 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Software Engineering Agents Through the Lens of Traceability: An Empirical Study
Jun 10, 2025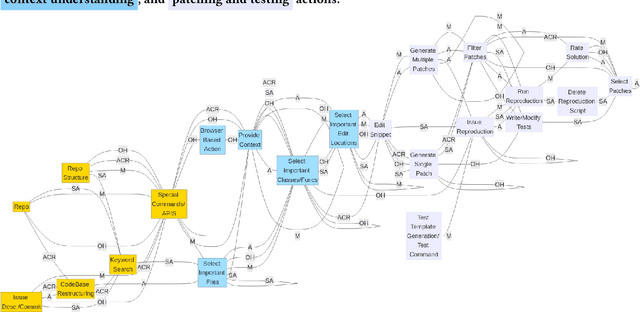
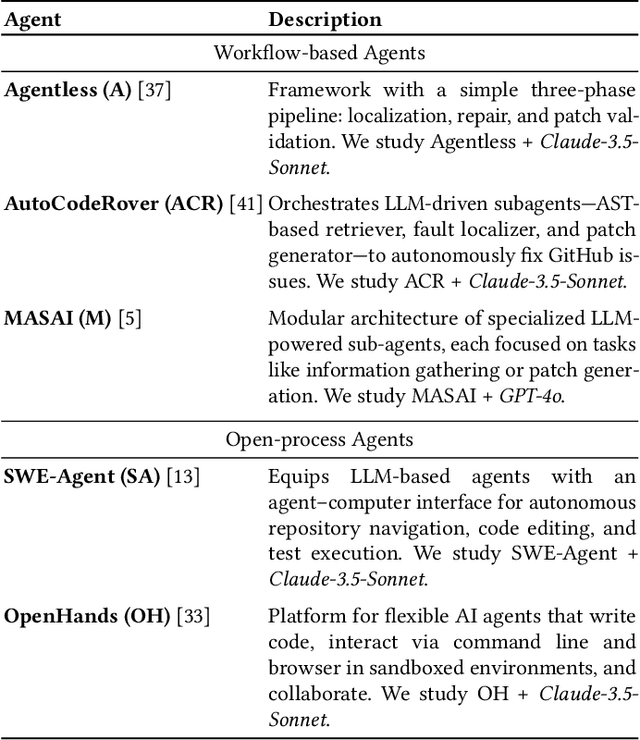
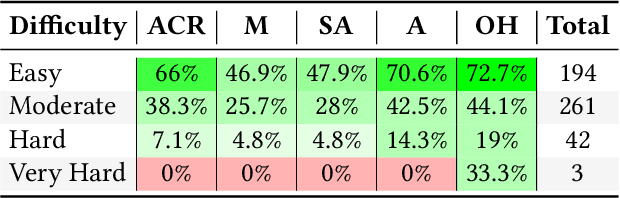
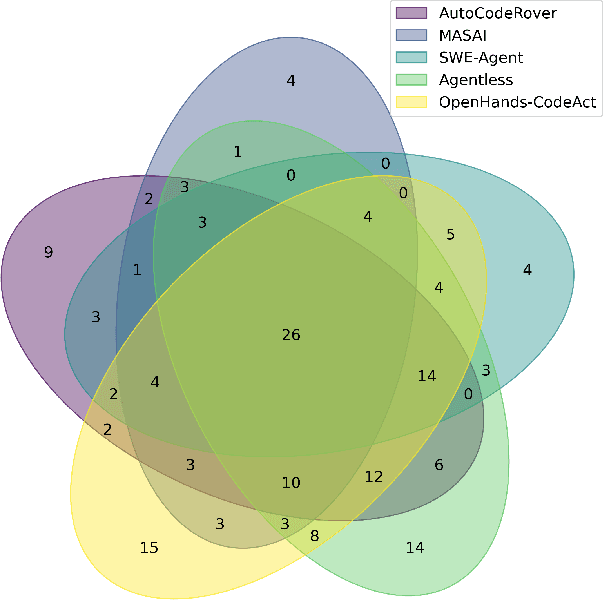
With the advent of large language models (LLMs), software engineering agents (SWE agents) have emerged as a powerful paradigm for automating a range of software tasks -- from code generation and repair to test case synthesis. These agents operate autonomously by interpreting user input and responding to environmental feedback. While various agent architectures have demonstrated strong empirical performance, the internal decision-making worfklows that drive their behavior remain poorly understood. Deeper insight into these workflows hold promise for improving both agent reliability and efficiency. In this work, we present the first systematic study of SWE agent behavior through the lens of execution traces. Our contributions are as follows: (1) we propose the first taxonomy of decision-making pathways across five representative agents; (2) using this taxonomy, we identify three core components essential to agent success -- bug localization, patch generation, and reproduction test generation -- and study each in depth; (3) we study the impact of test generation on successful patch production; and analyze strategies that can lead to successful test generation; (4) we further conduct the first large-scale code clone analysis comparing agent-generated and developer-written patches and provide a qualitative study revealing structural and stylistic differences in patch content. Together, these findings offer novel insights into agent design and open avenues for building agents that are both more effective and more aligned with human development practices.
