 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Classification: Leveraging Self-Supervised Classification to Enhance Prediction Performance
Feb 26, 2025In this paper, we propose an innovative dynamic classification algorithm designed to achieve the objective of zero missed detections and minimal false positives. The algorithm partitions the data into N equivalent training subsets and N prediction subsets using a supervised model, followed by independent predictions from N separate predictive models. This enables each predictive model to operate within a smaller data range, thereby improving overall accuracy. Additionally, the algorithm leverages data generated through supervised learning to further refine prediction results, filtering out predictions that do not meet accuracy requirements without the need to introduce additional models. Experimental results demonstrate that, when data partitioning errors are minimal, the dynamic classification algorithm achieves exceptional performance with zero missed detections and minimal false positives, significantly outperforming existing model ensembles. Even in cases where classification errors are larger, the algorithm remains comparable to state of the art models. The key innovations of this study include self-supervised classification learning, the use of small-range subset predictions, and the direct rejection of substandard predictions. While the current algorithm still has room for improvement in terms of automatic parameter tuning and classification model efficiency, it has demonstrated outstanding performance across multiple datasets. Future research will focus on optimizing the classification component to further enhance the algorithm's robustness and adaptability.
Language-Guided Traffic Simulation via Scene-Level Diffusion
Jun 10, 2023Realistic and controllable traffic simulation is a core capability that is necessary to accelerate autonomous vehicle (AV) development. However, current approaches for controlling learning-based traffic models require significant domain expertise and are difficult for practitioners to use. To remedy this, we present CTG++, a scene-level conditional diffusion model that can be guided by language instructions. Developing this requires tackling two challenges: the need for a realistic and controllable traffic model backbone, and an effective method to interface with a traffic model using language. To address these challenges, we first propose a scene-level diffusion model equipped with a spatio-temporal transformer backbone, which generates realistic and controllable traffic. We then harness a large language model (LLM) to convert a user's query into a loss function, guiding the diffusion model towards query-compliant generation. Through comprehensive evaluation, we demonstrate the effectiveness of our proposed method in generating realistic, query-compliant traffic simulations.
Guided Conditional Diffusion for Controllable Traffic Simulation
Oct 31, 2022Controllable and realistic traffic simulation is critical for developing and verifying autonomous vehicles. Typical heuristic-based traffic models offer flexible control to make vehicles follow specific trajectories and traffic rules. On the other hand, data-driven approaches generate realistic and human-like behaviors, improving transfer from simulated to real-world traffic. However, to the best of our knowledge, no traffic model offers both controllability and realism. In this work, we develop a conditional diffusion model for controllable