 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRepairing Group-Level Errors for DNNs Using Weighted Regularization
Apr 04, 2022
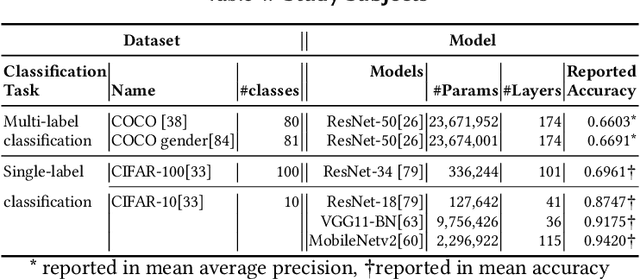
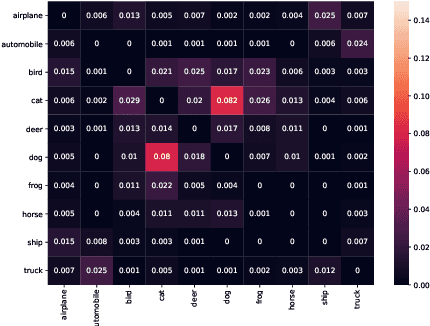
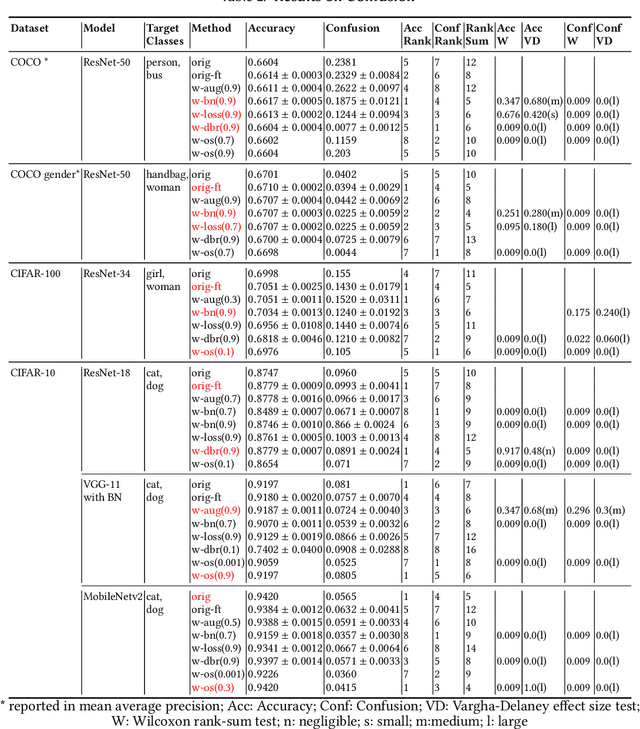
Deep Neural Networks (DNNs) have been widely used in software making decisions impacting people's lives. However, they have been found to exhibit severe erroneous behaviors that may lead to unfortunate outcomes. Previous work shows that such misbehaviors often occur due to class property violations rather than errors on a single image. Although methods for detecting such errors have been proposed, fixing them has not been studied so far. Here, we propose a generic method called Weighted Regularization (WR) consisting of five concrete methods targeting the error-producing classes to fix the DNNs. In particular, it can repair confusion error and bias error of DNN models for both single-label and multi-label image classifications. A confusion error happens when a given DNN model tends to confuse between two classes. Each method in WR assigns more weights at a stage of DNN retraining or inference to mitigate the confusion between target pair. A bias error can be fixed similarly. We evaluate and compare the proposed methods along with baselines on six widely-used datasets and architecture combinations. The results suggest that WR methods have different trade-offs but under each setting at least one WR method can greatly reduce confusion/bias errors at a very limited cost of the overall performance.
Understanding Spatial Robustness of Deep Neural Networks
Oct 09, 2020
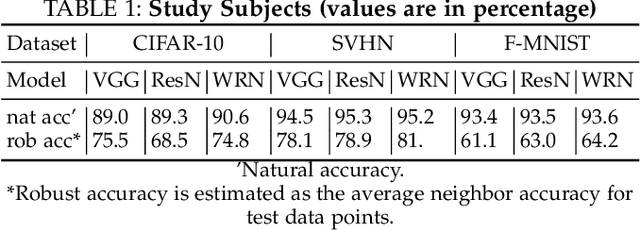
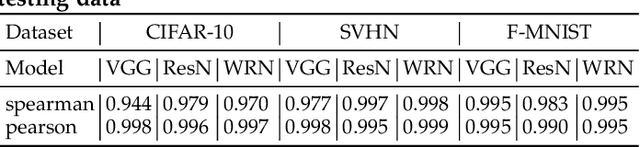
Deep Neural Networks (DNNs) are being deployed in a wide range of settings today, from safety-critical applications like autonomous driving to commercial applications involving image classifications. However, recent research has shown that DNNs can be brittle to even slight variations of the input data. Therefore, rigorous testing of DNNs has gained widespread attention. While DNN robustness under norm-bound perturbation got significant attention over the past few years, our knowledge is still limited when natural variants of the input images come. These natural variants, e.g. a rotated or a rainy version of the original input, are especially concerning as they can occur naturally in the field without any active adversary and may lead to undesirable consequences. Thus, it is important to identify the inputs whose small variations may lead to erroneous DNN behaviors. The very few studies that looked at DNN's robustness under natural variants, however, focus on estimating the overall robustness of DNNs across all the test data rather than localizing such error-producing points. This work aims to bridge this gap. To this end, we study the local per-input robustness properties of the DNNs and leverage those properties to build a white-box (DEEPROBUST-W) and a black-box (DEEPROBUST-B) tool to automatically identify the non-robust points. Our evaluation of these methods on nine DNN models spanning three widely used image classification datasets shows that they are effective in flagging points of poor robustness. In particular, DEEPROBUST-W and DEEPROBUST-B are able to achieve an F1 score of up to 91.4% and 99.1%, respectively. We further show that DEEPROBUST-W can be applied to a regression problem for a self-driving car application.