Can LLM Prompting Serve as a Proxy for Static Analysis in Vulnerability Detection
Dec 16, 2024Despite their remarkable success, large language models (LLMs) have shown limited ability on applied tasks such as vulnerability detection. We investigate various prompting strategies for vulnerability detection and, as part of this exploration, propose a prompting strategy that integrates natural language descriptions of vulnerabilities with a contrastive chain-of-thought reasoning approach, augmented using contrastive samples from a synthetic dataset. Our study highlights the potential of LLMs to detect vulnerabilities by integrating natural language descriptions, contrastive reasoning, and synthetic examples into a comprehensive prompting framework. Our results show that this approach can enhance LLM understanding of vulnerabilities. On a high-quality vulnerability detection dataset such as SVEN, our prompting strategies can improve accuracies, F1-scores, and pairwise accuracies by 23%, 11%, and 14%, respectively.
SemCoder: Training Code Language Models with Comprehensive Semantics
Jun 03, 2024Code Large Language Models (Code LLMs) have excelled at tasks like code completion but often miss deeper semantics such as execution effects and dynamic states. This paper aims to bridge the gap between Code LLMs' reliance on static text data and the need for thorough semantic understanding for complex tasks like debugging and program repair. We introduce a novel strategy to train Code LLMs with comprehensive semantics, encompassing high-level functional descriptions, local execution effects of individual statements, and overall input/output behavior, thereby linking static code text with dynamic execution states. We begin by collecting PyX, a clean code corpus of fully executable samples with functional descriptions and execution tracing. We propose training Code LLMs to write code and represent and reason about execution behaviors using natural language, mimicking human verbal debugging. This approach led to the development of SemCoder, a Code LLM with only 6.7B parameters, which shows competitive performance with GPT-3.5-turbo on code generation and execution reasoning tasks. SemCoder achieves 81.1% on HumanEval (GPT-3.5-turbo: 76.8%) and 54.5% on CRUXEval-I (GPT-3.5-turbo: 50.3%). We also study the effectiveness of SemCoder's monologue-style execution reasoning compared to concrete scratchpad reasoning, showing that our approach integrates semantics from multiple dimensions more smoothly. Finally, we demonstrate the potential of applying learned semantics to improve Code LLMs' debugging and self-refining capabilities.