traffic generation (CTG) that allows users to control desired properties of trajectories at test time (e.g., reach a goal or follow a speed limit) while maintaining realism and physical feasibility through enforced dynamics. The key technical idea is to leverage recent advances from diffusion modeling and differentiable logic to guide generated trajectories to meet rules defined using signal temporal logic (STL). We further extend guidance to multi-agent settings and enable interaction-based rules like collision avoidance. CTG is extensively evaluated on the nuScenes dataset for diverse and composite rules, demonstrating improvement over strong baselines in terms of the controllability-realism tradeoff.
Repairing Group-Level Errors for DNNs Using Weighted Regularization
Apr 04, 2022
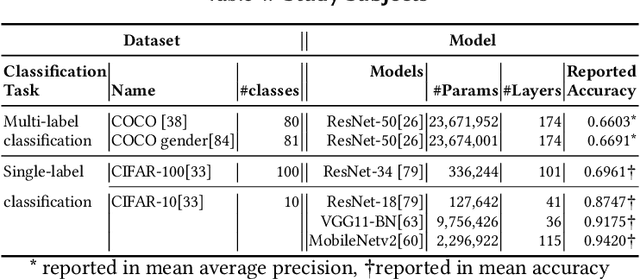
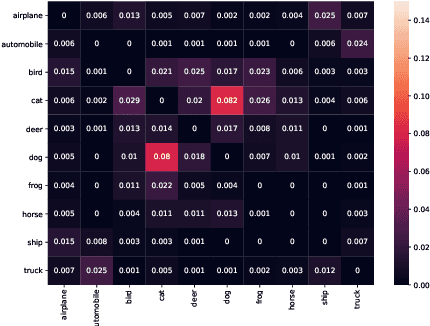
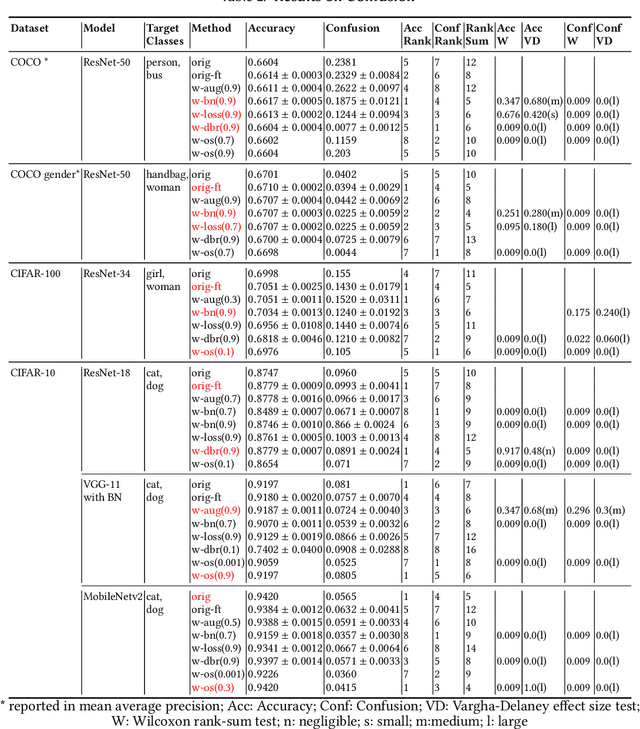
Deep Neural Networks (DNNs) have been widely used in software making decisions impacting people's lives. However, they have been found to exhibit severe erroneous behaviors that may lead to unfortunate outcomes. Previous work shows that such misbehaviors often occur due to class property violations rather than errors on a single image. Although methods for detecting such errors have been proposed, fixing them has not been studied so far. Here, we propose a generic method called Weighted Regularization (WR) consisting of five concrete methods targeting the error-producing classes to fix the DNNs. In particular, it can repair confusion error and bias error of DNN models for both single-label and multi-label image classifications. A confusion error happens when a given DNN model tends to confuse between two classes. Each method in WR assigns more weights at a stage of DNN retraining or inference to mitigate the confusion between target pair. A bias error can be fixed similarly. We evaluate and compare the proposed methods along with baselines on six widely-used datasets and architecture combinations. The results suggest that WR methods have different trade-offs but under each setting at least one WR method can greatly reduce confusion/bias errors at a very limited cost of the overall performance.
A Survey on Scenario-Based Testing for Automated Driving Systems in High-Fidelity Simulation
Dec 02, 2021
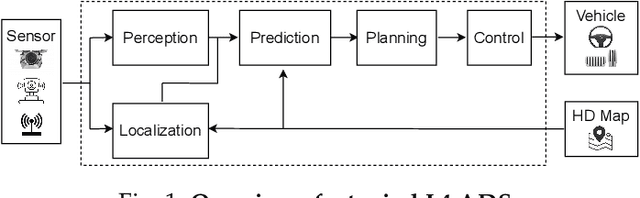

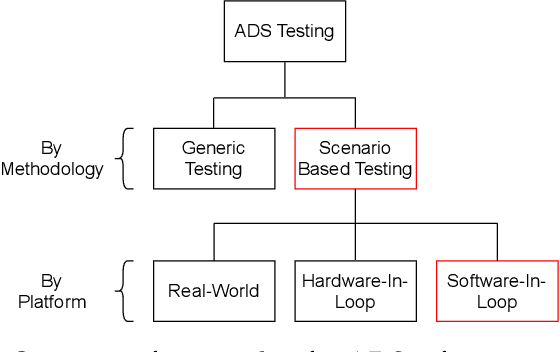
Automated Driving Systems (ADSs) have seen rapid progress in recent years. To ensure the safety and reliability of these systems, extensive testings are being conducted before their future mass deployment. Testing the system on the road is the closest to real-world and desirable approach, but it is incredibly costly. Also, it is infeasible to cover rare corner cases using such real-world testing. Thus, a popular alternative is to evaluate an ADS's performance in some well-designed challenging scenarios, a.k.a. scenario-based testing. High-fidelity simulators have been widely used in this setting to maximize flexibility and convenience in testing what-if scenarios. Although many works have been proposed offering diverse frameworks/methods for testing specific systems, the comparisons and connections among these works are still missing. To bridge this gap, in this work, we provide a generic formulation of scenario-based testing in high-fidelity simulation and conduct a literature review on the existing works. We further compare them and present the open challenges as well as potential future research directions.