Testing Deep Neural Network based Image Classifiers
May 20, 2019
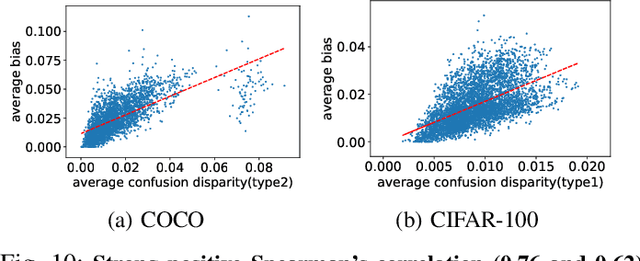
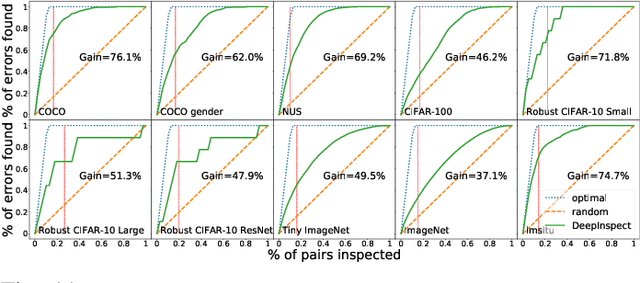

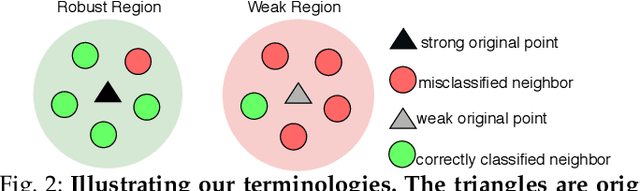
Image classification is an important task in today's world with many applications from socio-technical to safety-critical domains. The recent advent of Deep Neural Network (DNN) is the key behind such a wide-spread success. However, such wide adoption comes with the concerns about the reliability of these systems, as several erroneous behaviors have already been reported in many sensitive and critical circumstances. Thus, it has become crucial to rigorously test the image classifiers to ensure high reliability. Many reported erroneous cases in popular neural image classifiers appear because the models often confuse one class with another, or show biases towards some classes over others. These errors usually violate some group properties. Most existing DNN testing and verification techniques focus on per image violations and thus fail to detect such group-level confusions or biases. In this paper, we design, implement and evaluate DeepInspect, a white box testing tool, for automatically detecting confusion and bias of DNN-driven image classification applications. We evaluate DeepInspect using popular DNN-based image classifiers and detect hundreds of classification mistakes. Some of these cases are able to expose potential biases of the network towards certain populations. DeepInspect further reports many classification errors in state-of-the-art robust models.
DeepTest: Automated Testing of Deep-Neural-Network-driven Autonomous Cars
Mar 20, 2018

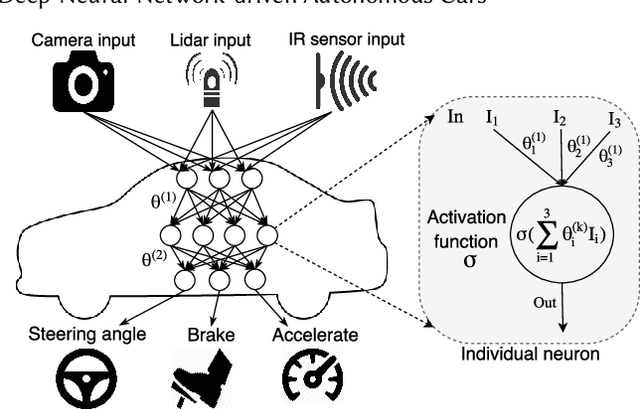
Recent advances in Deep Neural Networks (DNNs) have led to the development of DNN-driven autonomous cars that, using sensors like camera, LiDAR, etc., can drive without any human intervention. Most major manufacturers including Tesla, GM, Ford, BMW, and Waymo/Google are working on building and testing different types of autonomous vehicles. The lawmakers of several US states including California, Texas, and New York have passed new legislation to fast-track the process of testing and deployment of autonomous vehicles on their roads. However, despite their spectacular progress, DNNs, just like traditional software, often demonstrate incorrect or unexpected corner case behaviors that can lead to potentially fatal collisions. Several such real-world accidents involving autonomous cars have already happened including one which resulted in a fatality. Most existing testing techniques for DNN-driven vehicles are heavily dependent on the manual collection of test data under different driving conditions which become prohibitively expensive as the number of test conditions increases. In this paper, we design, implement and evaluate DeepTest, a systematic testing tool for automatically detecting erroneous behaviors of DNN-driven vehicles that can potentially lead to fatal crashes. First, our tool is designed to automatically generated test cases leveraging real-world changes in driving conditions like rain, fog, lighting conditions, etc. DeepTest systematically explores different parts of the DNN logic by generating test inputs that maximize the numbers of activated neurons. DeepTest found thousands of erroneous behaviors under different realistic driving conditions (e.g., blurring, rain, fog, etc.) many of which lead to potentially fatal crashes in three top performing DNNs in the Udacity self-driving car challenge.