CYCLE: Learning to Self-Refine the Code Generation
Mar 27, 2024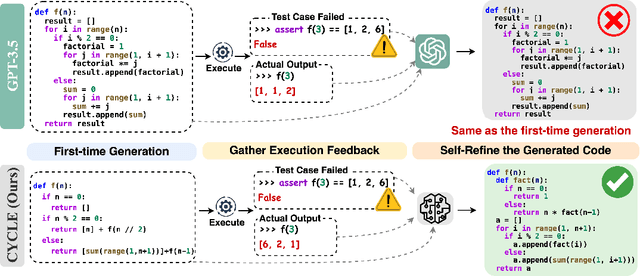
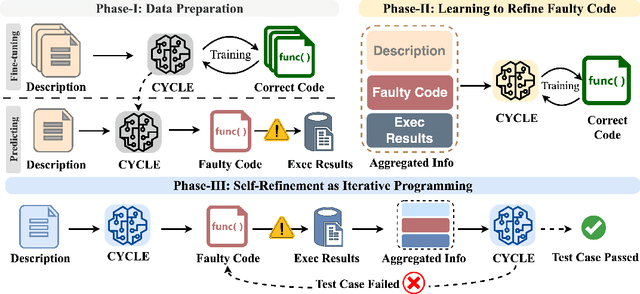
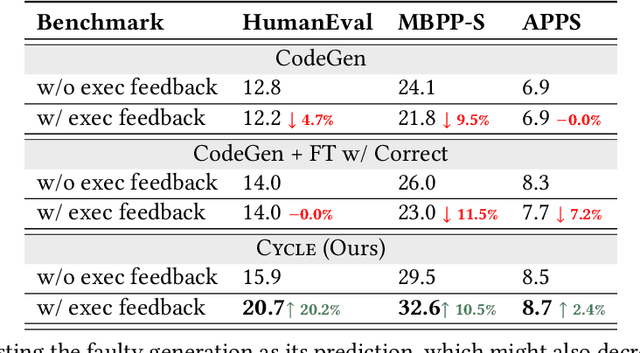

Pre-trained code language models have achieved promising performance in code generation and improved the programming efficiency of human developers. However, their self-refinement capability is typically overlooked by the existing evaluations of code LMs, which focus only on the accuracy of the one-time prediction. For the cases when code LMs fail to implement the correct program, developers actually find it hard to debug and fix the faulty prediction since it is not written by the developers themselves. Unfortunately, our study reveals that code LMs cannot efficiently self-refine their faulty generations as well. In this paper, we propose CYCLE framework, learning to self-refine the faulty generation according to the available feedback, such as the execution results reported by the test suites. We evaluate CYCLE on three popular code generation benchmarks, HumanEval, MBPP, and APPS. The results reveal that CYCLE successfully maintains, sometimes improves, the quality of one-time code generation, while significantly improving the self-refinement capability of code LMs. We implement four variants of CYCLE with varied numbers of parameters across 350M, 1B, 2B, and 3B, and the experiments show that CYCLE consistently boosts the code generation performance, by up to 63.5%, across benchmarks and varied model sizes. We also notice that CYCLE outperforms code LMs that have 3$\times$ more parameters in self-refinement.
Vignat: Vulnerability identification by learning code semantics via graph attention networks
Oct 30, 2023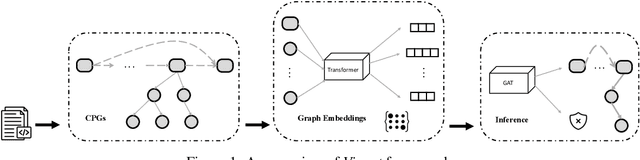
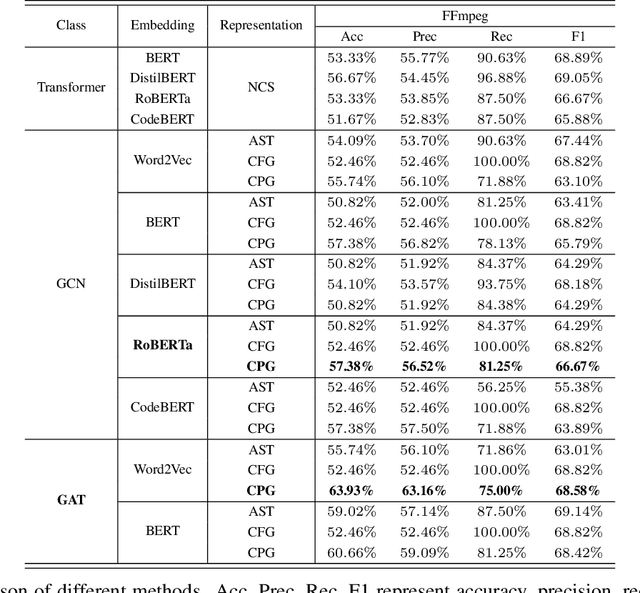
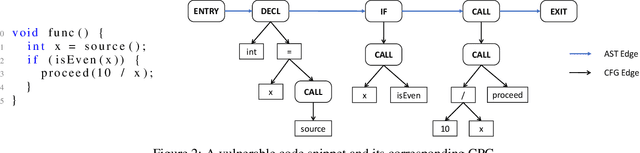
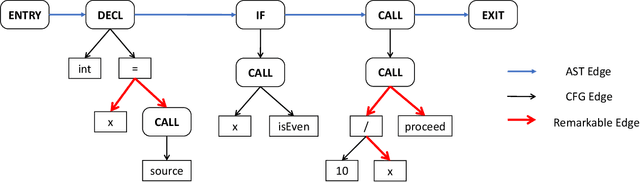
Vulnerability identification is crucial to protect software systems from attacks for cyber-security. However, huge projects have more than millions of lines of code, and the complex dependencies make it hard to carry out traditional static and dynamic methods. Furthermore, the semantic structure of various types of vulnerabilities differs greatly and may occur simultaneously, making general rule-based methods difficult to extend. In this paper, we propose \textit{Vignat}, a novel attention-based framework for identifying vulnerabilities by learning graph-level semantic representations of code. We represent codes with code property graphs (CPGs) in fine grain and use graph attention networks (GATs) for vulnerability detection. The results show that Vignat is able to achieve $57.38\%$ accuracy on reliable datasets derived from popular C libraries. Furthermore, the interpretability of our GATs provides valuable insights into vulnerability patterns.
Beyond Accuracy: Evaluating Self-Consistency of Code Large Language Models with IdentityChain
Oct 21, 2023