Detecting Safety Problems of Multi-Sensor Fusion in Autonomous Driving
Sep 14, 2021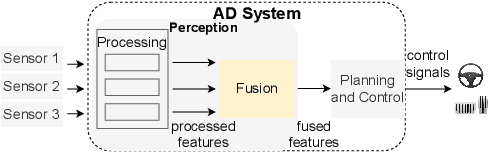

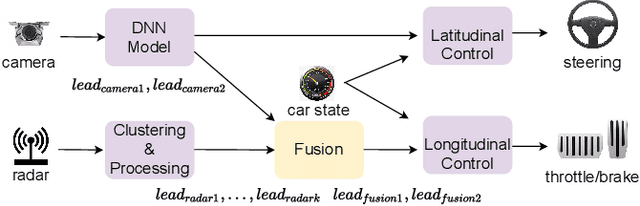

Autonomous driving (AD) systems have been thriving in recent years. In general, they receive sensor data, compute driving decisions, and output control signals to the vehicles. To smooth out the uncertainties brought by sensor inputs, AD systems usually leverage multi-sensor fusion (MSF) to fuse the sensor inputs and produce a more reliable understanding of the surroundings. However, MSF cannot completely eliminate the uncertainties since it lacks the knowledge about which sensor provides the most accurate data. As a result, critical consequences might happen unexpectedly. In this work, we observed that the popular MSF methods in an industry-grade Advanced Driver-Assistance System (ADAS) can mislead the car control and result in serious safety hazards. Misbehavior can happen regardless of the used fusion methods and the accurate data from at least one sensor. To attribute the safety hazards to a MSF method, we formally define the fusion errors and propose a way to distinguish safety violations causally induced by such errors. Further, we develop a novel evolutionary-based domain-specific search framework, FusionFuzz, for the efficient detection of fusion errors. We evaluate our framework on two widely used MSF methods. %in two driving environments. Experimental results show that FusionFuzz identifies more than 150 fusion errors. Finally, we provide several suggestions to improve the MSF methods under study.
Neural Network Guided Evolutionary Fuzzing for Finding Traffic Violations of Autonomous Vehicles
Sep 13, 2021



Self-driving cars and trucks, autonomous vehicles (AVs), should not be accepted by regulatory bodies and the public until they have much higher confidence in their safety and reliability -- which can most practically and convincingly be achieved by testing. But existing testing methods are inadequate for checking the end-to-end behaviors of AV controllers against complex, real-world corner cases involving interactions with multiple independent agents such as pedestrians and human-driven vehicles. While test-driving AVs on streets and highways fails to capture many rare events, existing simulation-based testing methods mainly focus on simple scenarios and do not scale well for complex driving situations that require sophisticated awareness of the surroundings. To address these limitations, we propose a new fuzz testing technique, called AutoFuzz, which can leverage widely-used AV simulators' API grammars. to generate semantically and temporally valid complex driving scenarios (sequences of scenes). AutoFuzz is guided by a constrained Neural Network (NN) evolutionary search over the API grammar to generate scenarios seeking to find unique traffic violations. Evaluation of our prototype on one state-of-the-art learning-based controller and two rule-based controllers shows that AutoFuzz efficiently finds hundreds of realistic traffic violations resembling real-world crashes. Further, fine-tuning the learning-based controller with the traffic violations found by AutoFuzz successfully reduced the traffic violations found in the new version of the AV controller software.
Understanding Spatial Robustness of Deep Neural Networks
Oct 09, 2020
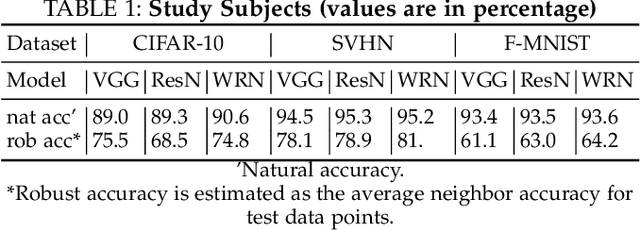
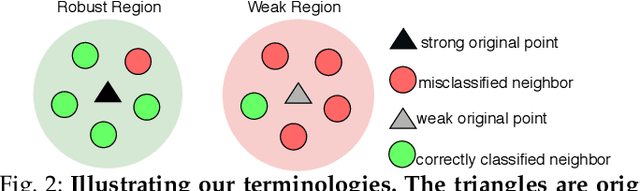
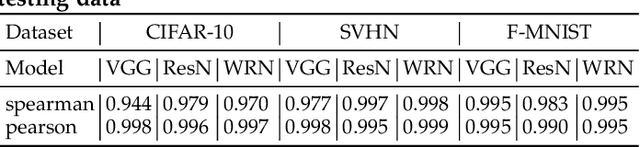
Deep Neural Networks (DNNs) are being deployed in a wide range of settings today, from safety-critical applications like autonomous driving to commercial applications involving image classifications. However, recent research has shown that DNNs can be brittle to even slight variations of the input data. Therefore, rigorous testing of DNNs has gained widespread attention. While DNN robustness under norm-bound perturbation got significant attention over the past few years, our knowledge is still limited when natural variants of the input images come. These natural variants, e.g. a rotated or a rainy version of the original input, are especially concerning as they can occur naturally in the field without any active adversary and may lead to undesirable consequences. Thus, it is important to identify the inputs whose small variations may lead to erroneous DNN behaviors. The very few studies that looked at DNN's robustness under natural variants, however, focus on estimating the overall robustness of DNNs across all the test data rather than localizing such error-producing points. This work aims to bridge this gap. To this end, we study the local per-input robustness properties of the DNNs and leverage those properties to build a white-box (DEEPROBUST-W) and a black-box (DEEPROBUST-B) tool to automatically identify the non-robust points. Our evaluation of these methods on nine DNN models spanning three widely used image classification datasets shows that they are effective in flagging points of poor robustness. In particular, DEEPROBUST-W and DEEPROBUST-B are able to achieve an F1 score of up to 91.4% and 99.1%, respectively. We further show that DEEPROBUST-W can be applied to a regression problem for a self-driving car application.
