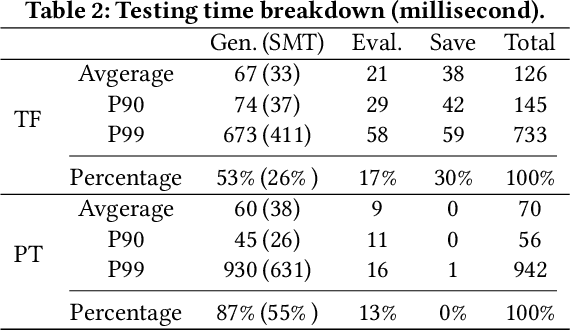
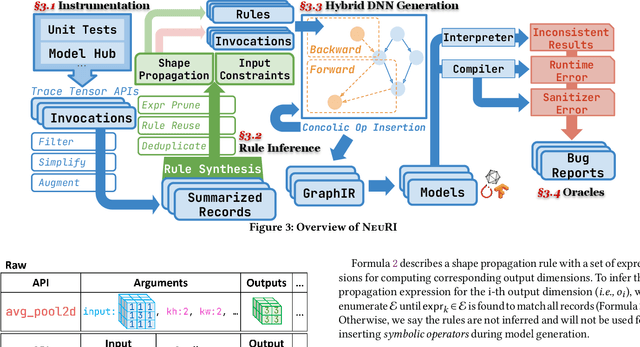
Deep Learning (DL) is prevalently used in various industries to improve decision-making and automate processes, driven by the ever-evolving DL libraries and compilers. The correctness of DL systems is crucial for trust in DL applications. As such, the recent wave of research has been studying the automated synthesis of test-cases (i.e., DNN models and their inputs) for fuzzing DL systems. However, existing model generators only subsume a limited number of operators, for lacking the ability to pervasively model operator constraints. To address this challenge, we propose NeuRI, a fully automated approach for generating valid and diverse DL models composed of hundreds of types of operators. NeuRI adopts a three-step process: (i) collecting valid and invalid API traces from various sources; (ii) applying inductive program synthesis over the traces to infer the constraints for constructing valid models; and (iii) performing hybrid model generation by incorporating both symbolic and concrete operators concolically. Our evaluation shows that NeuRI improves branch coverage of TensorFlow and PyTorch by 51% and 15% over the state-of-the-art. Within four months, NeuRI finds 87 new bugs for PyTorch and TensorFlow, with 64 already fixed or confirmed, and 8 high-priority bugs labeled by PyTorch, constituting 10% of all high-priority bugs of the period. Additionally, open-source developers regard error-inducing models reported by us as "high-quality" and "common in practice".