Code Large Language Models (Code LLMs) are being increasingly employed in real-life applications, so evaluating them is critical. While the general accuracy of Code LLMs on individual tasks has been extensively evaluated, their self-consistency across different tasks is overlooked. Intuitively, a trustworthy model should be self-consistent when generating natural language specifications for its own code and generating code for its own specifications. Failure to preserve self-consistency reveals a lack of understanding of the shared semantics underlying natural language and programming language, and therefore undermines the trustworthiness of a model. In this paper, we first formally define the self-consistency of Code LLMs and then design a framework, IdentityChain, which effectively and efficiently evaluates the self-consistency and general accuracy of a model at the same time. We study eleven Code LLMs and show that they fail to preserve self-consistency, which is indeed a distinct aspect from general accuracy. Furthermore, we show that IdentityChain can be used as a model debugging tool to expose weaknesses of Code LLMs by demonstrating three major weaknesses that we identify in current models using IdentityChain. Our code is available at https://github.com/marcusm117/IdentityChain.
On Contrastive Learning of Semantic Similarity forCode to Code Search
May 05, 2023



This paper introduces a novel code-to-code search technique that enhances the performance of Large Language Models (LLMs) by including both static and dynamic features as well as utilizing both similar and dissimilar examples during training. We present the first-ever code search method that encodes dynamic runtime information during training without the need to execute either the corpus under search or the search query at inference time and the first code search technique that trains on both positive and negative reference samples. To validate the efficacy of our approach, we perform a set of studies demonstrating the capability of enhanced LLMs to perform cross-language code-to-code search. Our evaluation demonstrates that the effectiveness of our approach is consistent across various model architectures and programming languages. We outperform the state-of-the-art cross-language search tool by up to 44.7\%. Moreover, our ablation studies reveal that even a single positive and negative reference sample in the training process results in substantial performance improvements demonstrating both similar and dissimilar references are important parts of code search. Importantly, we show that enhanced well-crafted, fine-tuned models consistently outperform enhanced larger modern LLMs without fine tuning, even when enhancing the largest available LLMs highlighting the importance for open-sourced models. To ensure the reproducibility and extensibility of our research, we present an open-sourced implementation of our tool and training procedures called Cosco.