Metric Learning for Adversarial Robustness
Sep 03, 2019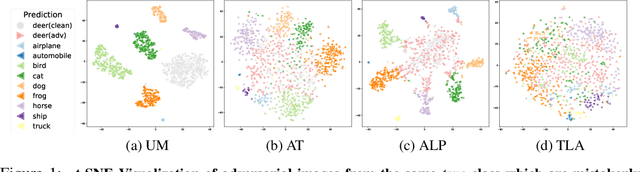
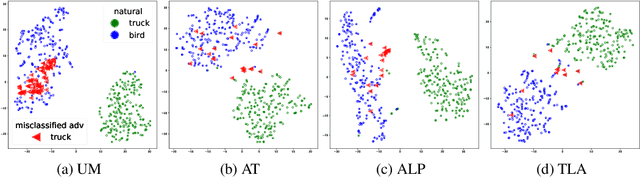
Deep networks are well-known to be fragile to adversarial attacks. Using several standard image datasets and established attack mechanisms, we conduct an empirical analysis of deep representations under attack, and find that the attack causes the internal representation to shift closer to the "false" class. Motivated by this observation, we propose to regularize the representation space under attack with metric learning in order to produce more robust classifiers. By carefully sampling examples for metric learning, our learned representation not only increases robustness, but also can detect previously unseen adversarial samples. Quantitative experiments show improvement of robustness accuracy by up to 4\% and detection efficiency by up to 6\% according to Area Under Curve (AUC) score over baselines.
Testing Deep Neural Network based Image Classifiers
May 20, 2019
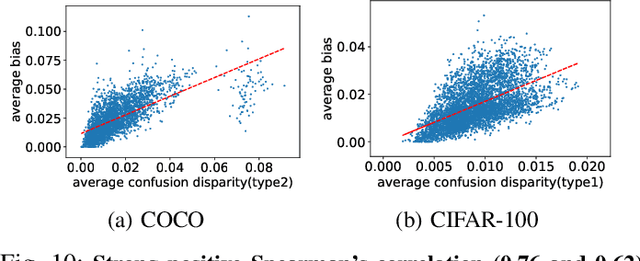
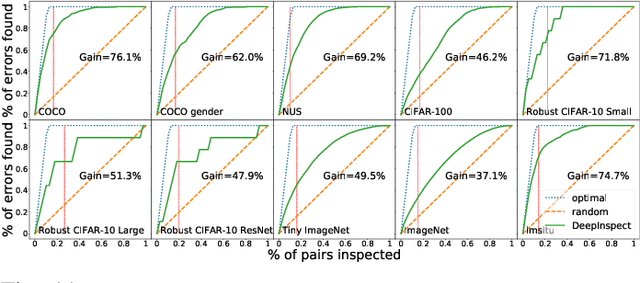

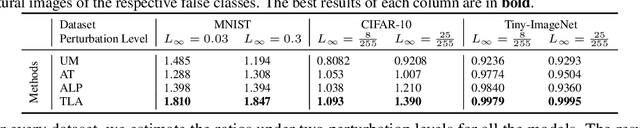
Image classification is an important task in today's world with many applications from socio-technical to safety-critical domains. The recent advent of Deep Neural Network (DNN) is the key behind such a wide-spread success. However, such wide adoption comes with the concerns about the reliability of these systems, as several erroneous behaviors have already been reported in many sensitive and critical circumstances. Thus, it has become crucial to rigorously test the image classifiers to ensure high reliability. Many reported erroneous cases in popular neural image classifiers appear because the models often confuse one class with another, or show biases towards some classes over others. These errors usually violate some group properties. Most existing DNN testing and verification techniques focus on per image violations and thus fail to detect such group-level confusions or biases. In this paper, we design, implement and evaluate DeepInspect, a white box testing tool, for automatically detecting confusion and bias of DNN-driven image classification applications. We evaluate DeepInspect using popular DNN-based image classifiers and detect hundreds of classification mistakes. Some of these cases are able to expose potential biases of the network towards certain populations. DeepInspect further reports many classification errors in state-of-the-art robust models.