 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMetric Learning for Adversarial Robustness
Paper and Code
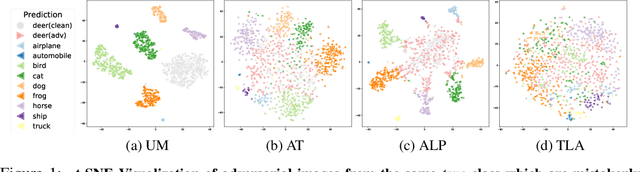
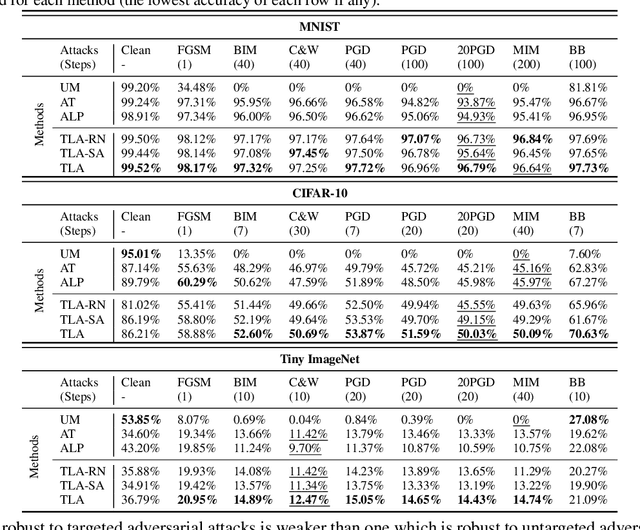
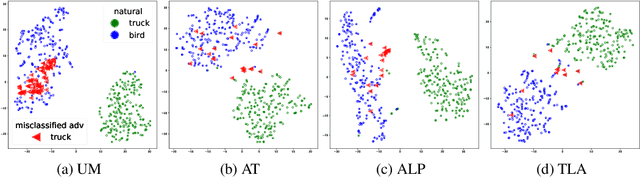
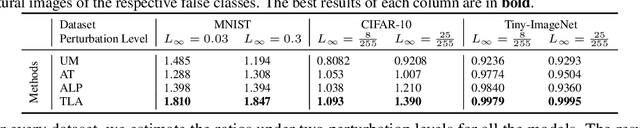
Deep networks are well-known to be fragile to adversarial attacks. Using several standard image datasets and established attack mechanisms, we conduct an empirical analysis of deep representations under attack, and find that the attack causes the internal representation to shift closer to the "false" class. Motivated by this observation, we propose to regularize the representation space under attack with metric learning in order to produce more robust classifiers. By carefully sampling examples for metric learning, our learned representation not only increases robustness, but also can detect previously unseen adversarial samples. Quantitative experiments show improvement of robustness accuracy by up to 4\% and detection efficiency by up to 6\% according to Area Under Curve (AUC) score over baselines.