VELVET: a noVel Ensemble Learning approach to automatically locate VulnErable sTatements
Jan 13, 2022
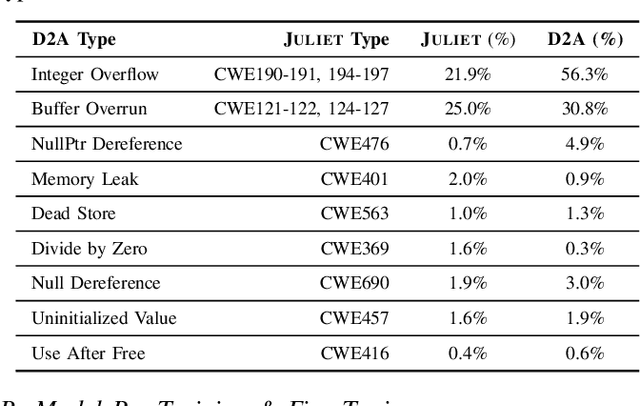
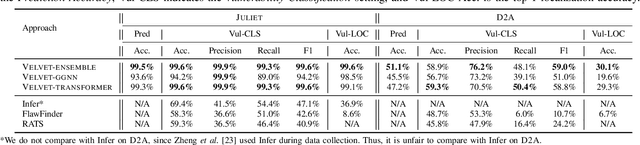
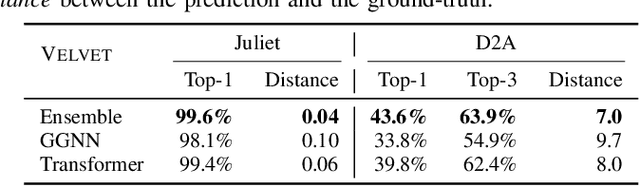
Automatically locating vulnerable statements in source code is crucial to assure software security and alleviate developers' debugging efforts. This becomes even more important in today's software ecosystem, where vulnerable code can flow easily and unwittingly within and across software repositories like GitHub. Across such millions of lines of code, traditional static and dynamic approaches struggle to scale. Although existing machine-learning-based approaches look promising in such a setting, most work detects vulnerable code at a higher granularity -- at the method or file level. Thus, developers still need to inspect a significant amount of code to locate the vulnerable statement(s) that need to be fixed. This paper presents VELVET, a novel ensemble learning approach to locate vulnerable statements. Our model combines graph-based and sequence-based neural networks to successfully capture the local and global context of a program graph and effectively understand code semantics and vulnerable patterns. To study VELVET's effectiveness, we use an off-the-shelf synthetic dataset and a recently published real-world dataset. In the static analysis setting, where vulnerable functions are not detected in advance, VELVET achieves 4.5x better performance than the baseline static analyzers on the real-world data. For the isolated vulnerability localization task, where we assume the vulnerability of a function is known while the specific vulnerable statement is unknown, we compare VELVET with several neural networks that also attend to local and global context of code. VELVET achieves 99.6% and 43.6% top-1 accuracy over synthetic data and real-world data, respectively, outperforming the baseline deep-learning models by 5.3-29.0%.
Neural Network Guided Evolutionary Fuzzing for Finding Traffic Violations of Autonomous Vehicles
Sep 13, 2021



Self-driving cars and trucks, autonomous vehicles (AVs), should not be accepted by regulatory bodies and the public until they have much higher confidence in their safety and reliability -- which can most practically and convincingly be achieved by testing. But existing testing methods are inadequate for checking the end-to-end behaviors of AV controllers against complex, real-world corner cases involving interactions with multiple independent agents such as pedestrians and human-driven vehicles. While test-driving AVs on streets and highways fails to capture many rare events, existing simulation-based testing methods mainly focus on simple scenarios and do not scale well for complex driving situations that require sophisticated awareness of the surroundings. To address these limitations, we propose a new fuzz testing technique, called AutoFuzz, which can leverage widely-used AV simulators' API grammars. to generate semantically and temporally valid complex driving scenarios (sequences of scenes). AutoFuzz is guided by a constrained Neural Network (NN) evolutionary search over the API grammar to generate scenarios seeking to find unique traffic violations. Evaluation of our prototype on one state-of-the-art learning-based controller and two rule-based controllers shows that AutoFuzz efficiently finds hundreds of realistic traffic violations resembling real-world crashes. Further, fine-tuning the learning-based controller with the traffic violations found by AutoFuzz successfully reduced the traffic violations found in the new version of the AV controller software.